
本文整理自 TiSpark 项目发起人马晓宇在 Strata Data Conference 上分享的《 When TiDB Meets Spark 》演讲实录。
先介绍我自己,我是 PingCAP 的马晓宇,是 TiDB OLAP 方向的负责人,也是 TiSpark 项目的发起人,主要是做 OLAP 方面的 Feature 和 Product 相关的工作,之前是网易的 Big Data Infra Team Leader,先前的经验差不多都是在 SQL、Hadoop 和所谓大数据相关的一些东西。
今天主要会讲的议程大概这么几项。
首先稍微介绍一下 TiDB 和 TiKV,因为 TiSpark 这个项目是基于它们的,所以你需要知道一下 TiDB 和 TiKV 分别是什么,才能比较好理解我们做的是什么事情。
另外正题是 TiSpark 是什么,然后 TiSpark 的架构,除了 Raw Spark 之外,我们提供了一些什么样的不一样的东西,再然后是 Use Case,最后是项目现在的状态。
首先说什么是 TiDB。你可以认为 TiDB 是现在比较火的 Spanner 的一个开源实现。它具备在线水平扩展、分布式 ACID Transaction、HA、Auto failover 等特性,是一个 NewSQL 数据库。
然后什么是 TiKV,可能我们今天要说很多次了。TiKV 其实是 TiDB 这个产品底下的数据库存储引擎,更形象,更具体一点,这是一个架构图。
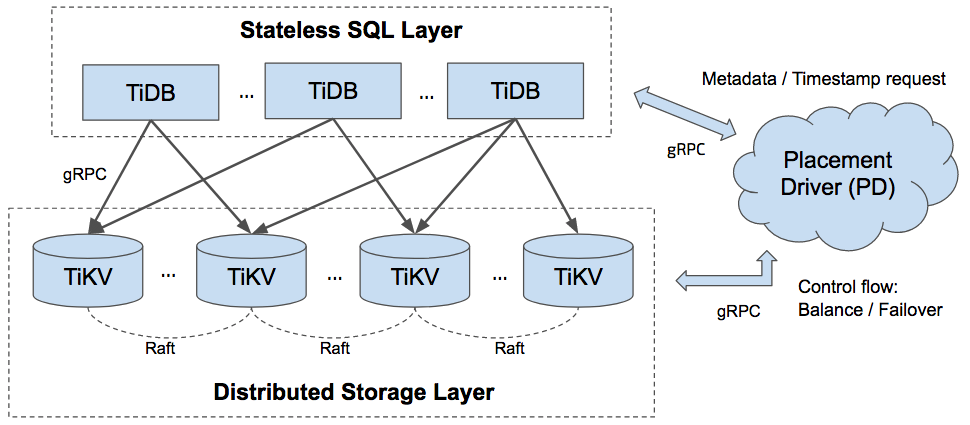
大家可以看到,TiDB 做为一个完整的数据库来说,它是这样的一个架构,上层是 DB 层,DB 层是负责做 DB 相关的东西,比如说一部分的 Transaction,SQL 的解析,然后执行 Query Processing 相关的一些东西。
底下是 KV 层,存储层。存储层就是存储数据,通过 Raft 协议来做 Replica 的,旁边还有 Placement Driver(简称 PD),如果对 Hadoop 比较了解,你可以认为它有点像 NameNode,它会存储每一个 Region 分别存了哪些 Key,然后 Key Range 是什么。当然它在需要的时候也会做一些数据搬迁的调度,以及 Leader 的自动负载均衡等。最后 PD 提供了统一中央授时功能。
所有这些组件,都是通过 gRPC 来进行通讯的。
我们回到正题来说,什么叫 TiSpark。TiSpark 就是 Spark SQL on TiKV。为什么说是 on TiKV,而不是 on TiDB,因为我们让 Spark SQL 直接跑在分布式存储层上而绕过了 TiDB。这三个组件,TiDB / TiKV / TiSpark 一起,作为一个完整的平台,提供了 HTAP ( Hybrid Transactional/Analytical Processing )的功能。
