

本文首发于 Nebula 公众号:图查询语言的历史回顾短文
前言
最近在对图查询语言 GQL 和国际标准草案做个梳理,调研过程中找到下面这篇 mark 了没细看的旧文(毕竟收藏就是看过)。做个简单的记录。
摘要
本短文会涉及到的图查询语言有 Cypher 、Gremlin 、PGQL 和 G-CORE 。
背景
本文主要摘录翻译自 [Tobias2018] (见参考文献),并未涉及到 SPARQL 和 RDF,只讨论了属性图。
文章撰写的时间是 2018 年,可以看做 GQL ( Graph Query Language )的一些前期准备。GQL 有多个相关的起源,参见下面这张图。
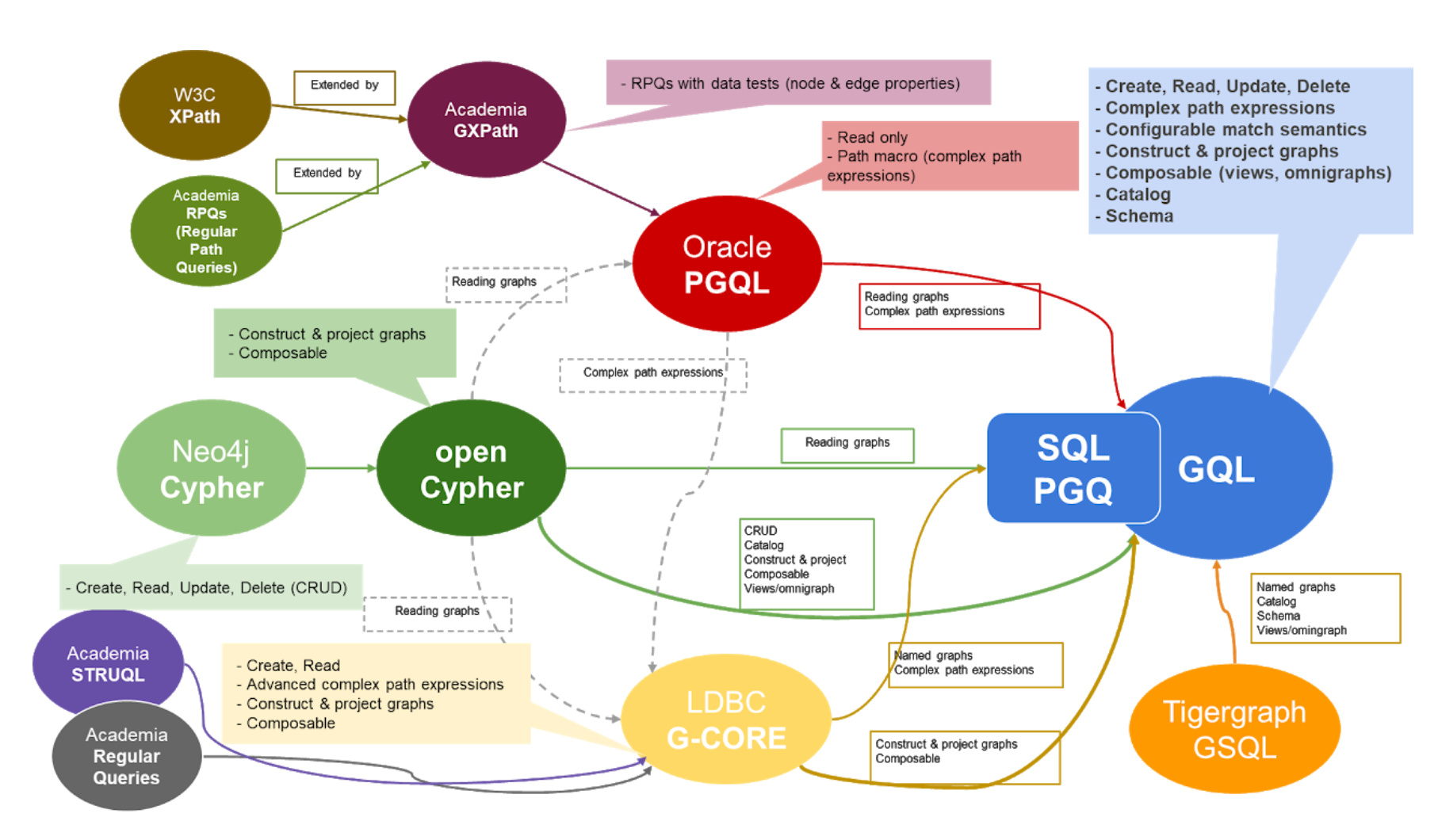
因为 Cypher 的历史和 Neo4j 紧密相关,本文会提一些 Neo4j 早期的历史。[Angles2008](见参考文献)和 [Wood2012](见参考文献)是两个不错的关于图模型和图查询语言的总结。
年表简述
- 2000 年,Neo4j 的创始人产生将数据建模成网络( network )的想法。
- 2001 年,Neo4j 开发了最早的核心部分代码。
- 2007 年,Neo4j 以一个公司的方式运作。
- 2009 年,Neo4j 团队借鉴 XPath 作为图查询语言,Gremlin 最初也是基于这个想法。
- 2010 年,Neo4j 和 Marko Rodriguez 采用术语属性图( Property Graph )来描述 Neo4j 和 Tinkerpop / Gremlin 的数据模型。[PG2010](见参考文献)
- 2011 年,第一个公开发行版本 Neo4j 1.4 发布了第一个版本的 Cypher 。
- 2012 年,Neo4j 1.8 为 Cypher 增加写入图的能力。
- 2012 年,Neo4j 2.0 增加了标签和索引,Cypher 成为声明式的语言。
- 2015 年,Oracle 为 PGX 发明查询语言 PGQL 。
- 2015 年,Neo4j 将 Cypher 开源为 openCypher 。
- 2015 年,LDBC 成立图查询语言工作组。
