
0. 太长不读
今天这篇文章源于最近半年深度使用 Claude Code 、两个账号每月 40 刀氪金换来的一些踩坑经验,希望能给大伙一些输入。
刚开始我也把它当 ChatBot 用,后来很快发现不对劲:上下文越来越乱、工具越来越多但效果越来越差、规则越写越长却越不遵守,折腾了一段时间,研究了 Claude Code 本身之后才意识到,这不是 Prompt 问题,而是这套系统的设计就是这样的。
这篇文章想和大伙聊聊这几个事:Claude Code 底层怎么运作、上下文为什么会乱以及怎么治理、Skills 和 Hooks 应该怎么设计、Subagents 的正确用法、Prompt Caching 的架构影响,以及怎么写一个真正有用的 CLAUDE.md 。
我觉得最直接的理解方式,是把 Claude Code 拆成六层来看:
| 层 | 职责 |
|---|---|
CLAUDE.md / rules / memory |
长期上下文,告诉 Claude "是什么" |
Tools / MCP |
动作能力,告诉 Claude "能做什么" |
Skills |
按需加载的方法论,告诉 Claude "怎么做" |
Hooks |
强制执行某些行为,不依赖 Claude 自己判断 |
Subagents |
隔离上下文的工作者,负责受控自治 |
Verifiers |
验证闭环,让输出可验、可回滚、可审计 |
只强化其中一层,系统就会失衡,CLAUDE.md 写太长,上下文先污染自己了;工具堆太多了,选择就搞不清楚了; subagents 开得到处都是,状态就漂移了;验证这步跳过了,出了问题根本不知道是哪里挂的。
1. 它底层是怎么运行的

Claude Code 的核心不是"回答",而是一个反复循环的代理过程:
收集上下文 → 采取行动 → 验证结果 → [完成 or 回到收集]
↑ ↓
CLAUDE.md Hooks / 权限 / 沙箱
Skills Tools / MCP
Memory
用了一段时间才意识到,卡住的地方几乎从来不是模型不够聪明,更多时候是给了它错误的上下文,或者写出来了但根本没法判断对不对,也没法撤回。
真正要关注的五个层面
| 层面 | 核心问题 | 主要载体 |
|---|---|---|
Context surface |
哪些信息常驻,哪些按需加载 | CLAUDE.md、rules 、memory 、skills |
Action surface |
Claude 当前具备哪些动作能力 | built-in tools 、MCP 、plugins |
Control surface |
哪些动作必须被约束、阻断或审计 | permissions 、sandbox 、hooks |
Isolation surface |
哪些任务需要隔离上下文和权限 | subagents 、worktrees 、forked sessions |
Verification surface |
如何判断任务完成且结果可信 | tests 、lint 、screenshots 、logs 、CI |
对着这几个面看,很多问题就好排查了。结果不稳定,查上下文加载顺序,不是模型的事;自动化失控,看控制层有没有设计,不是 agent 太主动;长会话质量下降,中间产物把上下文污染了,换个新会话比反复调 prompt 有用得多。
2. 概念边界:MCP / Plugin / Tools / Skills / Hooks / Subagents
| 概念 | 运行时角色 | 解决什么 | 典型误用 |
|---|---|---|---|
CLAUDE.md |
项目级持久契约 | 每次会话都必须成立的命令、边界、禁止项 | 写成团队知识库 |
.claude/rules/* |
路径或语言相关规则 | 目录、文件类型或语言级局部规范 | 所有规则都堆到根 CLAUDE.md |
Built-in Tools |
内置能力 | 读文件、改文件、跑命令、搜索 | 把所有集成都塞进 shell |
MCP |
外部能力接入协议 | 让 Claude 访问 GitHub 、Sentry 、数据库 | 接太多 server ,工具定义挤爆上下文 |
Plugin |
打包分发层 | 把 Skills/Hooks/MCP 一起分发 | 把 plugin 当成运行时 primitive |
Skill |
按需加载的知识/工作流 | 给 Claude 一个"方法包" | skill 既像百科全书又像部署脚本 |
Hook |
强制执行规则的拦截层 | 在生命周期事件前后执行规则 | 用 hook 替代所有模型判断 |
Subagent |
隔离上下文的工作单元 | 并行研究、限制工具与权限 | 无边界 fan-out ,治理失控 |
简单记:给 Claude 新动作能力用 Tool/MCP ,给它一套工作方法用 Skill ,需要隔离执行环境用 Subagent ,要强制约束和审计用 Hook ,跨项目分发用 Plugin 。
3. 上下文工程:最重要的系统约束
很多人把上下文当"容量问题",但卡住的地方通常不是不够长,而是太吵了,有用的信息被大量无关内容淹没了。
真实的上下文成本构成

Claude Code 的 200K 上下文并非全部可用:
200K 总上下文
├── 固定开销 (~15-20K)
│ ├── 系统指令: ~2K
│ ├── 所有启用的 Skill 描述符: ~1-5K
│ ├── MCP Server 工具定义: ~10-20K ← 最大隐形杀手
│ └── LSP 状态: ~2-5K
│
├── 半固定 (~5-10K)