再具体一点说 TiSpark 实现了什么:首先是比较复杂的计算下推,然后 Key Range Pruning,支持索引(因为它底下是一个真正的分布式数据库引擎,所以它可以支持索引),然后一部分的 Cost Based Optimization 基于代价的优化。
CBO 这里有两部分,一部分是说,因为我们有索引,所以在这种情况下,大家知道会面临一个问题,比如说我有十个不同索引,我现在要选择哪一个索引对应我现在这个查询的谓词条件更有利。选择好的索引,会执行比较快,反之会慢。 另外一个是,刚才大家可能有听华为的 Hu Rong 老师介绍,他们在 Spark 上面做 Join Reorder,对于我们来说,也有类似的东西,需要做 Join Reorder。这里底下有两个是 Planned 但还没有做。一个是回写,就是说现在 TiSpark 是一个只读的系统。另外我们考虑把常用的一些传统数据库的优化手段,也搬到我们这边来。
现在开始说一下整个架构是什么样的。后面会有一个具体的解说,先看一下架构图。
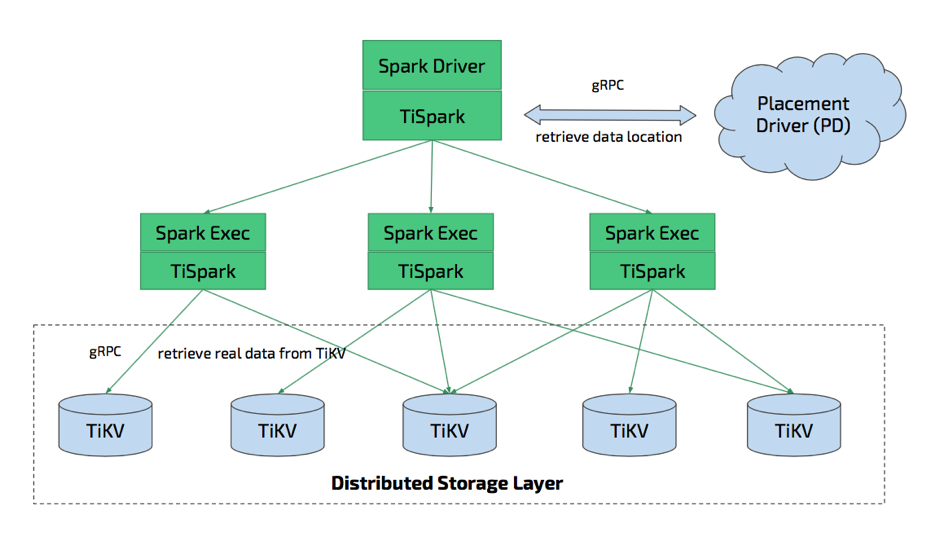
在 Spark Driver 上,需要接入 TiSpark 的接口,现在 TiSpark 也支持 JDBC。Worker / Executor 那边也需要一个这样的架构。 整个部署,采用 Spark 外接 JAR 的方式,并没有说需要到我整个把 Spark 部署全都换掉属于我们的版本,只需要提交一个 JAR 包就可以。每个 TiSpark 组件会与 TiKV 进行通讯,Driver 这边会和 Placement Driver 进行通讯,然后这边具体干了什么,后面会解释。
在 Spark Driver 这边,因为这个架构上没有 TiDB 什么事,所以说 DB 本身干的事情,我们需要再干一遍,比如说 Schema 存在 TiKV 存储引擎里面,然后里面包括 Tables 的元信息,也就是告诉你数据库里面,分别有什么表,每个表里面分别有什么列,这些东西都属于 Schema 信息。因为我们没有直接连接 TiDB,所以说 Schema 信息需要我们自己去解析。
比较重要的功能通过将 Spark SQL 产生的 LogicalPlan,Hook LogicalPlan,然后去做过滤,主要是:
-
哪一些谓词可以转化成索引相关的访问;
-
哪一些可以转化成 Key Range 相关的,还有哪一些其它计算可以下推,这些 Plan 节点我们会先过滤处理一遍。然后把 TiKV 可以算的部分推下去,TiKV 算不了的反推回 Spark ;
-
在基于代价的优化部分 Join Reorder 只是在 Plan 状态;
-
