
Spark 作为一个开源数据处理框架,它在数据计算过程中把中间数据直接缓存到内存里,能大大地提高处理速度,特别是复杂的迭代计算。 Spark 主要包括 SparkSQL , SparkStreaming , Spark MLLib 以及图计算。
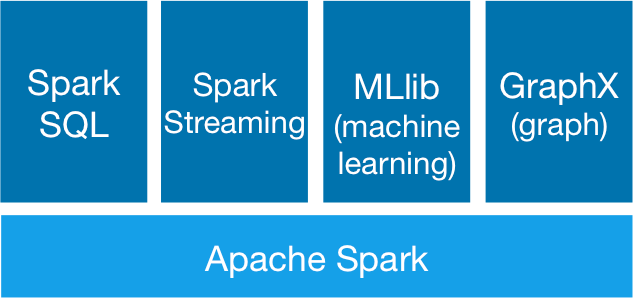
Spark 核心概念简介
1 、 RDD 即弹性分布式数据集,通过 RDD 可以执行各种算子实现数据处理和计算。比如用 Spark 做统计词频,即拿到一串文字进行 WordCount ,可以把这个文字数据 load 到 RDD 之后,调用 map 、 reducebyKey 算子,最后执行 count 动作触发真正的计算。
2 、宽依赖和窄依赖。工厂里面有很多流水线,一款产品上游有一个人操作,下游有人进行第二个操作,窄依赖和这个很类似,下游依赖上游。而所谓宽依赖类似于有多条流水线, A 流水线的一个操作是需要依赖一条流水线 B ,才可以继续执行,要求两条流水线之间要做材料运输,做协调,但效率低。
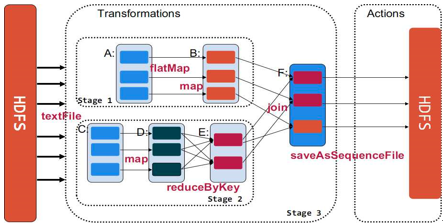
从上图可以看到,如果 B 只依赖 A 则是一种窄依赖。像图中这种 reduceByKey 的操作,就是刚刚举例的宽依赖,类似于多条流水线之间某一些操作相互依赖,如: F 对 E 、 B 的依赖。宽依赖最大的问题是会导致洗牌过程。
Spark Streaming 介绍
流式计算,即数据生成后,实时对数据进行处理。 Spark 是一个批处理框架,那它如何实现流式处理? Spark 是把数据裁成一段一段的处理,即一个数据流离散化成许多个连续批次,然后 Spark 对每个批次进行处理。

个推为什么选择 Spark ?
1 、 Spark 比较适合迭代计算,解决我们团队在之前使用 hadoop mapreduce 迭代数据计算这一块的瓶颈。
2 、 Spark 是一个技术栈,但可以做很多类型的数据处理:批处理, SQL ,流式处理以及 ML 等,基本满足我们团队当时的诉求。
3 、它的 API 抽象层次非常高,通过使用 map 、 reduce 、 groupby 等多种算子可快速实现数据处理,极大降低开发成本,并且灵活。另外 Spark 框架对于多语言支持也是非常好,很多负责数据挖掘算法同学对于 python 熟悉,而工程开发的同学熟悉 java , 多语言支持可以把开发和分析的同学快速地引入过来。
4 、在 2014 年的时候,我们用 hadoop Yarn ,而 Spark 可以在 Yarn 部署起来,使用 Spark 大大降低了切换成本,并且可以把之前的 hadoop 资源利用起来。
5 、 Spark 在社区很火,找资料非常方便。
个推数据处理架构
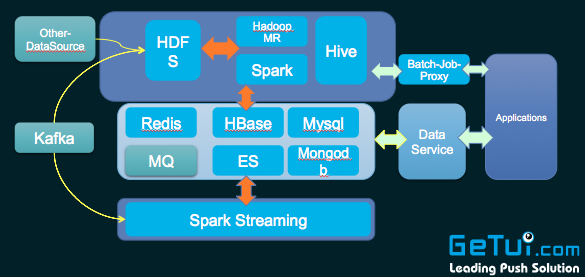
上图是一个典型的 lambda 架构。主要分三层。上面蓝色的框,是做离线批量处理,下面一层是实时数据处理这一块,中间这一层是对于结果数据做一些存储和检索。
有两种方式导入数据到 HDFS ,一部分数据从业务平台日志收集写入到 Kafka ,然后直接 Linkedin Camus (我们做过扩展) 准实时地传输到 HDFS ,另外部分数通过运维那边的脚本定时导入到 HDFS 上。
离线处理部分我们还是使用两个方式( Hadoop MR 和 Spark )。原有的 hadoop MR 没有放弃掉, 因为原来很多的工程已经是用 MR 做的了,非常稳定,没有必要推倒重来,只有部分迭代任务使用 Spark 重新实现。另外 Hive 是直接可以跟 Spark 做结合, Spark Sql 中就可以使用 Hive 的命令。