│ ├── CLAUDE.md: ~2-5K
│ └── Memory: ~1-2K
│
└── 动态可用 (~160-180K)
├── 对话历史
├── 文件内容
└── 工具调用结果

一个典型 MCP Server (如 GitHub )包含 20-30 个工具定义,每个约 200 tokens ,合计 4,000-6,000 tokens。接 5 个 Server ,光这部分固定开销就到了 25,000 tokens ( 12.5%)。我第一次算出这个数字的时候,真没想到有这么多,在要读大量代码的场景,这 12.5% 真的很关键。
推荐的上下文分层
始终常驻 → CLAUDE.md:项目契约 / 构建命令 / 禁止事项
按路径加载 → rules:语言 / 目录 / 文件类型特定规则
按需加载 → Skills:工作流 / 领域知识
隔离加载 → Subagents:大量探索 / 并行研究
不进上下文 → Hooks:确定性脚本 / 审计 / 阻断
说白了,偶尔用的东西就不要每次都加载进来。
上下文最佳实践
- 保持
CLAUDE.md短、硬、可执行,优先写命令、约束、架构边界。Anthropic 官方自己的 CLAUDE.md 大约只有 2.5K tokens ,可以参考 - 把大型参考文档拆到 Skills 的 supporting files ,不要塞进 SKILL.md 正文
- 使用
.claude/rules/做路径/语言规则,不让根CLAUDE.md承担所有差异 - 长会话主动用
/context观察消耗,不要等系统自动压缩后再补救
- 任务切换优先
/clear,同一任务进入新阶段用/compact - 把 Compact Instructions 写进 CLAUDE.md,压缩后必须保留什么由你控制,不由算法猜
Tool Output 噪声:另一个隐形上下文杀手
前面算的是 MCP 工具定义的固定开销,但动态部分同样有个坑容易被忽视:Tool Output 。cargo test 一次完整输出动辄几千行,git log、find、grep 在稍大的仓库里也能轻松塞满屏幕。这些输出 Claude 并不需要全看,但只要它出现在上下文里,就是实实在在的 token 消耗,同样会挤掉对话历史和文件内容的空间。
后来看到 RTK ( Rust Token Killer ) 这个思路觉得挺对的,它做的事很简单:在命令输出到 Claude 之前自动过滤,只留决策需要的核心信息。比如 cargo test:
# Claude 看到的原始输出
running 262 tests
test auth::test_login ... ok
...(几千行)
# 走 RTK 之后
✓ cargo test: 262 passed (1 suite, 0.08s)
Claude 真正需要知道的就是「过了还是挂了,挂在哪里」,其他都是噪声。它通过 Hook 透明重写命令,对 Claude Code 来说完全无感。
后面第 6 节会提到 | head -30 这种手动截断,RTK 干的就是这件事,只是覆盖面更广,不用每条命令自己加。项目 开源在 GitHub。
压缩机制的陷阱

默认压缩算法按"可重新读取"判断,早期的 Tool Output 和文件内容会被优先删掉,顺带把架构决策和约束理由也一起扔了。两小时后再改,可能根本不记得两小时前定了什么,莫名其妙的 Bug 就是这么来的。
解决方案就是在 CLAUDE.md 里写明:
## Compact Instructions
When compressing, preserve in priority order:
1. Architecture decisions (NEVER summarize)
2. Modified files and their key changes
3. Current verification status (pass/fail)
4. Open TODOs and rollback notes
5. Tool outputs (can delete, keep pass/fail only)
除了写 Compact Instructions ,还有一种更主动的方案:在开新会话前,先让 Claude 写一份 HANDOFF.md ,把当前进度、尝试过什么、哪些走通了、哪些是死路、下一步该做什么写清楚。下一个 Claude 实例只读这个文件就能接着做,不依赖压缩算法的摘要质量:
在 HANDOFF.md 里写清楚现在的进展。解释你试了什么、什么有效、什么没用,让下一个拿到新鲜上下文的 agent 只看这个文件就能继续完成任务。
写完后快速扫一眼,有缺漏直接让它补,然后开新会话,把 HANDOFF.md 的路径发过去就行。
Plan Mode 的工程价值
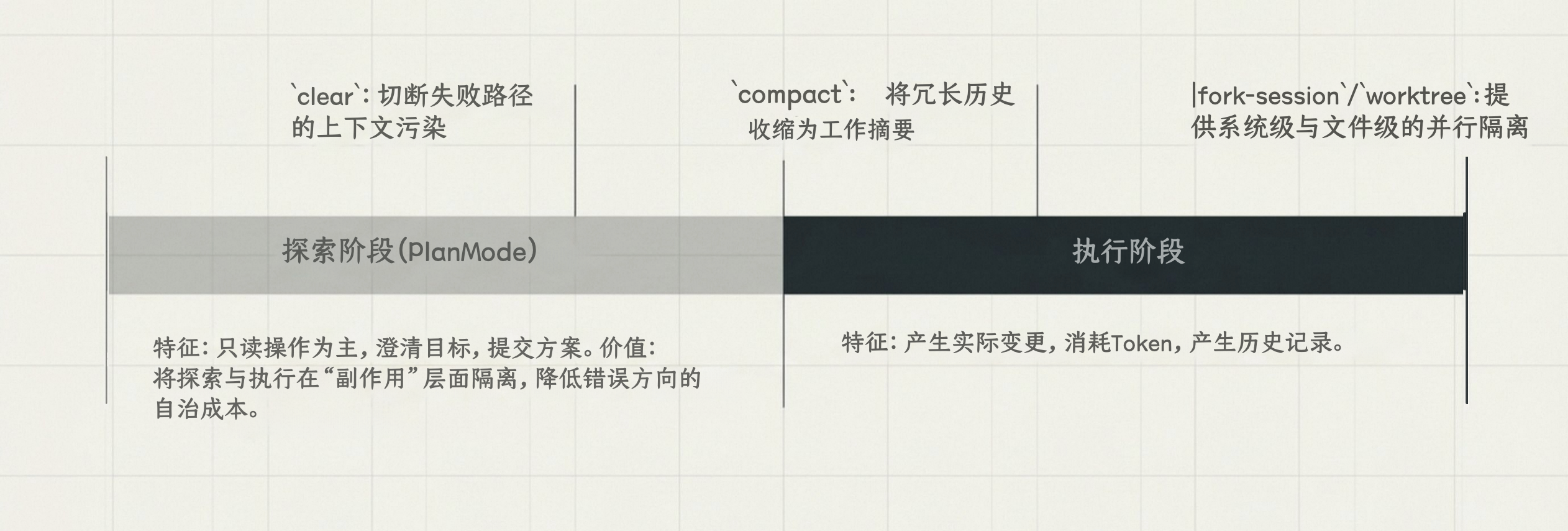
Plan Mode 的核心是把探索和执行拆开,探索阶段不动文件,确认方案后再执行:
- 探索阶段以只读操作为主
- Claude 可以先澄清目标和边界,再提交具体方案
- 执行成本在计划确认之后才发生

对于复杂重构、迁移、跨模块改动,这样做比"急着出代码"有用多了,在错误假设上越跑越偏的情况会少很多。按两下 Shift+Tab 进入 Plan Mode ,进阶玩法是开一个 Claude 写计划,再开一个 Codex 以"高级工程师"身份审这个计划,让 AI 审 AI ,效果很好。
4. Skills 设计:不是模板库,是用的时候才加载的工作流
Skill 官方描述是"按需加载的知识与工作流",描述符常驻上下文,完整内容按需加载,用起来和"保存的 Prompt"差别挺大的。
