
如图
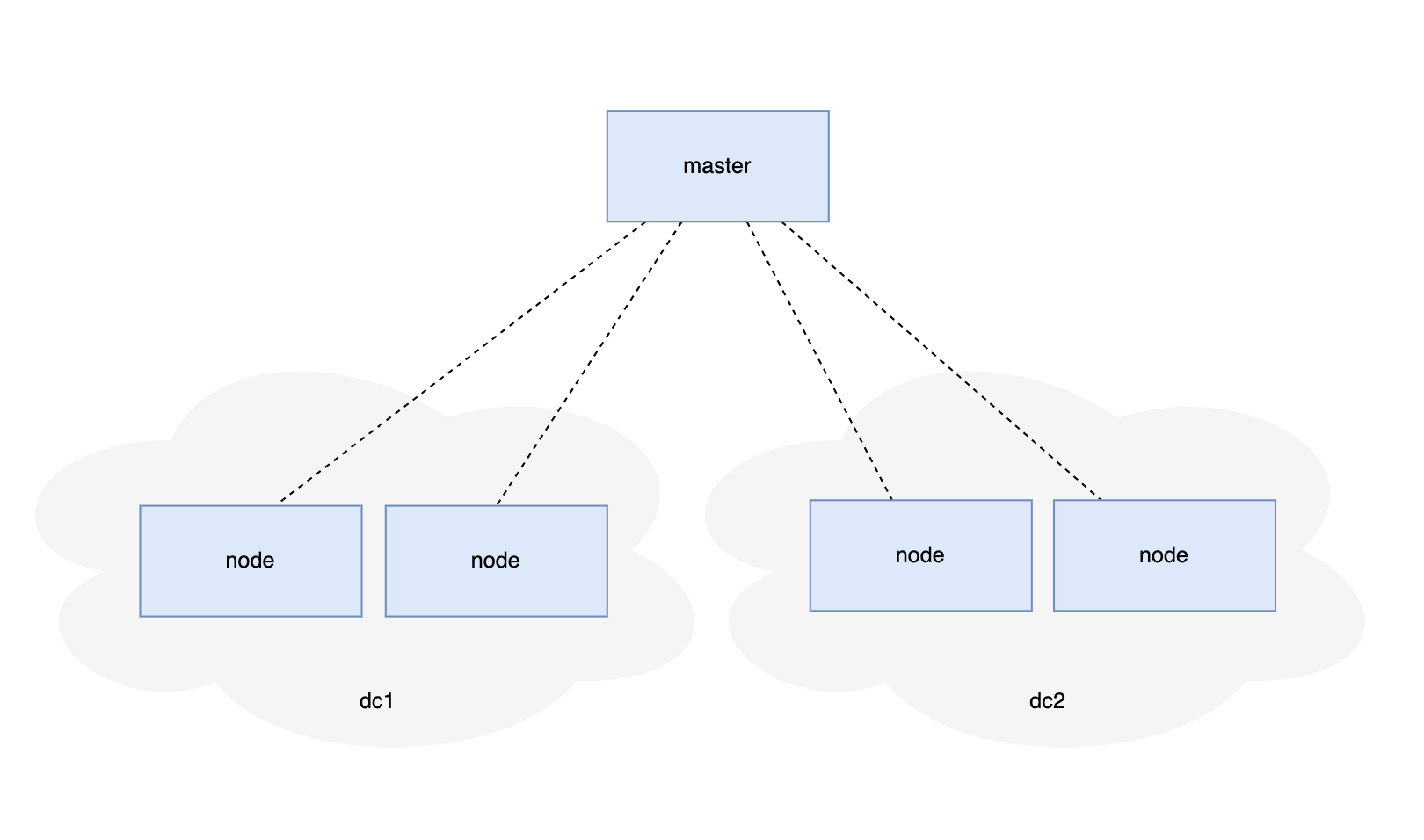
master 要 和 node 之间保持数据同步,数据可能「单向的」也可能是「双向」的。
业务场景数据量 < 100 万
最初的解决方案:
采用 MQ ,master 发布消息,各个 node 订阅消息,做到最终一致性。
如果是反向通信,就 node 发布,master 订阅。
场景:
1 、新加入 node 需要同步全量数据,再同步增量数据,达到最终一致性。
2 、node 可能离线一段时间,之后恢复在线,需要一段时间后达到最终一致性。
这个数据同步过程处理起来比较复杂。
so ,能否使用 etcd/consul 等,整个作为一个集群,用 kv 存储来代替最初的方案,满足上面的场景?





