
这是一个创建于 1674 天前的主题,其中的信息可能已经有所发展或是发生改变。
@[TOC](Oracle 调优之看懂 SQL 执行计划 explain)
原文链接:https://smilenicky.blog.csdn.net/article/details/106812252
1 、文章写作前言简介
之前曾经拜读过《收获,不止 sql 调优》一书,此书是国内 DBA 写的一本很不错的调优类型的书,是一些很不错的调优经验的分享。虽然读了一遍,做了下读书笔记,觉得很有所收获,但是到实际的实践中觉得还是很缺实践。刚好最近又有一次 sql 调优培训活动,去参加后,重新复习 Oracle 执行计划,所以整理资料,做成笔记分享出来
2 、什么是执行计划?
执行计划是一条查询语句在 Oracle 中的执行过程或访问路径的描述。
执行计划描述了 SQL 引擎为执行 SQL 语句进行的操作;分析 SQL 语句相关的性能问题或仅仅质疑查询优化器的决定时,必须知道执行计划;所以执行计划常用于 sql 调优。
3 、怎么查看执行计划?
查看 Oracle 执行计划有很多种,详情参考我之前的读书笔记,本博客只介绍很常用的方法
oracle 要使用执行计划一般在 sqlplus 执行 sql:
explain plan for select 1 from t
不过如果是使用 PLSQL 的话,那就可以使用 PLSQL 提供的查询执行计划了,也就是按 F5
打开 PLSQL 工具 -> 首选项 -> 窗口类型 -> 计划窗口 ,在这里加入执行计划需要的参数
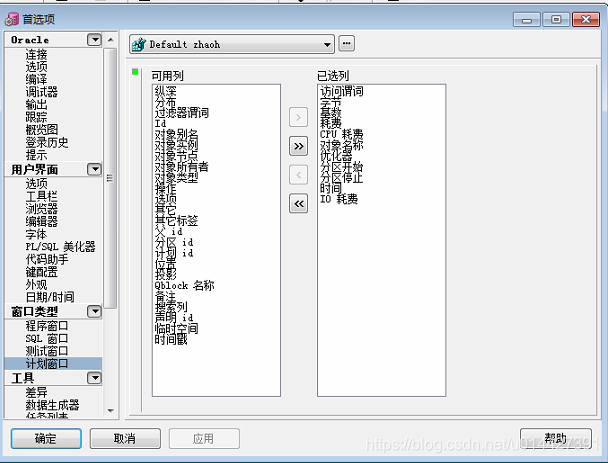
找个 SQL,用 PLSQL 执行一下,这是 plsql 的简单使用
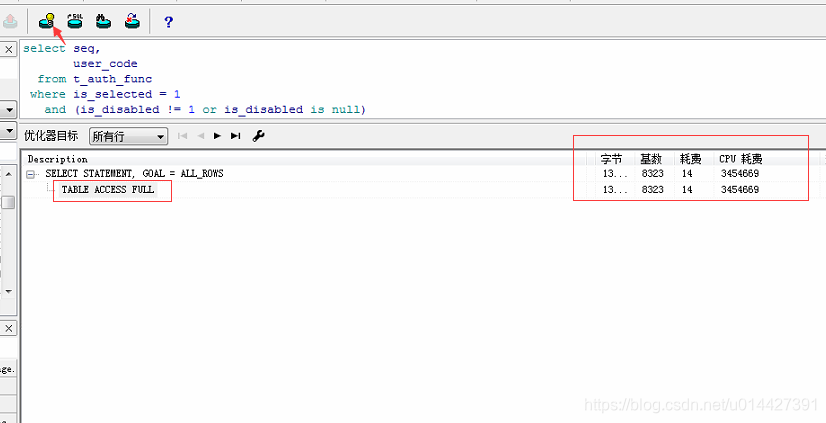
解释一下这些参数的意思:
- 基数(Rows):Oracle 估计的当前步骤的返回结果集行数
- 字节(Bytes):执行 SQL 对应步骤返回的字节数
- 耗费(COST)、CPU 耗费:Oracle 估计的该步骤的执行耗费和 CPU 耗费
- 时间(Time):Oracle 估计的执行 sql 对于步骤需要的时间
4 、查看真实执行计划
之前查看执行计划也喜欢按 F5,不过最近去培训,听一名 dba 说,这种方法有时候不能获取真实的执行计划,收集的信息也不全面,然后怎么查看 sql 执行过程的真实信息?从培训中学到的经验做成笔记
sqlplus 窗口执行:
- step1:set statistics_level
alter session set statistics_level=ALL;
- step2:执行业务 sql
select /*+ monitor */ * from ... where ....;
- step3:为了样式,设置 linesize
set linesize 200 pagesize 300;