个推 Spark 集群的部署状况
个推最开始用 Spark 是 1.3.1 版本,用的是刀片服务器,就是刀框里面可以塞 16 个刀片服务器,单个内存大小 192G , CPU 核数是 24 核的。在 Spark 官方也推荐用万兆网卡,大内存设备。我们权衡了需求和成本后,选择了就用刀片机器来搭建 Spark 集群。刀框有个好处就是通过背板把刀片机器连接起来,传输速度快,相对成本小。部署模式上采用的是 Spark on Yarn ,实现资源复用。
Spark 在个推业务上的具体使用现状
1 、个推做用户画像、模型迭代以及一些推荐的时候直接用了 MLLib , MLLib 集成了很多算法,非常方便。
2 、个推有一个 BI 工具箱,让一些运营人员提取数据,我们是用 Spark SQL+Parquet 格式宽表实现, Parquet 是列式存储格式,使用它你不用加载整个表,只会去加载关心那些字段,大大减少 IO 消耗。
3 、实时统计分析这块:例如个推有款产品叫个图,就是使用 Spark streaming 来实时统计。
4 、复杂的 ETL 任务我们也使用 Spark 。例如:我们个推推送报表这一块,每天需要做很多维度的推送报表统计。使用 Spark 通过 cache 中间结果缓存,然后再统计其他维度,大大地减少了 I/O 消耗,显著地提升了统计处理速度。
个推 Spark 实践案例分享
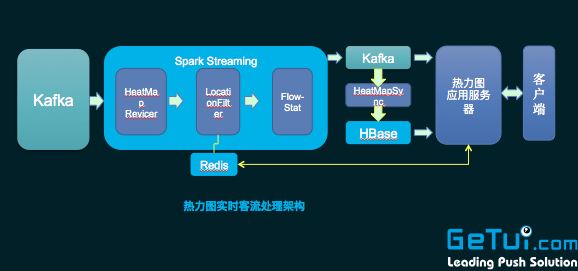
上图是个推热力图的处理架构。左边这一侧利用业务平台得到设备的实时位置数据,通过 Spark Streaming 以及计算得到每一个 geohash 格子上的人数,然后统计结果实时传输给业务服务层,在 push 到客户端地图上面去渲染,最终形成一个实时热力图。 Spark Streaming 主要用于数据实时统计处理上。
个推教你绕过开发那些坑
1 、数据处理经常出现数据倾斜,导致负载不均衡的问题,需要做统计分析找到倾斜数据特征,定散列策略。
2 、使用 Parquet 列式存储,减少 IO ,提高 Spark SQL 效率。
3 、实时处理方面:一方面要注意数据源( Kafka ) topic 需要多个 partition ,并且数据要散列均匀,使得 Spark Streaming 的 Recevier 能够多个并行,并且均衡地消费数据 。使用 Spark Streaming ,要多通过 Spark History 排查 DStream 的操作中哪些处理慢,然后进行优化。另外一方面我们自己还做了实时处理的监控系统,用来监控处理情况如流 入、流出数据速度等。通过监控系统报警,能够方便地运维 Spark Streaming 实时处理程序。这个小监控系统主要用了 influxdb+grafana 等实现。
4 、我们测试网经常出现找不到第三方 jar 的情况,如果是用 CDH 的同学一般会遇到,就是在 CDH 5.4 开始, CDH 的技术支持人员说他们去掉了 hbase 等一些 jar ,他们认那些 jar 已经不需要耦合在自己的 classpath 中,这个情况可以通过 spark.executor.extraClassPath 方式添加进来。
5 、一些新入门的人会遇到搞不清 transform 和 action ,没有明白 transform 是 lazy 的,需要 action 触发,并且两个 action 前后调用效果可能不一样。
