URL2io.com — 提供简单、强大的网页正文提取服务
今天给大家分享的是一个网页正文提取服务 URL2Article ,主页地址:http://www.url2io.com
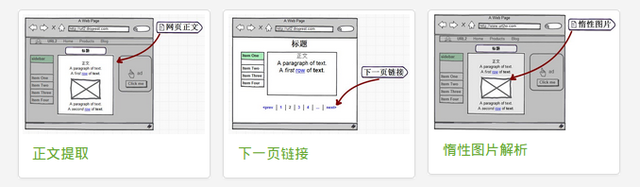
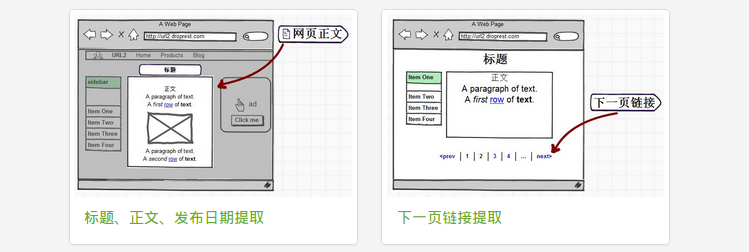
URL2Article 服务提供 RESTful API 接口,用来提取并解析网页中的正文区域,实现网页正文提取、标题提取、发布日期提取、下一页链接提取等。
功能列表
- 标题识别:
不仅仅是简单地提取 title 标签,而是智能识别网页正文的标题。
- 正文识别:
提取的内容将不含有任何广告、导航和其他非正文内容。网页正文中的所有链接、图片和其他媒体将予以保留。
- 发布日期识别:
智能识别文章的发布日期。
- 下一页链接识别:
智能识别当前网页的下一页链接。因为一篇完整的文章会被分成多个页面,所以这个功能会非常有用。
Demo
demo 地址:点这测试效果。
API 使用文档
可以查看相关文档 (URL2Article API doc) 来了解如何使用。
示例应用
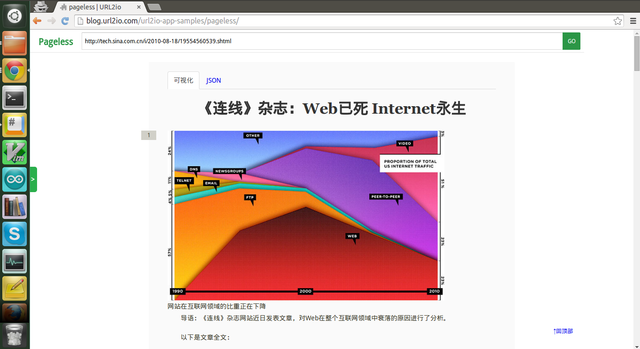
为了让大家近一步了解这项服务,我们写了一个教学示例 Pageless, 它使用 URL2Article API 来提取网页正文,并自动将被分成多页的文章合并成一页。
演示地址, 代码在 Github: url2io-app-samples
Feedback
That's all. 希望有兴趣的童鞋可以试用一下,然后给点反馈(使用中出现的问题、会用来开发什么、意见和建议等都可以)。 欢迎留言讨论,或者 url2#sina.com ,或者 QQ 用户群: 341180183