- step4:查询真实执行计划
select * from table(dbms_xplan.display_cursor(null, null, 'iostats last'));
sqlplus 一般要数据库管理员才可以使用,如果你不是 dba,只能使用 plsql developer 的话,只能用下面的方法,方法是从培训中学到的
使用存储过程,SQL:
declare
b1 date;
begin
execute immediate 'alter session set statistics_level=ALL';
b1 := sysdate - 1;
for test in (
/*业务 SQL(sql 后面不需要加";")*/
select * from t) loop
null;
end loop;
for x in (select p.plan_table_output
from table(dbms_xplan.display_cursor(null,
null,
'advanced -bytes -PROJECTION allstats last')) p) loop
dbms_output.put_line(x.plan_table_output);
end loop;
rollback;
end;
/
两种窗口:
- 1 、SQL 窗口的,执行 SQL 后只能去 output 查看;
- 2 、command window 的,需要先设置
set serveroutput on size unlimited,然后再执行存储过程
output 或者命令窗口查看的真实执行计划和统计信息:
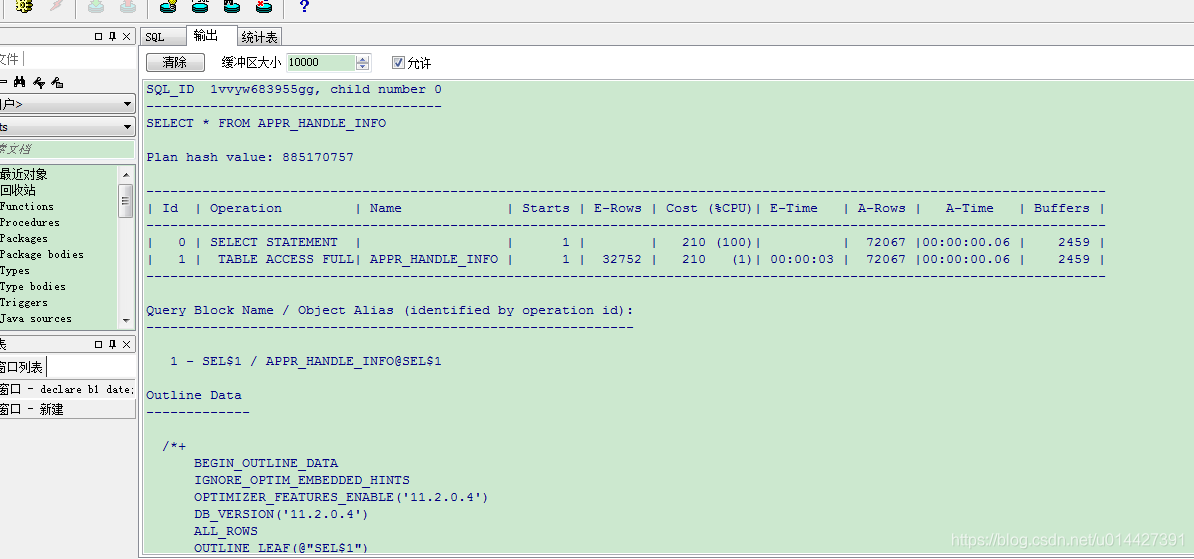
SQL_ID abk3ghv9u1tvb, child number 0
-------------------------------------
SELECT /*+ monitor */ * FROM APPR_HANDLE_INFO
Plan hash value: 885170757
------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | Cost (%CPU)| E-Time | A-Rows | A-Time | Buffers |
------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 210 (100)| | 72059 |00:00:00.06 | 2460 |
| 1 | TABLE ACCESS FULL| APPR_HANDLE_INFO | 1 | 32752 | 210 (1)| 00:00:03 | 72059 |00:00:00.06 | 2460 |