- 2016 年,LDBC 工作组开始设计 G-CORE 。
- 2017 年,WG3 工作组开始讨论如何将属性图查询能力引入 SQL 。
- 2017 年,LDBC 工作组完成了 G-CORE 的初始设计 [GCORE2018](见参考文献)。
- 2018 年,Cypher 形式化语义的论文发表 [Cypher2018] (见参考文献)。
Gremlin 、Cypher 、PGQL 和 G-CORE 的演进
Neo4j 的早期历史
Neo4j 和属性图这种数据模型,最早构想于 2000 年。Neo4j 的创始人们当时在开发一个媒体管理系统,所使用的数据库的 schema 经常会发生重大变化。为了支持这种灵活性,Neo4j 的联合创始人 Peter Neubauer,受 Informix Cocoon 的启发,希望将系统建模为一些概念相互连接的网络。印度理工学院孟买分校的一群研究生们实现了最早的原型。Neo4j 的联合创始人 Emil Eifrém 和这些学生们花了一周的时间,将 Peter 最初的想法扩展成为这样一个模型:节点通过关系连接,key-value 作为节点和关系的属性。这群人开发了一个 Java API 来和这种数据模型交互,并在关系型数据库之上实现了一个抽象层。
虽然这种网络模型极大的提高了生产力,但是性能一直很差。所以 Neo4j 联合创始人 Johan Svensson 花精力,为这种网络模型实现了一个原生的数据管理系统。这个就成为了 Neo4j 。 在最初的几年,Neo4j 作为一个内部产品很成功。在 2007 年,Neo4j 的知识产权转移给了一家独立的数据库公司。
Neo4j 的第一个公开发行版中,数据模型由节点和有类型的边构成,节点和边都有 key-value 组成的属性。Neo4j 的早期版本没有任何的索引,应用程序只能从根节点开始自己构造查询结构( search structure )。因为这样对于应用程序非常笨重,Neo4j 2.0 ( 2013 年 12 月发布)引入了一个新概念——点上的标签( label )。基于点标签,Neo4j 可以为一些预定义的节点属性建立索引。