Data Location 是通过 Placement Driver 的交互得到的。Java 这边,会跟 Placement Driver 进行交互,说我要知道的是每个( Task )分别要发哪一台机器,然后分别要知晓哪一块的数据。
之后切分 Partition 的过程就稍微简单一点,按照机器分割区间。之后需要做 Encoding / Decoding:因为还是一样的,抛弃了数据库之后,所有的数据从二进制需要还原成有 Schema 的数据。一个大数据块读上来,我怎么切分 Row,每个 Row 怎么样还原成它对应的数据类型,这个就需要自己来做。
计算下推,我需要把它下推的 Plan 转化成 Coprocessor 可以理解的信息。然后当作 Coprocessor 的一个请求,发送到 Coprocessor,这也是 TiKV-Client 这边做的两个东西。
这些是怎么做的?因为 Spark 提供的两个所谓 Experimental 接口。这两个分别对应的是 Spark Strategy 和 Spark Optimizer,如果做过相关的工作你们可能会知道,你 Hook 了 SQL 引擎的优化器和物理计划生成部分。那两个东西一旦可以改写的话,其实你可以更改数据库的很多很多行为。当然这是有代价的。什么代价?这两个看名字,Experimental Methods,名字提示了什么,也就是在版本和版本之间,比如说 1.6 升到 2.1 不保证里面所有暴露出来的东西都还能工作。可以看到,一个依赖的函数或者类,如果变一些实现,比如说 LogicalPlan 这个类原来是三个参数,现在变成四个参数,那可能就崩了,会有这样的风险。
我们是怎么样做规避的呢?这个项目其实是切成两半的,一半是 TiSpark,另一半是重很多的 TiKV-Client。TiKV Java Client 是负责解析对 TiKV 进行读取和数据解析,谓词处理等等,是一个完整的 TiKV 的独立的 Java 实现的接口。也就是说你有 Java 的系统,你需要操作 TiKV 你可以拿 TiKV Client 去做。底下项目就非常薄,你可以说是主体,就是真的叫 TiSpark 的这个项目,其实也就千多行代码。做的事情就是利用刚才说的两个 Hook 点把 Spark 的 LogicalPlan 导出来,我们自己做一次再变换之后,把剩下的东西交还给 Spark 来做的。这一层非常薄,所以我们不会太担心每个大版本升级的时候,我们需要做很多很多事情,去维护兼容性。
刚才说的有几种可能比较抽象,现在来一个具体的例子,具体看这个东西怎么 Work,可以看一个具体的例子。
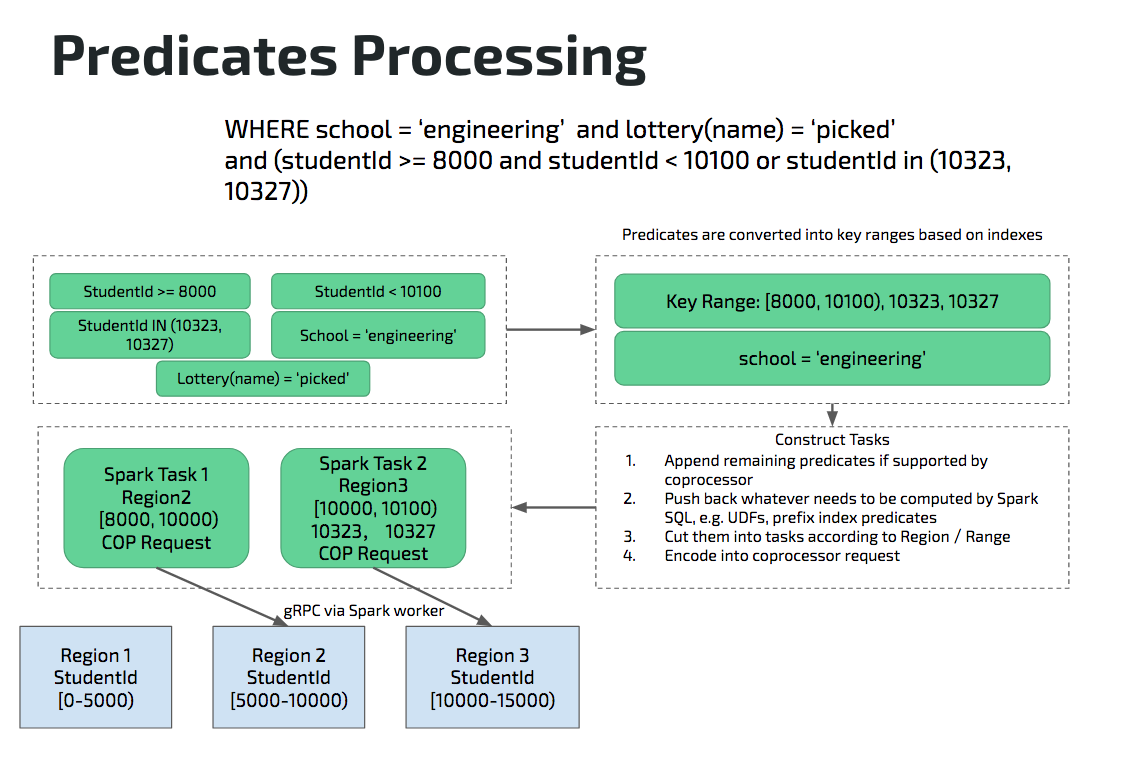