------------------------------------------------------------------------------------------------------------------------
Query Block Name / Object Alias (identified by operation id):
-------------------------------------------------------------
1 - SEL$1 / APPR_HANDLE_INFO@SEL$1
Outline Data
-------------
/*+
BEGIN_OUTLINE_DATA
IGNORE_OPTIM_EMBEDDED_HINTS
OPTIMIZER_FEATURES_ENABLE('11.2.0.4')
DB_VERSION('11.2.0.4')
ALL_ROWS
OUTLINE_LEAF(@"SEL$1")
FULL(@"SEL$1" "APPR_HANDLE_INFO"@"SEL$1")
END_OUTLINE_DATA
*/
关键信息解释:
- Starts:该 SQL 执行的次数
- E-Rows:为执行计划预计的行数
- A-Rows:实际返回的行数,E-Rows 和 A-Rows 作比较,就可以看出具体那一步执行计划出问题了
- A-Time:每一步实际执行的时间,可以看出耗时的 SQL
- Buffers:每一步实际执行的逻辑读或一致性读
5 、看懂 Oracle 执行计划
上面已经介绍了如何查看执行计划,现在简单介绍一下一些基本方法和相关理论知识
5.1 查看 explain
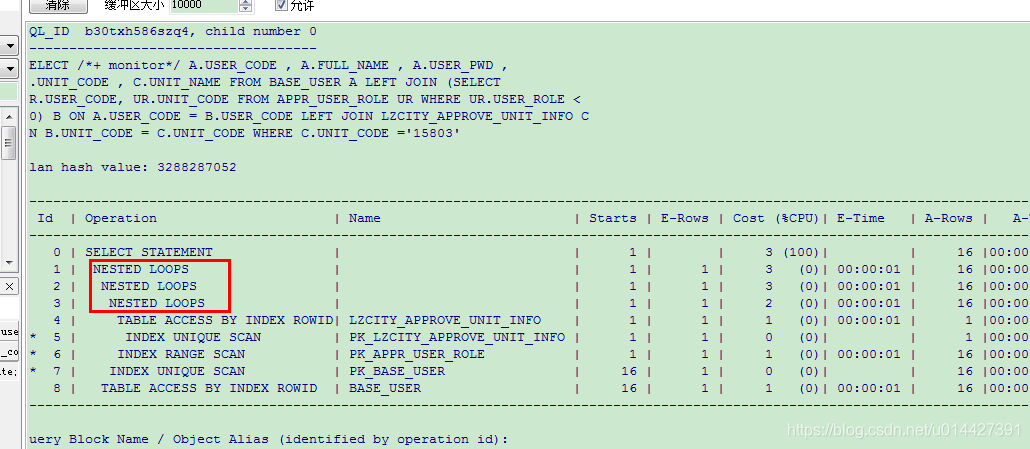
找一条比较复杂的 SQL,执行:
F5 方式查看:
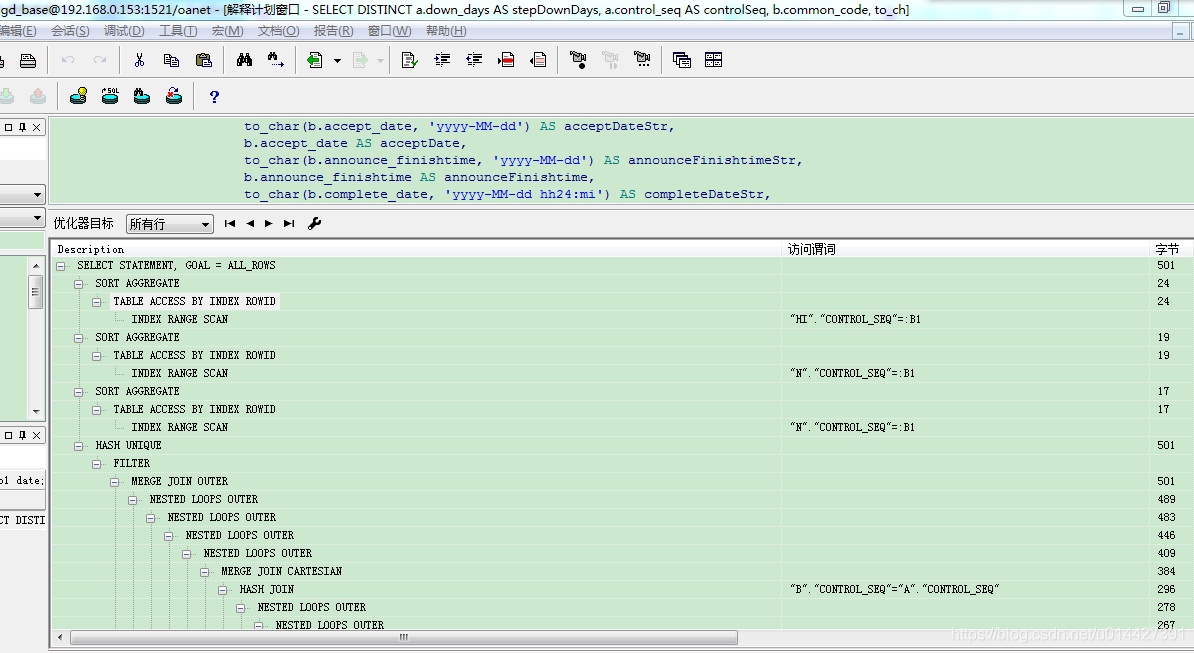 set statistics_level=ALL 方式:
set statistics_level=ALL 方式:
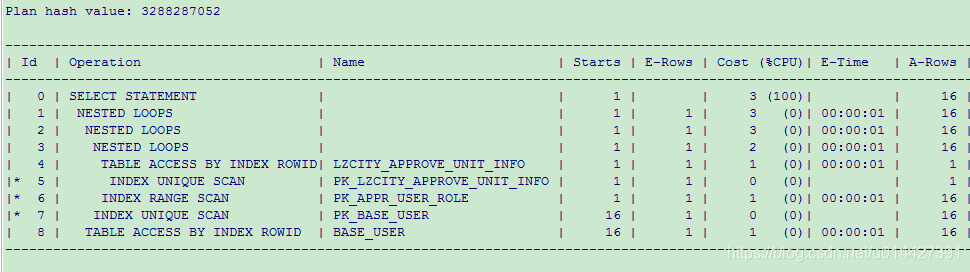
SQL_ID 4qfq3t2ukm0y1, child number 0
-------------------------------------
SELECT /*+ monitor*/ A.USER_CODE, A.FULL_NAME, A.USER_PWD, C.UNIT_CODE,
C.UNIT_NAME FROM BASE_USER A LEFT JOIN (SELECT UR.USER_CODE,
UR.UNIT_CODE FROM APPR_USER_ROLE UR WHERE UR.USER_ROLE < 10) B ON
A.USER_CODE = B.USER_CODE LEFT JOIN LZCITY_APPROVE_UNIT_INFO C ON