一个好 Skill 应该满足什么
- 描述要让模型知道"何时该用我",而不是"我是干什么的",这两个差很多
- 有完整步骤、输入、输出和停止条件,别写了个开头没有结尾
- 正文只放导航和核心约束,大资料拆到 supporting files 里
- 有副作用的 Skill 要显式设置
disable-model-invocation: true,不然 Claude 会自己决定要不要跑
Skill 怎么做到"按需加载"
Claude Code 团队在内部设计中反复强调 "progressive disclosure",意思不是让模型一次性看到所有信息,而是先获得索引和导航,再按需拉取细节:
SKILL.md负责定义任务语义、边界和执行骨架- supporting files 负责提供领域细节
- 脚本负责确定性收集上下文或证据
一个比较稳定的结构长这样:
.claude/skills/
└── incident-triage/
├── SKILL.md
├── runbook.md
├── examples.md
└── scripts/
└── collect-context.sh
Skill 的三种典型类型
下面几个例子都来自我在开源 terminal 项目 Kaku 里的实际 Skill ,比较直观。
类型一:检查清单型(质量门禁)
发布前跑一遍,确保不漏项:
---
name: release-check
description: Use before cutting a release to verify build, version, and smoke test.
---
## Pre-flight (All must pass)
- [ ] `cargo build --release` passes
- [ ] `cargo clippy -- -D warnings` clean
- [ ] Version bumped in Cargo.toml
- [ ] CHANGELOG updated
- [ ] `kaku doctor` passes on clean env
## Output
Pass / Fail per item. Any Fail must be fixed before release.
类型二:工作流型(标准化操作)
配置迁移高风险,显式调用 + 内置回滚步骤:
---
name: config-migration
description: Migrate config schema. Run only when explicitly requested.
disable-model-invocation: true
---
## Steps
1. Backup: `cp ~/.config/kaku/config.toml ~/.config/kaku/config.toml.bak`
2. Dry run: `kaku config migrate --dry-run`
3. Apply: remove `--dry-run` after confirming output
4. Verify: `kaku doctor` all pass
## Rollback
`cp ~/.config/kaku/config.toml.bak ~/.config/kaku/config.toml`
类型三:领域专家型(封装决策框架)
运行时出问题时让 Claude 按固定路径收集证据,不要瞎猜:
---
name: runtime-diagnosis
description: Use when kaku crashes, hangs, or behaves unexpectedly at runtime.
---
## Evidence Collection
1. Run `kaku doctor` and capture full output
2. Last 50 lines of `~/.local/share/kaku/logs/`
3. Plugin state: `kaku --list-plugins`
## Decision Matrix
| Symptom | First Check |
|---|---|
| Crash on startup | doctor output → Lua syntax error |
| Rendering glitch | GPU backend / terminal capability |
| Config not applied | Config path + schema version |
## Output Format
Root cause / Blast radius / Fix steps / Verification command
描述符写短点,每个 Skill 都在偷你的上下文空间
每个启用的 Skill ,描述符常驻上下文。优化前后差距很大:
# 低效(~45 tokens )
description: |
This skill helps you review code changes in Rust projects.
It checks for common issues like unsafe code, error handling...
Use this when you want to ensure code quality before merging.
# 高效(~9 tokens )
description: Use for PR reviews with focus on correctness.