节点、关系、属性、关系只能有一个标签、节点可以有零个或者多个标签,以上这些构成了 Neo4j 属性图的数据模型定义。后来增加的索引功能,让 Cypher 成为了与 Neo4j 交互的主要方式。因为这样应用开发者只需要关注于数据本身,而不是上段提到的那个开发者自己构建的查询结构( search structure )。
图或者说网络类型的数据模型(多对多的关系)和其数据库的历史,可以追溯到 80 年代。见 Kleppmann 2017 第二章(见参考文献部分)。
Gremlin 的创造
最初与 Neo4j 的查询方式是通过 Java API 。应用程序可以将查询引擎作为库嵌入到应用程序中,然后使用 API 查询图。如果是自定义查询引擎,然后应用程序远程访问服务器,这样就比较困难。
就在这段时间,NOSQL 这个概念开始出现。NOSQL 型的数据库引擎一般用 REST 和 HTTP 来交互和查询。Neo4j 的早期员工 Tobias Lindaaker (和 Ivarsson )考虑用 HTTP 的方式访问 Neo4j 会是一种更好的办法。他们观察到很多的查询语句可以表达为:图到树的投影映射( projection )。典型的,从根节点开始遍历一个扩张树( spanning tree ),然后返回叶子节点。基于这样的观察,并参考一些树结构的查询语句,比如 XPath,也许可以作为一种图的查询方式。而且,XPath 的语法和一般 URI 的语法很像。这样 XPath 查询可以很自然的作为 HTTP GET 中 URI 的一部分。Neo4j 的联合创始人 Peter Neubauer 喜欢这个想法,找了一个朋友 Marko Rodriguez 来干。两天后,Marko 做了一个原型,用 XPath 作为图查询,Groovy 提供循环结构,分支,和计算。 这个就是 Gremlin 最初的原型。2009 年 11 月发布了第一个版本。
后来,Marko 发现同时用两种不同的解析器( XPath 和 Groovy )有很多问题,就将 Gremlin 改为基于 Groovy 的一种内置的领域特定语言( DSL )。
Cypher 的创造
