
Clicknium上线以后收到了不少反馈,其中很多用户在使用 Clicknium 来抓取数据。场景很多比如购物网站的商品名,价格和图片等,甚至就是网页上的一个表格。Clicknium 有提供获取相似数据( Similar elements )的功能,但是只能用来抓取同一类数据,小伙伴们只能分列抓取表格数据着实比较费劲,还得涉及到列之间的匹配问题,确实非常劝退。 所以研究了一下,加上了获取结构化数据的功能( data scraper )。 主要有两个使用场景:
- 表格
- 非表格
使用方法:
点击 VS code 上的 Capture 按钮会启动 Recorder ,选择 Data Scraper ,Ctrl + Click
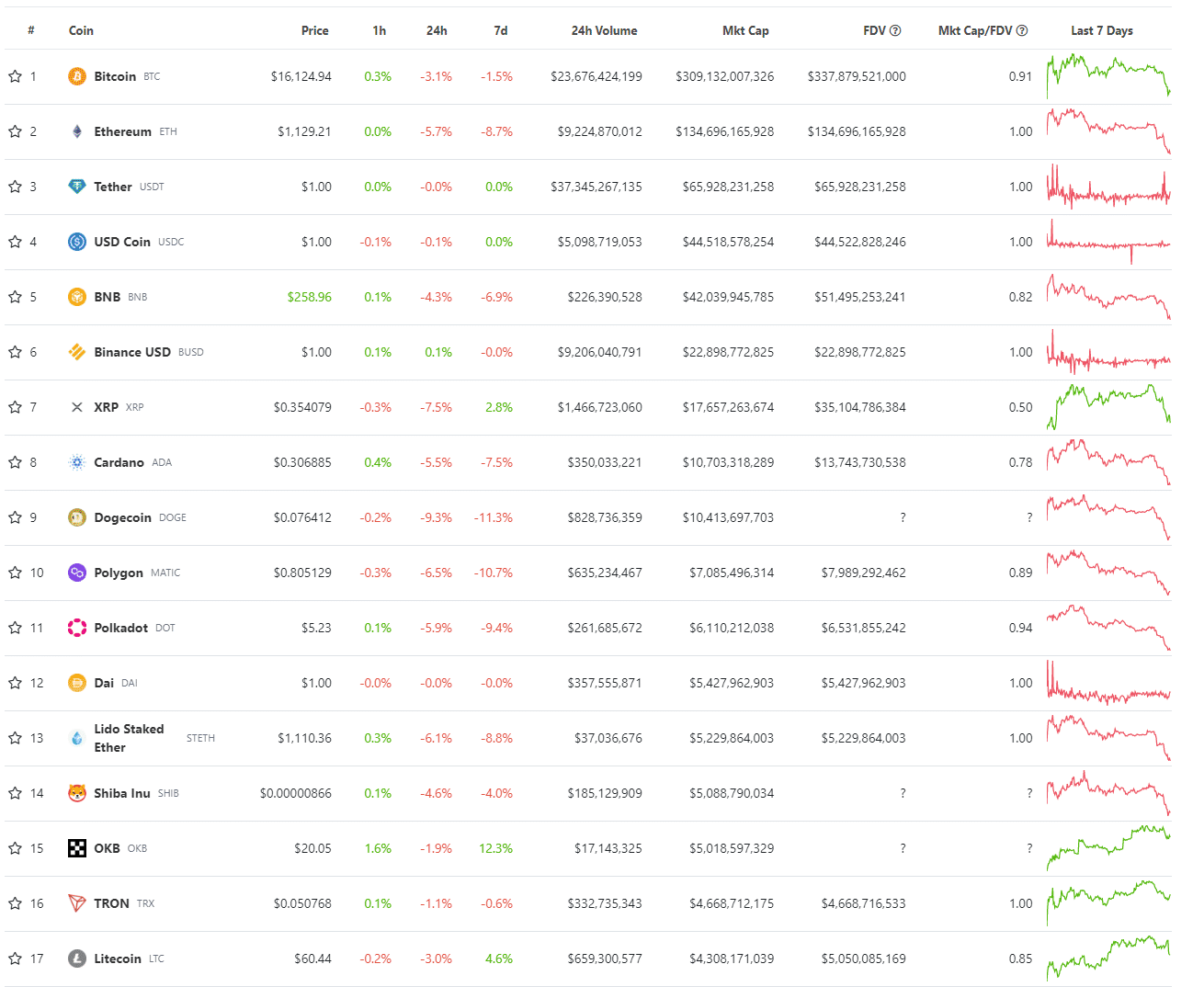
以 Coingecko举例,当需要抓取下面的表格