这是一个查询,根据所给的学号和学院等条件计算学生平均值。这张表上,有两个索引,一个索引是主键索引,另外一个索引是在 Secondary Index,建立在 School 上。lottery 是一个用户自定义函数,并不在 TiDB 和 TiKV 的支持范围之内。
首先是说谓词怎么样被处理,这里有几种不同的谓词,比如关于学生 ID 的:大于等于 8000,小于 10100,以及有两个单独学号;然后是一个 school = ‘ engineer ’,还有一个 UDF 叫 lottery,单独挑选一些运气不好的学生。
第一步,整个处理,假设说我们索引选中的是在 studentID 上的聚簇索引。studentID 相关的谓词可以转化为区间 [8000, 10100), 10323, 10327。然后是 school=‘ engineer ’,因为它没有被任何索引选择,所以是一个独立的条件。这两种不同的条件,一个是跟聚簇索引相关的,可以转化成 Key Range,另外一个是跟索引没有关系的独立的谓词。两者会经过不同的处理,聚簇索引相关的谓词转化成 Key Range,独立的谓词 school=‘ engineer ’ 会变成 Coprocessor 的 Reqeust,然后进行 gRPC 的编码,最后把请求发过去。聚簇索引相关谓词转化的 Key Range 会通过查询 Placement Driver 取得 Region 的分布信息,进行相应的区间切割。假设说有三个 Region。Region 1 是 [0, 5000),是一个闭开区间,然后 Region 2 是 [5000, 10000)。接着 Region 3 是 [10000, 15000)。对应我们上面的 Request 下推的区间信息你可以看到,谓词区间对应到两个 Region:Region 2 和 Region 3,Region1 的数据根本不用碰,Region 2 的数据会被切成 [8000, 10000),因为对应的数据区间只有 [8000, 10000)。然后剩下的 [10000, 10100) 会单独放到 Region 3 上面,剩下的就是编码 school=‘ engineering ’ 对应的 Coprocessor Request。最后将编码完成的请求发送到对应的 Region。 上面就是一个谓词处理的逻辑。
多个索引是怎么选择的呢?是通过统计信息。
TiDB 本身是有收集统计信息的,TiSpark 现在正在实现统计信息处理的功能。TiDB 的统计信息是一个等高直方图。例如我们刚才说的两个索引,索引一在 studentId 上,索引二是在 school 上。查询用到了 studentId 和 school 这两个列相关的条件,配合索引,去等高直方图进行估算,直方图可以告诉你,经过谓词过滤大概会有多少条记录返回。假设说使用第一个索引能返回的记录是 1000 条,使用第二个能返回的记录是 800 条,看起来说应该选择 800 条的索引,因为他的选择度可能更好一点。