Gremlin 和 Neo4j 的 Java API 一样,最初用于表达如何查询数据库的一种过程( Procedural )。它允许更短的语法来表达查询,也允许通过网络远程访问数据库。Gremlin 这种过程式的特性,需要用户知道如何采用最好的办法查询结果,这样对于应用程序开发人员来说仍旧有负担。基于声明式语言 SQL 的成功:SQL 可以将获取数据的声明方式和引擎如何获取数据分开,Neo4j 的工程师们希望开发一种声明式的图查询语言。
2010 年,Andrés Taylor 作为工程师加入 Neo4j,在此之前他是 SQL DBA 。他开始了一个项目,受 SQL 启发,其目标是开发图查询语言,而这种新语言 Cypher 于 2011 年 Neo4j 1.4 发布。
Cypher 的语法基础,是用 "ascii 艺术(ascii art)" 来描述图模式。这种方式最初来源于 Neo4j 工程师团队在源代码中评注如何描述图模式。可以看下图的例子:
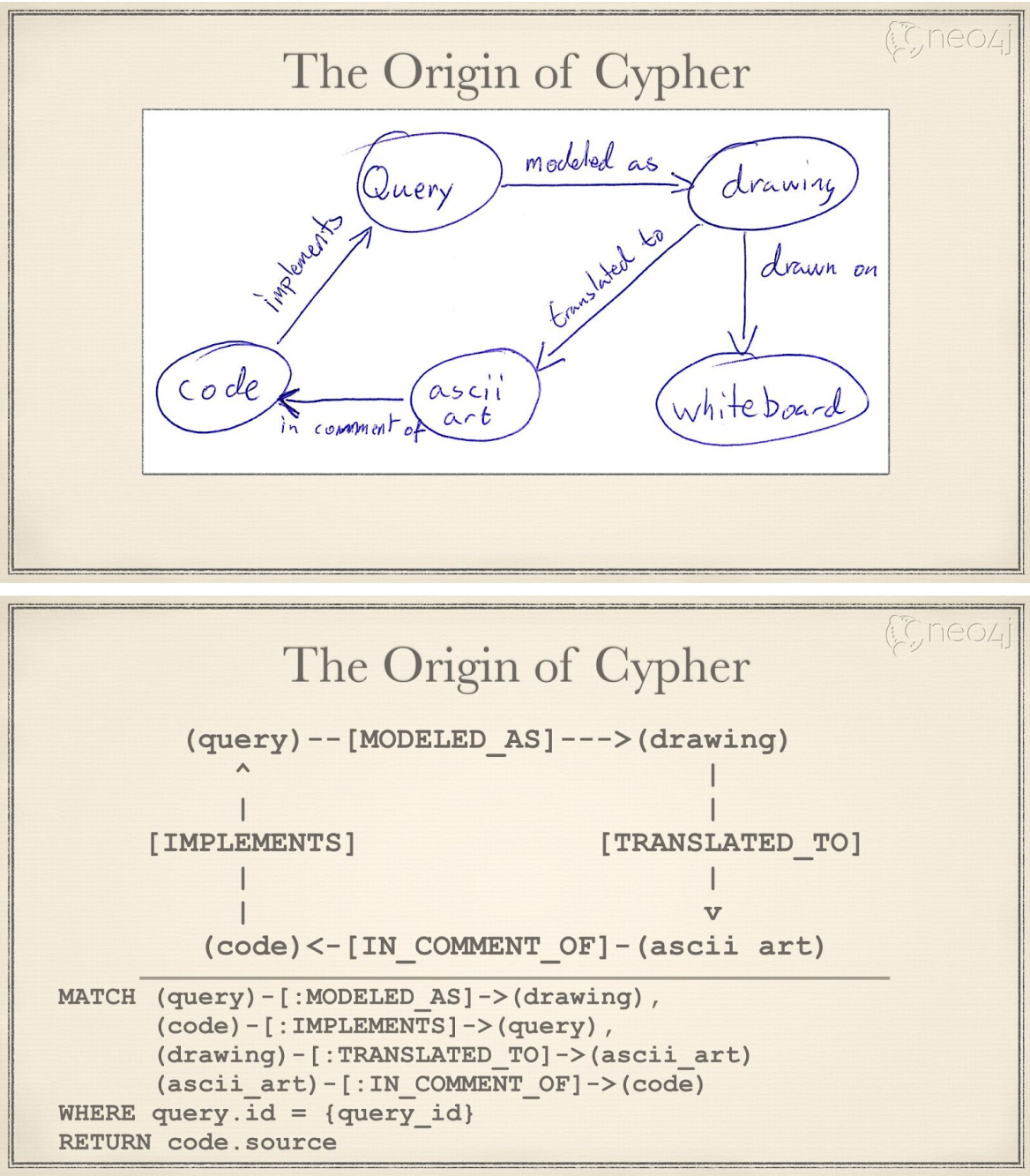
ascii art 简单说,就是如何用可打印文本来描述点和边。Cypher 文本用()表示点,-[]->表示边。(query)--[modeled as]->(drawing) 来表示起点 query,终点 drawing,边 modeled as 。
对于程序员来说,当然可以设计一个 API 表示操作点,一个 API 表示操作边. 但这样就不是 SQL 这种声明式语言的目的,对于非程序员使用也太困难。
Cypher 第一个版本实现了对图的读取,但是需要用户说明从哪些节点开始查询。只有从这些节点开始,才可以支持图的模式匹配。
略微学术一点的说,graph patterns (或者 motifs finding )和 navigational expression 是两种不同的图查询操作[Renzo2017][databricks2020](见参考文献部分)。不同语言这两种操作的语义是有一定差别的。
在后面的版本,2012 年 10 月发布的 Neo4j 1.8 中,Cypher 增加了修改图的能力。但查询还是需要指明从哪些节点开始。
2013 年 12 月,Neo4j 2.0 引入了 label 的概念,label 本质上是个索引。这样,查询引擎就可以利用索引,来选择模式所匹配到的节点,而不需要用户指定开始查询的节点。
有没有熟悉的感觉?