6 、大家使用过程当中,对需要重复使用的 RDD ,一定要做 cache ,性能提升会很明显。
以上内容根据个推讲师袁凯在 11 月 28 号 Segmentfault 北京 D-Day 沙龙的分享整理,希望给广大开发者一些启示。小伙伴们记得将 get 到的干货顺手分享给身边的同学们哦~

Spark 核心概念简介
1 、 RDD 即弹性分布式数据集,通过 RDD 可以执行各种算子实现数据处理和计算。比如用 Spark 做统计词频,即拿到一串文字进行 WordCount ,可以把这个文字数据 load 到 RDD 之后,调用 map 、 reducebyKey 算子,最后执行 count 动作触发真正的计算。
2 、宽依赖和窄依赖。工厂里面有很多流水线,一款产品上游有一个人操作,下游有人进行第二个操作,窄依赖和这个很类似,下游依赖上游。而所谓宽依赖类似于有多条流水线, A 流水线的一个操作是需要依赖一条流水线 B ,才可以继续执行,要求两条流水线之间要做材料运输,做协调,但效率低。

从上图可以看到,如果 B 只依赖 A 则是一种窄依赖。像图中这种 reduceByKey 的操作,就是刚刚举例的宽依赖,类似于多条流水线之间某一些操作相互依赖,如: F 对 E 、 B 的依赖。宽依赖最大的问题是会导致洗牌过程。
Spark Streaming 介绍
流式计算,即数据生成后,实时对数据进行处理。 Spark 是一个批处理框架,那它如何实现流式处理? Spark 是把数据裁成一段一段的处理,即一个数据流离散化成许多个连续批次,然后 Spark 对每个批次进行处理。

个推为什么选择 Spark ?
1 、 Spark 比较适合迭代计算,解决我们团队在之前使用 hadoop mapreduce 迭代数据计算这一块的瓶颈。
2 、 Spark 是一个技术栈,但可以做很多类型的数据处理:批处理, SQL ,流式处理以及 ML 等,基本满足我们团队当时的诉求。
3 、它的 API 抽象层次非常高,通过使用 map 、 reduce 、 groupby 等多种算子可快速实现数据处理,极大降低开发成本,并且灵活。另外 Spark 框架对于多语言支持也是非常好,很多负责数据挖掘算法同学对于 python 熟悉,而工程开发的同学熟悉 java , 多语言支持可以把开发和分析的同学快速地引入过来。
4 、在 2014 年的时候,我们用 hadoop Yarn ,而 Spark 可以在 Yarn 部署起来,使用 Spark 大大降低了切换成本,并且可以把之前的 hadoop 资源利用起来。
5 、 Spark 在社区很火,找资料非常方便。
个推数据处理架构

上图是一个典型的 lambda 架构。主要分三层。上面蓝色的框,是做离线批量处理,下面一层是实时数据处理这一块,中间这一层是对于结果数据做一些存储和检索。
有两种方式导入数据到 HDFS ,一部分数据从业务平台日志收集写入到 Kafka ,然后直接 Linkedin Camus (我们做过扩展) 准实时地传输到 HDFS ,另外部分数通过运维那边的脚本定时导入到 HDFS 上。
离线处理部分我们还是使用两个方式( Hadoop MR 和 Spark )。原有的 hadoop MR 没有放弃掉, 因为原来很多的工程已经是用 MR 做的了,非常稳定,没有必要推倒重来,只有部分迭代任务使用 Spark 重新实现。另外 Hive 是直接可以跟 Spark 做结合, Spark Sql 中就可以使用 Hive 的命令。
个推 Spark 集群的部署状况