还有一个很重要的 disable-auto-invoke 使用策略:
- 高频(>1 次/会话)→ 保持 auto-invoke ,优化描述符
- 低频(<1 次/会话)→ disable-auto-invoke ,手动触发,描述符完全脱离上下文
- 极低频(<1 次/月)→ 移除 Skill ,改为 AGENTS.md 中的文档
Skills 反模式
- 描述过短:
description: help with backend(任何后端工作都能触发,哈哈) - 正文过长:几百行工作手册全塞进 SKILL.md 正文
- 一个 Skill 覆盖 review 、deploy 、debug 、docs 、incident 五件事
- 有副作用的 Skill 允许模型自动调用
5. 工具设计:怎么让 Claude 少选错
我后面越用越觉得,给 Claude 的工具和给人写的 API 不是一回事。给人用的 API 往往会追求功能齐全,但给 agent 用,重点不是功能堆得多完整,而是让它更容易用对。
好工具 vs 坏工具
| 维度 | 好工具 | 坏工具 |
|---|---|---|
| 名称 | jira_issue_get, sentry_errors_search |
query, fetch, do_action |
| 参数 | issue_key, project_id, response_format |
id, name, target |
| 返回 | 与下一步决策直接相关的信息 | 一堆 UUID 、内部字段、原始噪声 |
| 规模 | 单一目标,边界清楚 | 多个动作混杂,副作用不透明 |
| 成本 | 默认输出受控、可截断 | 默认返回过大上下文 |
| 错误信息 | 包含修正建议 | 仅返回 opaque error code |
几个实用设计原则:
- 名称前缀按系统或资源分层:
github_pr_*、jira_issue_* - 对大响应支持
response_format: concise / detailed - 错误响应要教模型如何修正,不要只抛 opaque error code
- 能合并成高层任务工具时,不要暴露过多底层碎片工具,避免
list_all_*让模型自行筛选
从 Claude Code 内部工具演进学到的
我看到 Claude Code 团队内部工具的这段演进时,感觉还挺有意思。像这种需要在任务中途停下来问用户的场景,他们前后试了三种做法:
- 第一版:给已有工具(如 Bash )加一个
question参数,让 Claude 在调用工具时顺带提问。结果 Claude 大多数时候直接忽略这个参数,继续往下跑,根本不停下来问。 - 第二版:要求 Claude 在输出里写特定 markdown 格式,外层解析到这个格式就暂停。问题是没有强制约束,Claude 经常"忘了"按格式写,提问逻辑非常脆弱。
- 第三版:做成独立的
AskUserQuestion工具。Claude 想提问就必须显式调用它,调用即暂停,没有歧义。比前两版靠谱多了。
下面这张图刚好能解释,为什么第三版明显更稳:
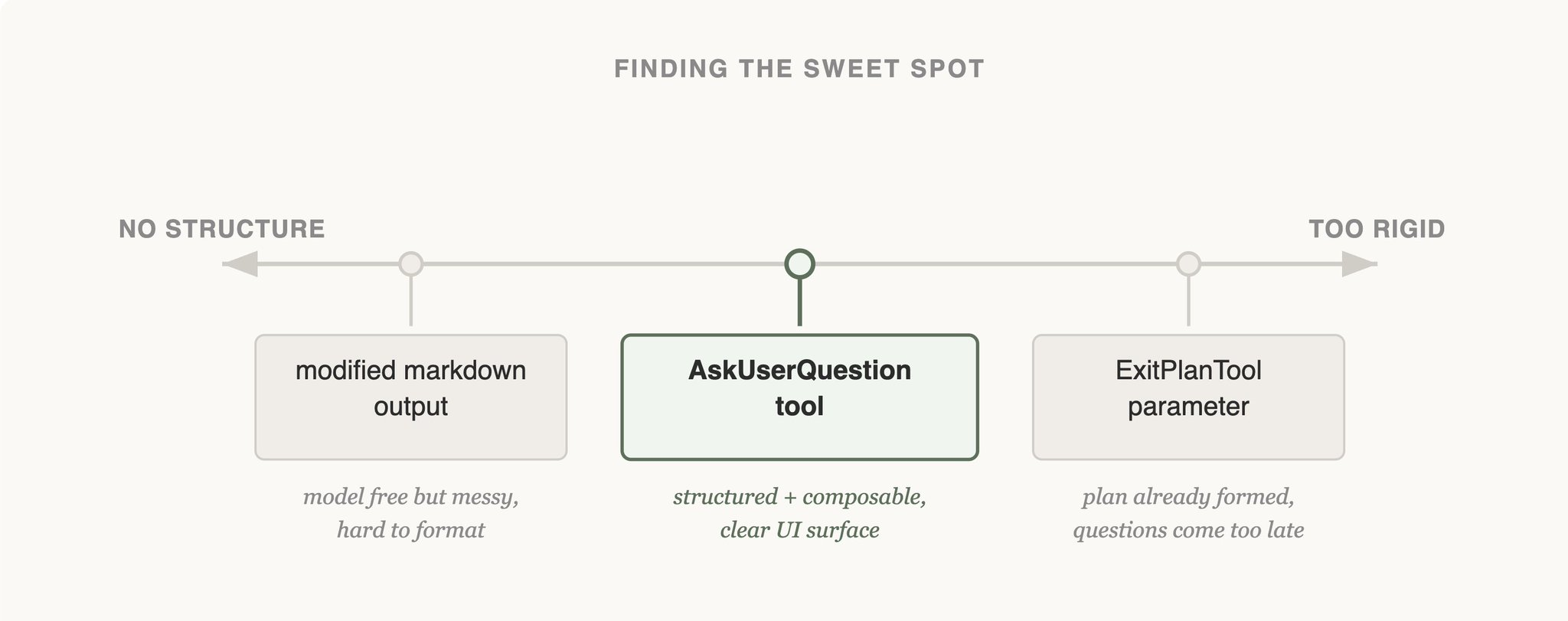
左边( markdown 自由输出)太松,模型格式随意、外层解析脆弱;右边( ExitPlanTool 参数)太死,等到退出计划阶段提问已经太晚;AskUserQuestion 独立工具落在中间,结构化且随时可调用,是这三者里最稳定的设计。
说白了,既然你就是要 Claude 停下来问一句,那就直接给它一个专门的工具。加个 flag 或者约定一段输出格式,很多时候它一顺手就略过去了。