随着 Neo4j 的普及,Cypher 有着广泛的开发者群体 ,和各行各业的使用。
图查询语言也有声明式( Decalarative )和命令式( Imperative )的区别,前者( Cypher )相比后者( Gremlin )更强调目的和手段分离,更依赖于执行优化。但在工程上,两者思想并没有那么大的区别,后者也会有延迟计算和优化,前者也可以部分命令式的思想。好的优化在工程上并不是那么容易,专业的用户比查询引擎更清楚如何求取、访问、加工数据[Renzo2017][Deutsh2020]。
openCypher - 一种推进和标准化 Cypher 的开源过程
2015 年 9 月,Neo4j 开放了 Cypher 查询语言,通过开源的方式来治理。这个新主体的治理主体是 openCypher Implementors Group ( oCIG )。
2016 年,openCypher 项目发布 EBNF 和 ANTLR4,Neo4j 也贡献了很多基于 Apache 2.0 的语言功能测试集( openCypher Technology Compatibility Kit, TCK )。将这些作为语言标准定义,任何人都可以为该语言提交新的提议。2016 年,SAP HANA Graph 发布了基于 Cypher 的查询部分的实现,Agens Graph 和 Redis Graph 在 2017 年支持了 Cypher 。2017 年 oCIG 也进行了一系列线上线下的会议,讨论语言功能扩展等。
这个治理和讨论方式可以通过如下方式:https://github.com/opencypher/openCypher/blob/master/CIP-PROCESS.adoc
oCIG 发布 openCypher,采用英语语言作为规范,对应了 Neo4j 3.3.0 版本中的 Cypher 。
PGQL 的创建
2015 年,Oracle 为 PGX 引擎开发了图查询语言 PGQL 。PGQL 受 Cypher 的启发,也和 Cypher 很接近。
G-CORE 的创建
Linked Data Benchmarking Council ( LDBC )定义了一种厂商无关的基准测试。在开发这个基准测试的过程中,他们发现市面上没有标准的查询语言来表达图查询。为了处理这个问题,成立了一个特别工作组,调研市面上已经存在的图查询语言和框架,定义图查询必须的功能,然后为现有语言提供修改建议。
2016 年,他们想设计一种新语言,而不是对于现有语言的修改。主要原因是不想受现有语言的模型的限制。
G-CORE 是由 LDBC 工作组设计的,但主要受 Cypher 的启发,采用一样的语义。
结论
Cypher 是 PGQL 和 G-CORE 的共同祖先。这几个语言的语法和语义都非常的接近。PGQL 更接近一些早期的 Cypher,而 G-CORE 更期望语法和语义上都与 Cypher 兼容。
一些个人看法
除去学术上的探索和一些零散的工程尝试,以 Cypher 作为主流属性图查询语言工程实践的历史基准,也就 10 年的时间。在前面的几年 2010-2013,Cypher 自身在基础图功能上还有不少缺失,比如索引、图模式,迭代到 2014 年才产生当前使用的一个主流版本,并且还在持续演化 [Nadime2018](见参考文献部分)。
重头全新设计一种图语言其实很难,很可能会把前人走过的路(坑)再走(掉)一遍( G-CORE 和 nGQL )。这是 GQL 第一个不容易的地方。
一个标准化组织中,有学术和商业机构,各自诉求也很不相同,商业机构已经各自有庞大的商业使用群体,这是第二个不容易的地方。
制定完的标准,最后是否会被市场所接受和采纳( vendor 、custormer 、developer 、goverment ),又需要多少的布道。这是 GQL 第三个不容易的地方。
除了核心基础的图操作以外的特性,比如 SQL 、pregel [Grzegorz2010](见参考文献部分)、GNN,每个语言 PGQL 、GSQL 甚至 Neo4j 自己都各自采用了完全不同的方式来支持这些特性,要不要考虑这些新出现的特性。这是 GQL 第四个不容易的地方。
再想想 GQL 和 Apache Tinkerpop/Gremlin 这两条完全不同的路,这是一个变化很快的时代,计算机又是一个更强调 de facto 标准的行业,GQL 并不容易。(打脸)
参考文献
- [Angles2008] Renzo Angles and Claudio Gutierrez, “Survey of Graph Database Models”, ACM Computing Surveys, Vol. 40, February 2008
- [PG2010] Marko A. Rodriguez and Peter Neubauer, “The Graph Traversal Pattern”, April 2010
- [Wood2012] Peter Wood, “Query Languages for Graph Databases”, SIGMOD Record 2012