B.UNIT_CODE = C.UNIT_CODE WHERE C.UNIT_CODE ='15803'
Plan hash value: 3288287052
------------------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | Cost (%CPU)| E-Time | A-Rows | A-Time | Buffers |
------------------------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 3 (100)| | 16 |00:00:00.01 | 38 |
| 1 | NESTED LOOPS | | 1 | 1 | 3 (0)| 00:00:01 | 16 |00:00:00.01 | 38 |
| 2 | NESTED LOOPS | | 1 | 1 | 3 (0)| 00:00:01 | 16 |00:00:00.01 | 22 |
| 3 | NESTED LOOPS | | 1 | 1 | 2 (0)| 00:00:01 | 16 |00:00:00.01 | 5 |
| 4 | TABLE ACCESS BY INDEX ROWID| LZCITY_APPROVE_UNIT_INFO | 1 | 1 | 1 (0)| 00:00:01 | 1 |00:00:00.01 | 3 |
|* 5 | INDEX UNIQUE SCAN | PK_LZCITY_APPROVE_UNIT_INFO | 1 | 1 | 0 (0)| | 1 |00:00:00.01 | 2 |
|* 6 | INDEX RANGE SCAN | PK_APPR_USER_ROLE | 1 | 1 | 1 (0)| 00:00:01 | 16 |00:00:00.01 | 2 |
|* 7 | INDEX UNIQUE SCAN | PK_BASE_USER | 16 | 1 | 0 (0)| | 16 |00:00:00.01 | 17 |
| 8 | TABLE ACCESS BY INDEX ROWID | BASE_USER | 16 | 1 | 1 (0)| 00:00:01 | 16 |00:00:00.01 | 16 |
------------------------------------------------------------------------------------------------------------------------------------------------
Query Block Name / Object Alias (identified by operation id):
-------------------------------------------------------------