Todo 工具的演进:
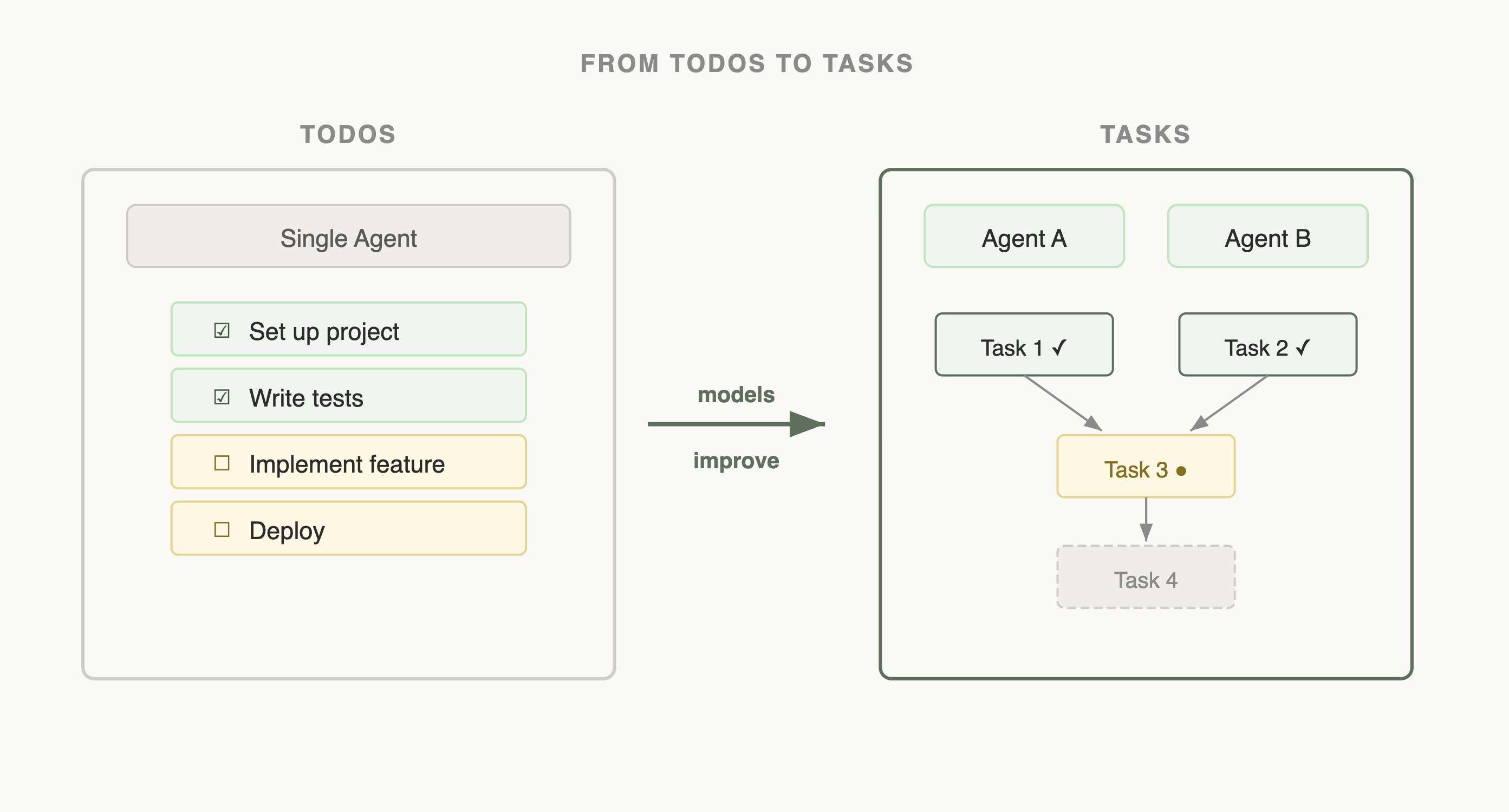
早期用 TodoWrite 工具 + 每 5 轮插入提醒让 Claude 记住任务。随着模型变强,这个工具反而成了限制,Todo 提醒让 Claude 认为必须严格遵循,无法灵活修改计划。挺有意思的教训:当初加这个工具是因为模型不够强,模型变强之后它反而变成了枷锁。值得过段时间回来检查一下,当初加的限制还成不成立。
搜索工具的演进:最初用 RAG 向量数据库,虽然快但需要索引、不同环境脆弱,最重要的是 Claude 不喜欢用。改成 Grep 工具让 Claude 自己搜索后,好用很多。后来又发现一个顺带的好处:Claude 读 Skill 文件,Skill 文件又引用其他文件,模型会递归读取,按需发现信息,不需要提前塞进去,这个模式后来被叫做"渐进式披露"。
什么时候不该再加 Tool
- 本地 shell 可以可靠完成的事情
- 模型只需要静态知识,不需要真正与外部交互
- 需求更适合 Skill 的工作流约束,而不是 Tool 的动作能力
- 还没验证过工具描述、schema 和返回格式能被模型稳定使用
6. Hooks:在 Claude 执行操作前后,强制插入你自己的逻辑
Hooks 很容易被当成"自动运行的脚本",但我自己用下来,觉得它更像是把一些不能交给 Claude 临场发挥的事情,重新收回到确定性的流程里。
比如格式化要不要跑、保护文件能不能改、任务完成后要不要通知,这些事真不要指望 Claude 每次都自己记得。
当前支持的 Hook 点
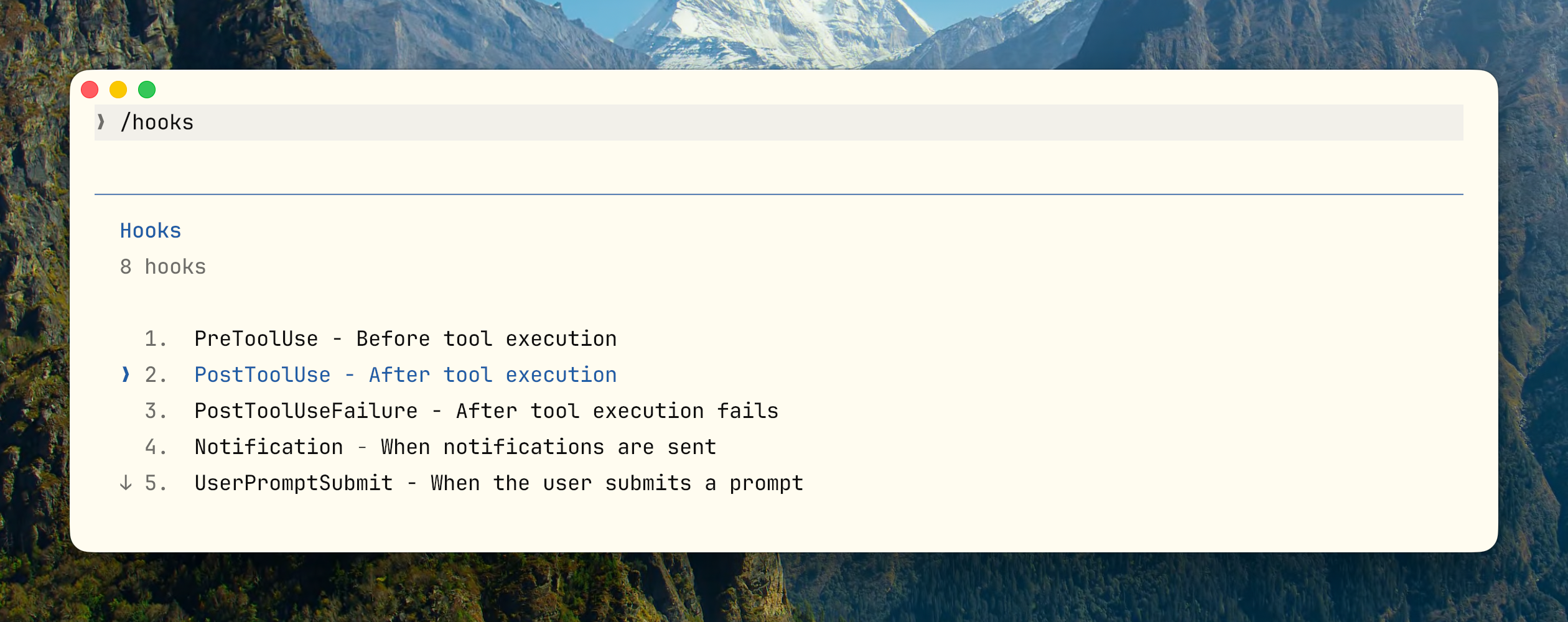
适合 vs 不适合放到 Hooks 的
适合:阻断修改受保护文件、Edit 后自动格式化/lint/轻量校验、SessionStart 后注入动态上下文( Git 分支、环境变量)、任务完成后推送通知。
不适合:需要读大量上下文的复杂语义判断、长时间运行的业务流程、需要多步推理和权衡的决策,这些该在 Skill 或 Subagent 里。
{
"hooks": {
"PostToolUse": [
{
"matcher": "Edit",
"pattern": "*.rs",
"hooks": [
{
"type": "command",
"command": "cargo check 2>&1 | head -30",
"statusMessage": "Running cargo check..."
}
]
}
],
"Notification": [
{
"type": "command",
"command": "osascript -e 'display notification \"Task completed\" with title \"Claude Code\"'"
}
]
}
}
Hooks:越早发现错误,越省时间

在 100 次编辑的会话中,每次节省 30-60 秒,累积节省 1-2 小时,还挺可观的。注意限制输出长度(| head -30),避免 Hook 输出反而污染上下文。如果不想在每条命令后面手动加截断,可以看看第 3 节提到的 RTK ,它把这件事系统化了。
Hooks + Skills + CLAUDE.md 三层叠加
CLAUDE.md:声明"提交前必须通过测试和 lint"Skill:告诉 Claude 在什么顺序下运行测试、如何看失败、如何修复Hook:对关键路径执行硬性校验,必要时阻断
