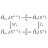使用 Linux 提供的benchmark 工具perf 测试如下
机器 28 个核
-m 每个读线程使用独立的 epfd
-t 读线程的数量
-r 执行 benchmark 的时间(给 2 秒跑的快些,默认 8 秒)
./perf bench epoll wait -m -t 1 -r 2
# Running 'epoll/wait' benchmark:
Run summary [PID 23298]: 1 threads monitoring on 64 file-descriptors for 2 secs.
[thread 0] fdmap: 0x27e0260 ... 0x27e035c [ 525069 ops/sec ]
Averaged 525069 operations/sec (+- 0.00%), total secs = 2
./perf bench epoll wait -m -t 2 -r 2
# Running 'epoll/wait' benchmark:
Run summary [PID 23312]: 2 threads monitoring on 64 file-descriptors for 2 secs.
[thread 0] fdmap: 0x1bec260 ... 0x1bec35c [ 463399 ops/sec ]
[thread 1] fdmap: 0x1bec5f0 ... 0x1bec6ec [ 463392 ops/sec ]
Averaged 463395 operations/sec (+- 0.00%), total secs = 2
./perf bench epoll wait -m -t 4 -r 2
# Running 'epoll/wait' benchmark:
Run summary [PID 23319]: 4 threads monitoring on 64 file-descriptors for 2 secs.
[thread 0] fdmap: 0x22ea260 ... 0x22ea35c [ 208576 ops/sec ]
[thread 1] fdmap: 0x22ea5f0 ... 0x22ea6ec [ 208576 ops/sec ]
[thread 2] fdmap: 0x22ea980 ... 0x22eaa7c [ 208576 ops/sec ]
[thread 3] fdmap: 0x22ead10 ... 0x22eae0c [ 208565 ops/sec ]
Averaged 208573 operations/sec (+- 0.00%), total secs = 2
./perf bench epoll wait -m -t 8 -r 2
# Running 'epoll/wait' benchmark:
Run summary [PID 23328]: 8 threads monitoring on 64 file-descriptors for 2 secs.
[thread 0] fdmap: 0x1832370 ... 0x183246c [ 150848 ops/sec ]
[thread 1] fdmap: 0x1832700 ... 0x18327fc [ 150848 ops/sec ]
[thread 2] fdmap: 0x1832a90 ... 0x1832b8c [ 150848 ops/sec ]
[thread 3] fdmap: 0x1832e20 ... 0x1832f1c [ 150848 ops/sec ]
[thread 4] fdmap: 0x18331b0 ... 0x18332ac [ 150848 ops/sec ]
[thread 5] fdmap: 0x1833540 ... 0x183363c [ 150844 ops/sec ]
[thread 6] fdmap: 0x18338d0 ... 0x18339cc [ 150824 ops/sec ]
[thread 7] fdmap: 0x1833c60 ... 0x1833d5c [ 150816 ops/sec ]
Averaged 150840 operations/sec (+- 0.00%), total secs = 2
可以看到每秒执行的的 epoll_wait 数量在减少,变化的参数是线程数,每个读线程调用 epoll_wait 等待 64 个 fd ,一个写线程向所有读线程的所有 fd 写入数据。然后打印的结果是每个读线程每秒能完成的 epoll_wait 数量
按理说,每个读线程都有独立的 epfd ,线程间没有资源共享,为何吞吐量(每秒执行的 epoll 数量)会下降?