但是实际上,因为聚簇索引访问代价会比较低,因为一次索引访问就能取到数据而 Secondary Index 则需要访问两次才能取到数据,所以实际上,反而可能 1000 条的聚簇索引访问是更好的一个选择。这个只是一个例子,并不是说永远是聚簇索引更好。 然后还有两个优化,一个优化是覆盖索引,也就是说索引是可以建多列的,这个索引不一定是只有 school 这个列,我可以把一个表里面很多列都建成索引,这样有一些查询可以直接用索引本身的信息计算,而不需要回表读取就可以完成。比如,
select count(\*) from student where school=’ engineer ’
整个一条查询就只用到 school 这个列,如果我的索引键就是 school,此外并不需要其他东西。所以我只要读到索引之后,我就可以得到 count(*) 是多少。类似于这样的覆盖索引的东西,也有优化。TiSpark 比较特殊的是,下层接入的是一个完整的数据库而数据库把控了数据入口,我每个 Update 每个 Insert 都可以看到。这给我们带来什么方便,就是说每个更新带来的历史数据变更可以主动收集。
基于代价优化的其他一些功能例如 Join Reorder 还只是计划中,现在并没有实现。刚才有跟 Hu Rong 老师有讨论,暂时 Spark 2.2 所做的 CBO,并不能接入一个外部的统计信息,我们暂时还没想好,这块应该这么样接。 接下来是聚合下推,聚合下推可能稍微特殊一点,因为一般来说,Spark 下面的数据引擎,就是说现在 Spark 的 Data Source API 并不会做聚合下推这种事情。
还是刚才的 SQL 查询:
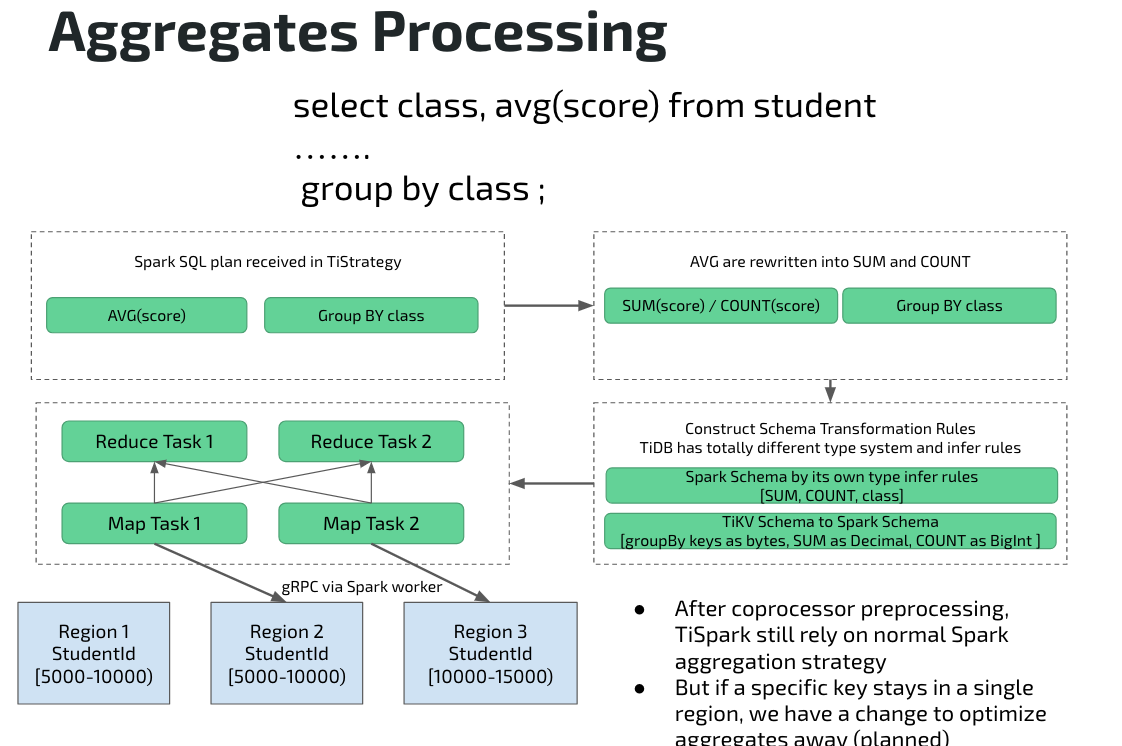
这个例子稍微有一点特殊,因为他是计算平均值,为什么特殊,因为没有办法直接在 TiKV 做 AVG 平均值计算,然后直接在 Spark 再做直接聚合计算,因此这种情况会有一个改写,将 AVG 拆解成 SUM 和 COUNT,然后会把他们分别下推到 Coprocessor,最后在 Spark 继续做聚合计算。
TiSpark 项目除了改写 Plan 之外,还要负责结合做类型转换和 Schema 转换。因为 TiKV 这个项目,本身并不是为了 TiSpark 来设计的,所以整个 Schema 和类型转化的规则都是不一样的。Coprocessor 部分聚合 (Partial Aggregation) 的结果,数据的类型和 Spark 是完全不一样的,因此这边还会做一次 Schema 的桥接。之后其他的就是跟前面一样了,会把请求发到对应的 Region。