用下来感觉,三样少任何一层都会有漏洞。只写 CLAUDE.md 规则,Claude 经常当没看见;只靠 Hooks ,细节判断又做不了,放在一起才比较稳。
7. Subagents:派一个独立的 Claude 去干一件具体的事
Subagent 就是从主对话派出去的一个独立 Claude 实例,有自己的上下文窗口,只用你指定的工具,干完汇报结果。我用下来觉得它最大的价值不是"并行",而是隔离——扫代码库、跑测试、做审查这类会产生大量输出的事,塞进主线程很快就把有效上下文挤没了,交给 Subagent 做,主线程只拿一个摘要,干净很多。
Claude Code 内置了三个:Explore(只读扫库,默认跑 Haiku 省成本)、Plan(规划调研)、General-purpose(通用),也可以自定义。
配置时要显式约束
tools/disallowedTools:限定能用什么工具,别给和主线程一样宽的权限model:探索任务用 Haiku/Sonnet ,重要审查用 OpusmaxTurns:防止跑飞isolation: worktree:需要动文件时隔离文件系统
另一个实用细节:长时间运行的 bash 命令可以按 Ctrl+B 移到后台,Claude 之后会用 BashOutput 工具查看结果,不会阻塞主线程继续工作。subagent 同理,直接告诉它「在后台跑」就行。
几个常见反模式
- 子代理权限和主线程一样宽,隔离没有意义
- 输出格式不固定,主线程拿到没法用
- 子任务之间强依赖,频繁要共享中间状态,这种情况用 Subagent 不合适
8. Prompt Caching:Claude Code 内部架构的核心
这块我之前在很多教程里都没怎么看到有人展开讲,但它其实很影响 Claude Code 的成本结构和很多设计取舍。
工程界有句话 "Cache Rules Everything Around Me",对 agent 同样如此,Claude Code 的整个架构都是围绕 Prompt 缓存构建的,高命中率不光省钱,速率限制也会松很多,Anthropic 甚至会对命中率跑告警,太低直接宣布 SEV 。
为缓存设计的 Prompt Layout

Prompt 缓存是按前缀匹配工作的,从请求开头到每个 cache_control 断点之前的内容都会被缓存。所以这里的顺序很重要:
Claude Code 的 Prompt 顺序:
1. System Prompt → 静态,锁定
2. Tool Definitions → 静态,锁定
3. Chat History → 动态,在后面
4. 当前用户输入 → 最后
破坏缓存的常见陷阱:
- 在静态系统 Prompt 中放入带时间戳的内容(让它每次都变)
- 非确定性地打乱工具定义顺序
- 会话中途增删工具
那像当前时间这种动态信息怎么办?别去动系统 Prompt ,放到下一条消息里传进去就行。Claude Code 自己也是这么做的,用户消息里加 <system-reminder> 标签,系统 Prompt 不动,缓存也就不会被打坏。
会话中途不要切换模型
Prompt 缓存是模型唯一的。假如你已经和 Opus 对话了 100K tokens ,想问个简单问题,切换到 Haiku 实际上比继续用 Opus 更贵,因为要为 Haiku 重建整个缓存。确实需要切换的话,用 Subagent 交接:Opus 准备一条"交接消息"给另一个模型,说明需要完成的任务就行。
Compaction 的实际实现
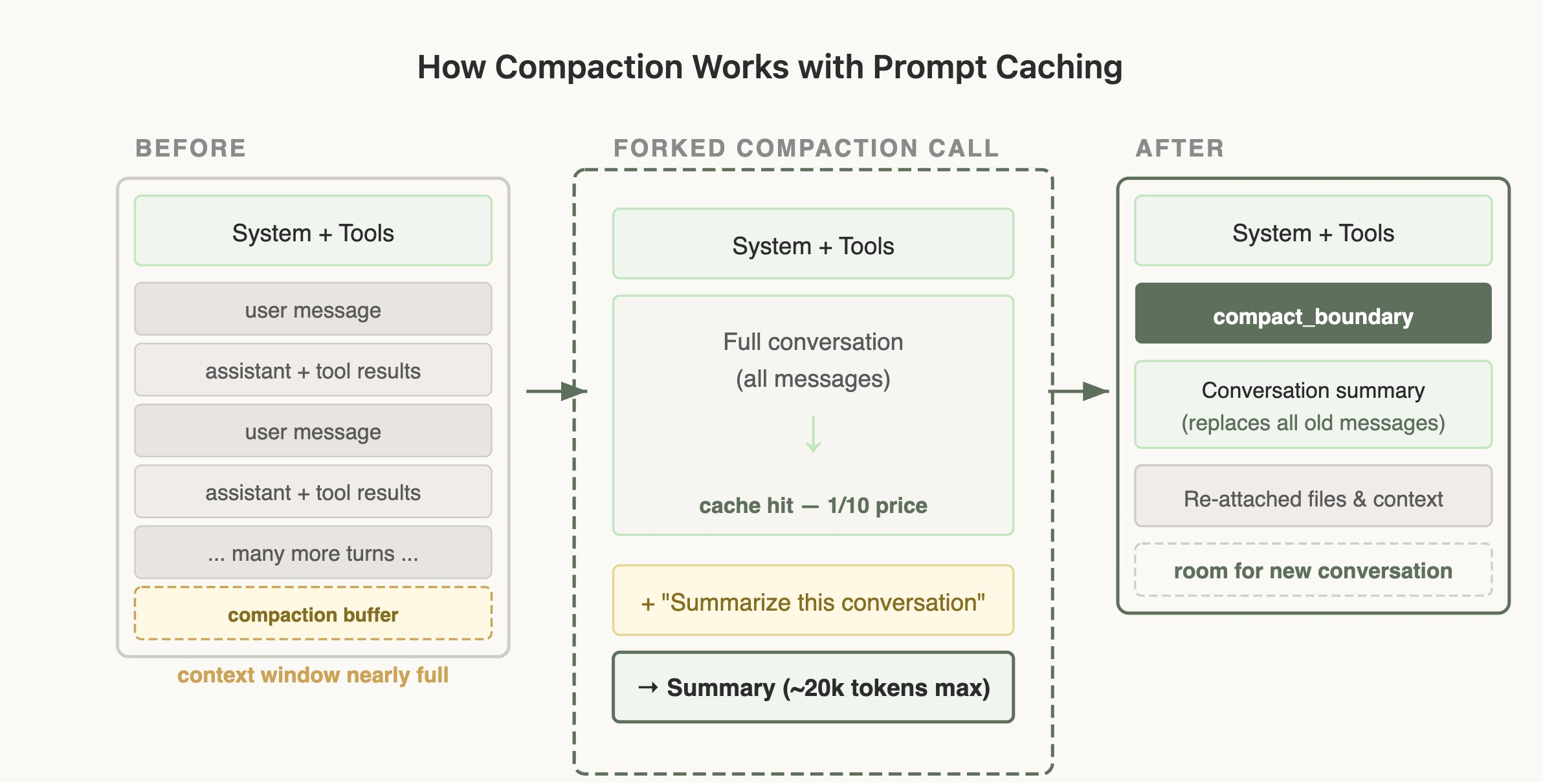