个推最开始用 Spark 是 1.3.1 版本,用的是刀片服务器,就是刀框里面可以塞 16 个刀片服务器,单个内存大小 192G , CPU 核数是 24 核的。在 Spark 官方也推荐用万兆网卡,大内存设备。我们权衡了需求和成本后,选择了就用刀片机器来搭建 Spark 集群。刀框有个好处就是通过背板把刀片机器连接起来,传输速度快,相对成本小。部署模式上采用的是 Spark on Yarn ,实现资源复用。
Spark 在个推业务上的具体使用现状
1 、个推做用户画像、模型迭代以及一些推荐的时候直接用了 MLLib , MLLib 集成了很多算法,非常方便。
2 、个推有一个 BI 工具箱,让一些运营人员提取数据,我们是用 Spark SQL+Parquet 格式宽表实现, Parquet 是列式存储格式,使用它你不用加载整个表,只会去加载关心那些字段,大大减少 IO 消耗。
3 、实时统计分析这块:例如个推有款产品叫个图,就是使用 Spark streaming 来实时统计。
4 、复杂的 ETL 任务我们也使用 Spark 。例如:我们个推推送报表这一块,每天需要做很多维度的推送报表统计。使用 Spark 通过 cache 中间结果缓存,然后再统计其他维度,大大地减少了 I/O 消耗,显著地提升了统计处理速度。
个推 Spark 实践案例分享

上图是个推热力图的处理架构。左边这一侧利用业务平台得到设备的实时位置数据,通过 Spark Streaming 以及计算得到每一个 geohash 格子上的人数,然后统计结果实时传输给业务服务层,在 push 到客户端地图上面去渲染,最终形成一个实时热力图。 Spark Streaming 主要用于数据实时统计处理上。
个推教你绕过开发那些坑
1 、数据处理经常出现数据倾斜,导致负载不均衡的问题,需要做统计分析找到倾斜数据特征,定散列策略。
2 、使用 Parquet 列式存储,减少 IO ,提高 Spark SQL 效率。
3 、实时处理方面:一方面要注意数据源( Kafka ) topic 需要多个 partition ,并且数据要散列均匀,使得 Spark Streaming 的 Recevier 能够多个并行,并且均衡地消费数据 。使用 Spark Streaming ,要多通过 Spark History 排查 DStream 的操作中哪些处理慢,然后进行优化。另外一方面我们自己还做了实时处理的监控系统,用来监控处理情况如流 入、流出数据速度等。通过监控系统报警,能够方便地运维 Spark Streaming 实时处理程序。这个小监控系统主要用了 influxdb+grafana 等实现。
4 、我们测试网经常出现找不到第三方 jar 的情况,如果是用 CDH 的同学一般会遇到,就是在 CDH 5.4 开始, CDH 的技术支持人员说他们去掉了 hbase 等一些 jar ,他们认那些 jar 已经不需要耦合在自己的 classpath 中,这个情况可以通过 spark.executor.extraClassPath 方式添加进来。
5 、一些新入门的人会遇到搞不清 transform 和 action ,没有明白 transform 是 lazy 的,需要 action 触发,并且两个 action 前后调用效果可能不一样。
6 、大家使用过程当中,对需要重复使用的 RDD ,一定要做 cache ,性能提升会很明显。
以上内容根据个推讲师袁凯在 11 月 28 号 Segmentfault 北京 D-Day 沙龙的分享整理,希望给广大开发者一些启示。小伙伴们记得将 get 到的干货顺手分享给身边的同学们哦~