现在来讲 TiSpark 和 TiDB / TiKV,因为是整个一个产品的不同组件,所以说 TiSpark 的存储,也就是 TiDB 的存储,TiKV 会针对 TiSpark 这个项目来做一些 OLAP 相关定的 Feature。
比如说在 OLTP 的模式下我们使用的是 SI 隔离级别,就是 Snapshot Isolation。在 OLTP 这边,需要面对一个 Lock Resolving 问题和开销。如果要看的话可以看一下 Percolator Transaction 的论文。为了避免 Lock Resolving 带来的开销,我们使用了一个 Read Committed 的模式。如果需要的话,后面再加 SI 也并不是非常难,只是现在这个版本并不会这样做。
之后还有 OLTP 和 OLAP 混跑,大家可能会觉得有很大问题,就是资源怎么样隔离。现在资源隔离是这样的:对于比较大的查询,在 KV 那层会倾向于用更少的线程。当然是说你如果是在空跑,这台机器上没有其他人在跑的话,其实还是会用所有的资源,但如果你有跟其他 OLTP 查询对比的话,你会发现虽然我是请求了很多但你可能未必会拿到很多。用户也可以手动来降低优先级,例如,我明天就要给老板出一个报表,一个小时候之后就要拿结果,我可以手动提高一个分级。 所有刚刚讲的这些,基本上都是 TiSpark 本身提供了一些什么东西。现在说在一个类似于 Big Picture 的语境之下,怎么样去看这个项目。除了 Raw Spark 的功能之外,我们提供了什么多的东西。最不一样的地方就是 SQL-On-Hadoop,基本上来说,你可以认为它并不控制存储,存储并不在你这里,你灌的数据,可能是通过 Flume/Kafka 某一个 Sink 灌进来,或通过 Sqoop 导过来,整个不管是 Hive,还是 Spark SQL,他并不知道数据进来。对于一个数据库来说,每一条数据插入,全是经过数据库本身的,所以每一条数据怎么样进来,怎么样存,整个这个产品是可以知道的。
另外就是说相对于 SQL-On-Hadoop,我们做一个数据库,肯定会提供 Update 和 Delete 这是不用多说的。因为 TiKV 本身会提供一些额外计算的功能,所以我们可以把一些复杂的查询进行下推。现在只是说了两个,一个是谓词相关的 下推,还有一个是刚才说的聚合下推,其他还有 Order,Limit 这些东西,其实也可以往下放。
接下来就属于脑洞阶段了,除了刚才说的已经“高瞻远瞩”的东西之外,脑洞一下,接下来还可以做一些什么(当然现在还没有做),这个已经是 GA 还要再往后的东西了。
首先说存储,TiKV 的存储是可以给你提供一个全局有序,这可能是跟很多的 SQL-On-Hadoop 的存储是不一样的。Global Order 有什么好处,你可以做 Merge Join,一个 Map Stage 可以做完,而不是要做 Shuffle 和 Sort。Index lookup join 是一个可以尝试去做的。