上图是 Compaction (上下文压缩)的执行流程:左边是上下文快满时的状态,中间是 Claude Code 开一个 fork 调用,把完整对话历史喂给模型,加一句"Summarize this conversation",这一步命中缓存所以只需 1/10 的价格,右边是压缩完之后,原来几十轮对话被替换成一段 ~20k tokens 的摘要,System + Tools 还在,再挂上之前用到的文件引用,腾出空间继续新的轮次。
直觉上 Plan Mode 应该切换成只读工具集,但这会破坏缓存。实际实现是:EnterPlanMode 是模型可以自己调用的工具,检测到复杂问题时自主进入 plan mode ,工具集不变,缓存不受影响。
defer_loading:工具的延迟加载
Claude Code 有数十个 MCP 工具,每次请求全量包含会很贵,但中途移除会破坏缓存。解决方案是发送轻量级 stub ,只有工具名,标记 defer_loading: true。模型通过 ToolSearch 工具"发现"它们,完整的工具 schema 只在模型选择后才加载,这样缓存前缀保持稳定。
9. 验证闭环:没有 Verifier 就没有工程上的 Agent
「 Claude 说完成了」其实没啥用,你得能知道它做没做对、出了问题能退回来、过程还能查,这才算数。
Verifier 的层级
- 最低层:命令退出码、lint 、typecheck 、unit test
- 中间层:集成测试、截图对比、contract test 、smoke test
- 更高层:生产日志验证、监控指标、人工审查清单
在 Prompt 、Skill 和 CLAUDE.md 中显式定义验证
## Verification
For backend changes:
- Run `make test` and `make lint`
- For API changes, update contract tests under `tests/contracts/`
For UI changes:
- Capture before/after screenshots if visual
Definition of done:
- All tests pass
- Lint passes
- No TODO left behind unless explicitly tracked
写任务 Prompt 或 Skill 的时候,最好把验收标准提前说清楚。哪些命令跑完算完成,失败了先查什么,截图和日志看到什么才算过,这些越早讲明白,后面越省事。
我自己有个很简单的判断:假如一个任务你都说不清楚「 Claude 怎么才算做对了」,那它大概率也不适合直接丢给 Claude 自动完成。
10. 高频命令的工程意义
这些命令说白了就干一件事:主动管理上下文,别等系统自己处理。
上下文管理
/context # 查看 token 占用结构,排查 MCP 和文件读取占比
/clear # 清空会话,同一问题被纠偏两次以上就重来
/compact # 压缩但保留重点,配合 Compact Instructions
/memory # 确认哪些 CLAUDE.md 真的被加载了
能力与治理
/mcp # 管理 MCP 连接,检查 token 成本,断开闲置 server
/hooks # 管理 hooks ,控制平面入口
/permissions # 查看或更新权限白名单
/sandbox # 配置沙箱隔离,高自动化场景必备
/model # 切换模型:Opus 用于深度推理,Sonnet 用于常规,Haiku 用于快速探索
