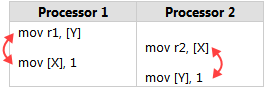
这个和缓存的一致性协议(e.g. MESI)没有关系,主要是和 x86 的内存一致性模型的约定有关。
为了实现的简便,或者优化的方便,计算机领域一个非常重要的 trick 就是[as if rule](
https://en.wikipedia.org/wiki/As-if_rule)。编译器和硬件可以不按照实际的程序 /指令执行,只要最终不会产生**软件可以观察到**的差异就行了。
具体来看,如果我们更多的在聊 Intel 的话,x86-TSO 的内存一致性模型主要有下面这么几个约定,而 OP 的例子正是很多人用来说明第 4 点的比较常用的例子:
1. Loads are not reordered with other loads.
2. Stores are not reordered with other stores.
3. Stores are not reordered with older loads.
4. Loads may be reordered with older stores to different locations but not with older stores to the same location.
仔细想想,这样的约定正是尽量较少软件可观察的差异体现。作为软件,我们期待写一个变量下一次读出同样的值,所以约定 Store/Load 在同一个内存地址不会有 reorder 。与此同时,写一个变量然后读取另一个变量会有 reorder ,这似乎对软件产生的麻烦就小很多。
最后,为啥非要 reorder ?那当然是硬件那边优化和实现的考虑了,CPU 一般会通过[store buffer](
https://en.wikipedia.org/wiki/Write_buffer)来批量写内存提升效率,不难想象,Store/Load reorder 的存在,不就是顺理成章的事情了嘛。当然,这里对为什么这么约定的解释,更多只是举一个例子的意思,没人真正知道这是不是 Intel 选择上述约定的动机或者唯一动机,重要的只是这个约定是啥样,和我们如何用这个约定解释程序行为。