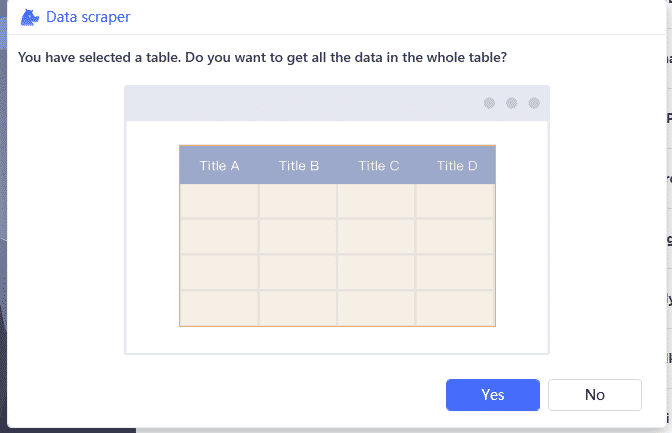
只需要使用Ctrl+鼠标左键点击表格第一行第一列数据,Clicknium 会自动判断抓取对象为表格,并提示是否抓取全表信息:
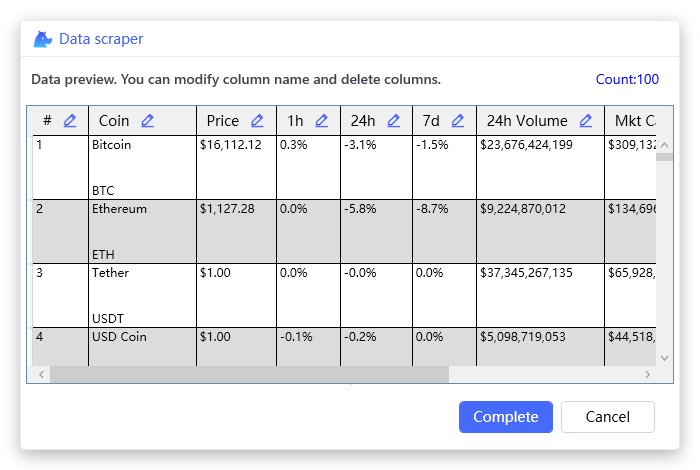
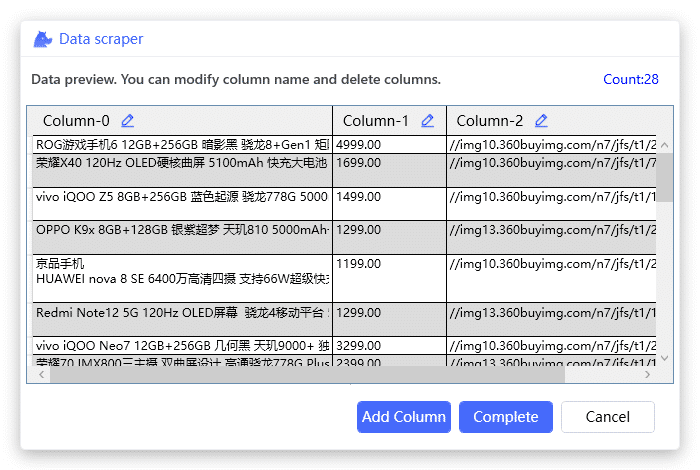
 选择 Yes 后,获得数据预览,在这个窗口中可以看到抓取到的数据量,修改和删除列,改变列顺序:
选择 Yes 后,获得数据预览,在这个窗口中可以看到抓取到的数据量,修改和删除列,改变列顺序:
- 非表格数据
以最常见的京东作为例子:
京东手机页面
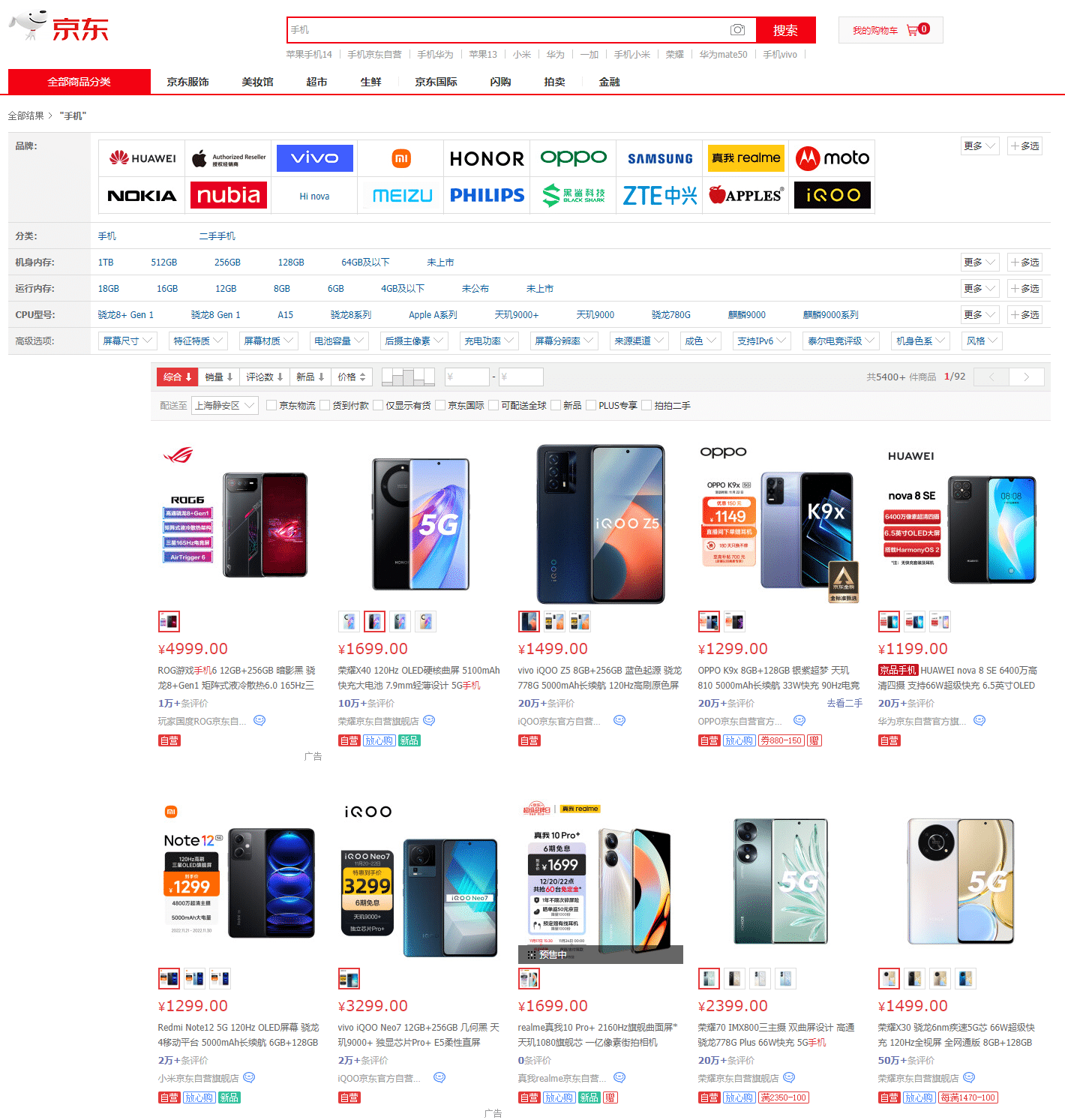 抓取商品名、价格和图片,点击 data scraper ,开始抓取元素。采用两行确定一列的模式,操作方式与获取相似元素类似:
抓取商品名、价格和图片,点击 data scraper ,开始抓取元素。采用两行确定一列的模式,操作方式与获取相似元素类似: - 抓取第一列第一个元素
- 抓取第一列第二个元素
- 添加列,抓取第二列第一个元素
- 抓取第二列第二个元素 。。。
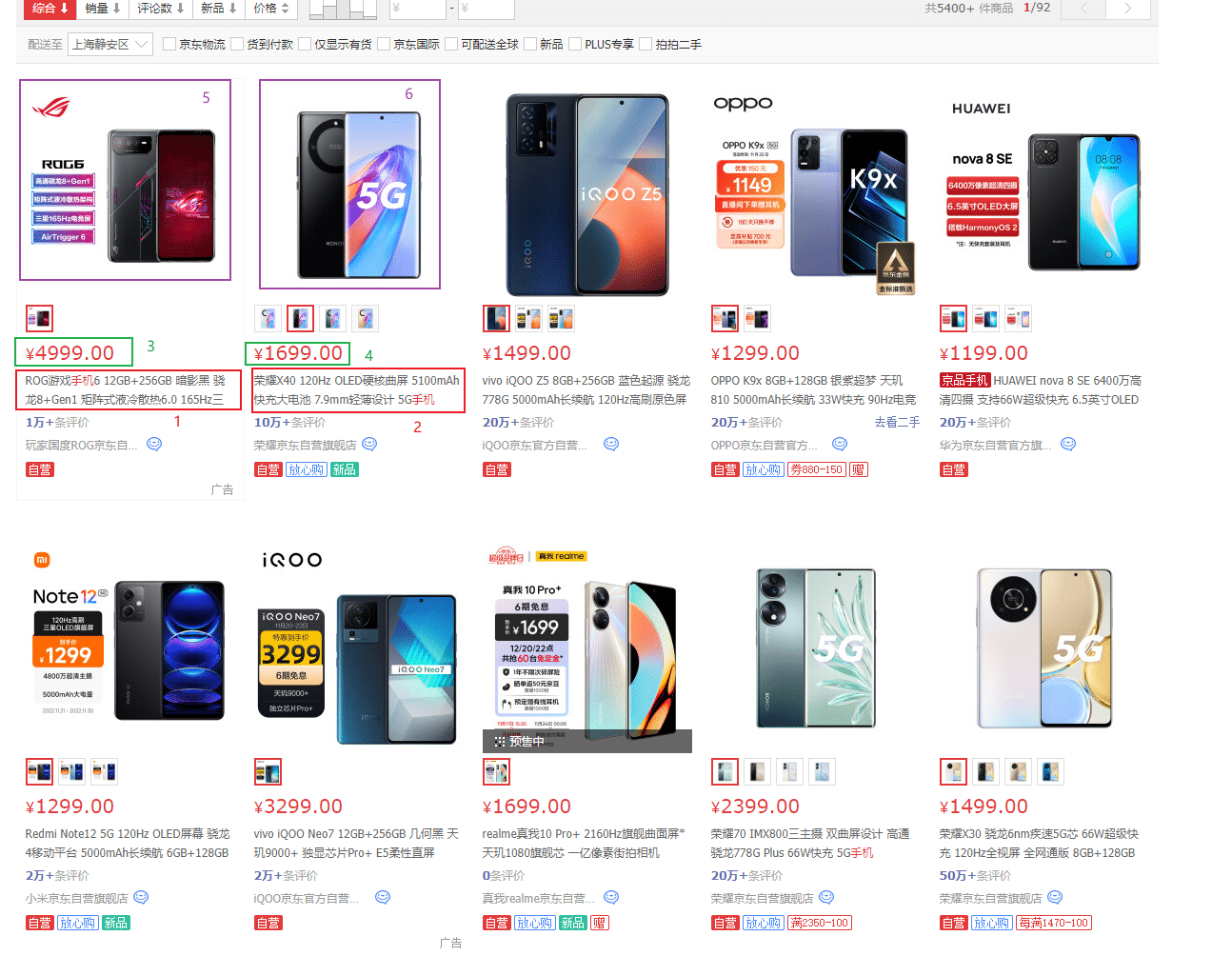 Clicknium 自动计算网页结构得到下表:
Clicknium 自动计算网页结构得到下表:
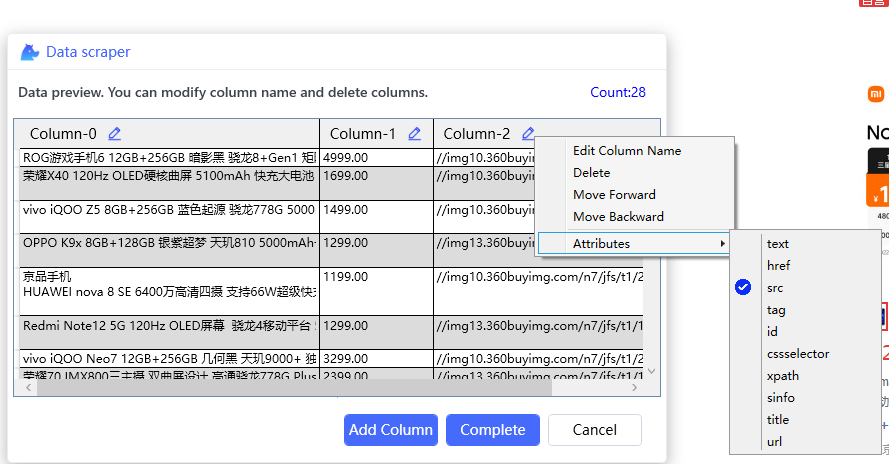
在预览页面,可以修改列名,信息和选择属性值:
 获得结构化数据:
获得结构化数据:
from clicknium import clicknium as cc, locator
import pandas as pd
row = cc.scrape_data(locator.jd.phone)
df = pd.json_normalize(row)
print(df.head(10))
Scrape_data 接口会返回 json 格式的文本数据, 不仅如此,该函数支持传入翻页按钮的 locator 实现自动翻页,翻页支持设置控件和模拟鼠标等方式,等待页面加载,抓取数据条数控制和超时。
def scrape_data(
locator: Union[_Locator, str],
locator_variables: dict = {},
next_page_button_locator: Union[_Locator, str] = None,
next_page_button_locator_variables: dict = {},
next_page_button_by: Union[Literal["default", "mouse-emulation", "control-invocation"], MouseActionBy] = MouseActionBy.Default,
wait_page_load_time: int = 5,
max_count: int = -1,
timeout: int = 30
) -> object:
简单录个屏:
https://www.bilibili.com/video/BV1aW4y1W7xQ/?vd_source=196b3ee9ffb643890ce610323e5504e5
https://www.youtube.com/watch?v=1gDGnzrwWLk
一些 updates:
- 由于 Chrome manifest V2 马上要过期了,最近升级了 Manifest V3
- 支持对 tab 和 UI 组件 native 方式截图
- 最近会开始研究跨平台和开源
- 有空的话研究一下写一个 Pycharm 的 plugin