1 - SEL$E3445A69
4 - SEL$E3445A69 / C@SEL$4
5 - SEL$E3445A69 / C@SEL$4
6 - SEL$E3445A69 / UR@SEL$2
7 - SEL$E3445A69 / A@SEL$3
8 - SEL$E3445A69 / A@SEL$3
Outline Data
-------------
/*+
BEGIN_OUTLINE_DATA
IGNORE_OPTIM_EMBEDDED_HINTS
OPTIMIZER_FEATURES_ENABLE('11.2.0.4')
DB_VERSION('11.2.0.4')
ALL_ROWS
OUTLINE_LEAF(@"SEL$E3445A69")
MERGE(@"SEL$2")
OUTLINE(@"SEL$A2E96217")
OUTER_JOIN_TO_INNER(@"SEL$E9F4A6F9" "B"@"SEL$1")
OUTER_JOIN_TO_INNER(@"SEL$E9F4A6F9" "C"@"SEL$4")
OUTLINE(@"SEL$2")
OUTLINE(@"SEL$E9F4A6F9")
MERGE(@"SEL$80808B20")
OUTLINE(@"SEL$6")
OUTLINE(@"SEL$80808B20")
MERGE(@"SEL$4")
MERGE(@"SEL$F1D6E378")
OUTLINE(@"SEL$5")
OUTLINE(@"SEL$4")
OUTLINE(@"SEL$F1D6E378")
MERGE(@"SEL$1")
OUTLINE(@"SEL$3")
OUTLINE(@"SEL$1")
INDEX_RS_ASC(@"SEL$E3445A69" "C"@"SEL$4" ("LZCITY_APPROVE_UNIT_INFO"."UNIT_CODE"))
INDEX(@"SEL$E3445A69" "UR"@"SEL$2" ("APPR_USER_ROLE"."UNIT_CODE" "APPR_USER_ROLE"."USER_CODE" "APPR_USER_ROLE"."AREA_SEQ"
"APPR_USER_ROLE"."USER_ROLE"))
INDEX(@"SEL$E3445A69" "A"@"SEL$3" ("BASE_USER"."USER_CODE"))
LEADING(@"SEL$E3445A69" "C"@"SEL$4" "UR"@"SEL$2" "A"@"SEL$3")
USE_NL(@"SEL$E3445A69" "UR"@"SEL$2")
USE_NL(@"SEL$E3445A69" "A"@"SEL$3")
NLJ_BATCHING(@"SEL$E3445A69" "A"@"SEL$3")
END_OUTLINE_DATA
*/
Predicate Information (identified by operation id):