会话连续性与并行
claude --continue # 恢复当前目录最近会话,隔天接着做
claude --resume # 打开选择器恢复历史会话
claude --continue --fork # 从已有会话分叉,同一起点不同方案
claude --worktree # 创建隔离 git worktree
claude -p "prompt" # 非交互模式,接入 CI / pre-commit / 脚本
claude -p --output-format json # 结构化输出,便于脚本消费
几个不常见但很好用的命令
**/simplify**:对刚改完的代码做三维检查,代码复用、质量和效率,发现问题直接修掉。特别适合改完一段逻辑后立刻跑一遍,代替手动 review 。
**/rewind**:不是"撤销",而是回到某个会话 checkpoint 重新总结。适合:Claude 已沿错误路径探索太久;想保留前半段共识但丢掉后半段失败。
**/btw**:在不打断主任务的前提下快速问一个侧问题,适合"两个命令有什么区别"这类单轮旁路问答,不适合需要读仓库或调用工具的问题。
**claude -p --output-format stream-json**:实时 JSON 事件流,适合长任务监控、增量处理、流式集成到自己的工具。
**/insight**:让 Claude 分析当前会话,提炼出哪些内容值得沉淀到 CLAUDE.md 。用法是会话做了一段之后跑一次,它会指出"这个约定你们反复提到,但没有写进契约"之类的盲点,是迭代优化 CLAUDE.md 的好手段。
双击 ESC 回溯:按两次 ESC 可以回到上一条输入重新编辑,不用重新手打。Claude 走偏了、或者上一句话没说清楚,双击 ESC 修改后重发,比重新开会话省事得多。
对话历史都在本地:所有会话记录存放在 ~/.claude/projects/ 下,文件夹名按项目路径命名(斜杠变横杠),每个会话是一个 .jsonl 文件。想找某个话题的历史,直接 grep -rl "关键词" ~/.claude/projects/ 就能定位,或者直接告诉 Claude 「帮我搜一下之前关于 X 的讨论」,它会自己去翻。
11. 如何写一个好的 CLAUDE.md
CLAUDE.md 在我看来更像是你和 Claude 之间的协作契约,不是团队文档,也不是知识库,里面只放那些每次会话都得成立的事。
我自己的建议其实很简单,一开始甚至可以什么都不写。先用起来,等你发现自己老是在重复同一件事,再把它补进去。加法也不复杂,输入 # 可以把当前对话里的内容直接追加进 CLAUDE.md ,或者直接告诉 Claude 「把这条加到项目的 CLAUDE.md 里」,它会知道该改哪个文件。
应该放什么
- 怎么 build 、怎么 test 、怎么跑(最核心)
- 关键目录结构与模块边界
- 代码风格和命名约束
- 那些不明显的环境坑
- 绝对不能干的事( NEVER 列表)
- 压缩时必须保留的信息( Compact Instructions )
不该放什么
- 大段背景介绍
- 完整 API 文档
- 空泛原则,如"写高质量代码"
- Claude 通过读仓库即可推断的显然信息
- 大量背景资料和低频任务知识(这些放到 Skills )
高质量模板
写到这里发现 V2EX 内容放不下了,那就去我https://x.com/HiTw93/status/2032091246588518683 看吧,欢迎交流。









































