
使用 Tesseract 进行 OCR,
样本数据如图所示: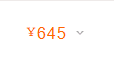
在 JTessBoxEditor 编辑 Box 文件的时候,发现可以正常识别,如下图所示:
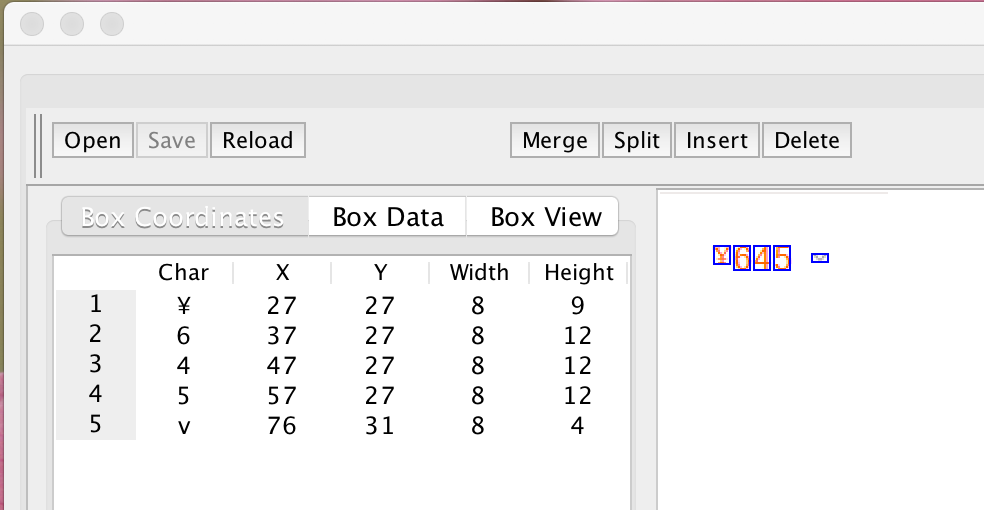
使用 100 张不同的数据进行训练,训练完成以后,生成 num.trainneddata,并使用
tesseract 1.png out -l num
来使用训练数据识别这一张图片,得到的结果确实¥ 845v,数字 6 被识别为 8
请问这是什么 原因,应该如何修正和避免?
使用 Tesseract 进行 OCR,
样本数据如图所示:
在 JTessBoxEditor 编辑 Box 文件的时候,发现可以正常识别,如下图所示:
使用 100 张不同的数据进行训练,训练完成以后,生成 num.trainneddata,并使用
tesseract 1.png out -l num
来使用训练数据识别这一张图片,得到的结果确实¥ 845v,数字 6 被识别为 8
请问这是什么 原因,应该如何修正和避免?