- [Cypher2018] Nadime Francis, Alastair Green, Paolo Guagliardo, Leonid Libkin, Tobias Lindaaker, Victor Marsault, Stefan Plantikow, Mats Rydberg, Petra Selmer, and Andrés Taylor, “Cypher: An Evolving Query Language for Property Graphs”, SIGMOD 2018
- [GCORE2018] Renzo Angles, Marcelo Arenas, Pablo Barceló, Peter Boncz, George Fletcher, Claudio Gutierrez, Tobias Lindaaker, Marcus Paradies, Stefan Plantikow, Juan Sequeda, Oskar van Rest, and Hannes Voigt, “G-CORE A Core for Future Graph Query Languages”, SIGMOD 2018
- [Cypher9] openCypher, “Cypher Query Language Reference”, Version 9, Nov. 2017
- Renzo2017 Renzo Angles, Marcelo Arenas, Pablo Barceló, Aidan Hogan, Juan Reutter, and Domagoj Vrgoč. 2017. Foundations of Modern Query Languages for Graph Databases. ACM Comput. Surv. 50, 5, Article 68 (November 2017), 40 pages.
- Kleppmann2017 Kleppmann, Martin: Designing Data-Intensive Applications. Beijing : O'Reilly, 2017. - ISBN 978-1-4493-7332-0
- [Tobias2018] Title: An overview of the recent history of Graph Query Languages. Authors Tobias Lindaaker, U.S. National Expert.Date: 2018-05-14
- Deutsh2020 Alin Deutsch, Yu Xu, Mingxi Wu, and Victor E. Lee. 2020. Aggregation Support for Modern Graph Analytics in TigerGraph. In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data (SIGMOD '20). Association for Computing Machinery, New York, NY, USA, 377–392.
- Grzegorz2010 Grzegorz Malewicz, Matthew H. Austern, Aart J.C Bik, James C. Dehnert, Ilan Horn, Naty Leiser, and Grzegorz Czajkowski. 2010. Pregel: a system for large-scale graph processing. In Proceedings of the 2010 ACM SIGMOD International Conference on Management of data (SIGMOD '10). Association for Computing Machinery, New York, NY, USA, 135–146.
- Nadime2018 Nadime Francis, Alastair Green, Paolo Guagliardo, Leonid Libkin, Tobias Lindaaker, Victor Marsault, Stefan Plantikow, Mats Rydberg, Petra Selmer, and Andrés Taylor. 2018. Cypher: An Evolving Query Language for Property Graphs. In Proceedings of the 2018 International Conference on Management of Data (SIGMOD '18). Association for Computing Machinery, New York, NY, USA, 1433–1445.
- databricks2020https://docs.databricks.com/spark/latest/graph-analysis/graphframes/user-guide-scala.html#motif-finding
交流图数据库技术?加入 Nebula 交流群请先填写下你的 Nebulae 名片,Nebula 小助手会拉你进群~~
查看大厂实践案例?Follow Nebula 公众号:NebulaGraphCommunity 回复「 PPT 」掌握 [美团的图数据库系统] 、 [微众银行的数据治理方案] 以及其他大厂的风控、知识图谱实践。
{kind=link}