Improved CBO,我们数据库团队现在正在开发实时收集统计信息。 其他一些传统数据库才可能的优化,我们也可以尝试。这里就不展开多说了。 整个系统,一个展望就是 Spark SQL 下层接数据库存储引擎 TiKV,我可以希望说 Big Data 的那些平台是不是可以和传统的数据库就合在一起。因为本身 TiDB 加 TiKV 就是一个分布式的数据库。然后可以做 Online Transaction,类似于像 Spanner 提供的那些功能之外,我们加上 Spark 之后,是不是可以把一些 Spark 相关的 Workload 也搬上来。
然后是 Use Case:首先一个平台,可以做两种不同的 Workload,Analytical 或者 Transactional 都可以在同一个平台上支持,最大的好处你可以想象:没有 ETL。比如说我现在有一个数据库,我可能通 Sqoop 每小时来同步一次,但是这样有一个延迟。而使用 TiSpark 的话,你查到的数据就是你刚才 Transaction 落地的数据而没有延迟。另外整个东西加在一起的话,就是有一个好处:只需要一套系统。要做数据仓库,或者做一些离线的分析,现在我并不需要把数据从一个平台导入数据分析平台。现在只要一套系统就可以,这样能降低你的维护成本。
另外一个延伸的典型用法是,你可以用 TiDB 作为将多个数据库同步到一起的解决方案。这个方案可以实时接入变更记录,比如 Binlog,实时同步到 TiDB,再使用 TiSpark 做数据分析,也可以用它将 ETL 之后的结果写到 HDFS 数仓进行归档整理。
需要说明的是,由于 TiDB / TiKV 整体是偏重 OLTP,暂时使用的是行存且有一定的事务和版本开销,因此批量读的速度会比 HDFS + 列存如 Parquet 要慢,并不是一个直接替代原本 Hadoop 上基于 Spark SQL / Hive 或者 Impala 这些的数仓解决方案。但是对于大数据场景下,如果你需要一个可变数据的存储,或者需要比较严格的一致性,那么它是一个合适的平台。
后续我们将写一篇文章详细介绍 TiSpark 的 Use Case,对 TiSpark 感兴趣的小伙伴,欢迎发邮件到 [email protected] 与我们交流。
整个这个项目的状态是在 9 月跟整个 TiDB、TiKV 同步做 release。现在的话,刚刚把 TPC-H 跑通的状态,像刚才说的有些 Feature,例如 CBO 那些还没有完全做完。Index 也只是做了 Index 读取,但是说怎么样选 Index 还没有做,正在 Bug fix 以及 Code Cleanup。在 GA 之前会有一个 Beta 大家可以部署了玩一次。目前 TiSpark Beta 已经发布。