---------------------------------------------------
5 - access("C"."UNIT_CODE"='15803')
6 - access("UR"."UNIT_CODE"='15803' AND "UR"."USER_ROLE"<10)
filter("UR"."USER_ROLE"<10)
7 - access("A"."USER_CODE"="UR"."USER_CODE")
5.2 explain 执行顺序
所以不管是用 F5 方式还是 set statistics_level=ALL 方式,都有 Operation 参数,Operation 表示 sql 执行过程,查看怎么执行的,有两个规则:
- 根据 Operation 缩进判断,缩进最多的最先执行;
- Operation 缩进相同时,最上面的是最先执行的;
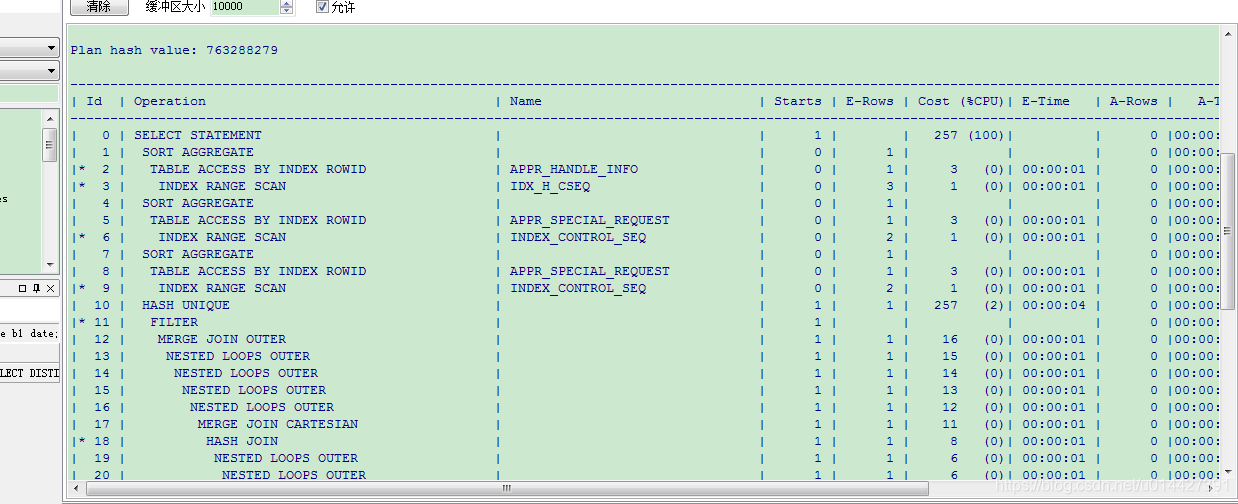
如图执行计划,根据规则,可以得出执行顺序:INDEX UNIQUE SCAN->TABLE ACCESS BY INDEX ROWID->INDEX RANGE SCAN ->NESTED LOOPS ->INDEX UNIQUE SCAN->NESTED LOOPS ->TABLE ACCESS BY INDEX ROWID->NESTED LOOPS-> SELECT STATEMENT
5.3 访问数据的方法
Oracle 访问表中数据的方法有两种,一种是直接表中访问数据,另外一种是先访问索引,如果索引数据不符合目标 SQL,就回表,符合就不回表,直接访问索引就可以。
Oracle 直接访问表中数据的方法又分为两种:一种是全表扫描;另一种是 ROWID 扫描
5.3.1 全表扫描( TABLE ACCESS FULL )
- 全表扫描;( TABLE ACCESS FULL )
全表扫描是 Oracle 直接访问数据的一种方法,全表扫描时从第一个区(EXTENT)的第一个块(BLOCK)开始扫描,一直扫描的到表的高水位线(High Water Mark),这个范围内的数据块都会扫描到
全表扫描是采用多数据块一起扫的,并不是一个个数据库扫的,然后我们经常说全表扫描慢是针对数据量很多的情况,数据量少的话,全表扫描并不慢的,不过随着数据量越多,高水位线也就越高,也就是说需要扫描的数据库越多,自然扫描所需要的 IO 越多,时间也越多
注意:数据量越多,全表扫描所需要的时间就越多,然后直接删了表数据呢?查询速度会变快?其实并不会的,因为即使我们删了数据,高位水线并不会改变,也就是同样需要扫描那么多数据块
5.3.2 ROWID 扫描( TABLE ACCESS BY ROWID )
- ROWID 扫描( TABLE ACCESS BY ROWID )
ROWID 也就是表数据行所在的物理存储地址,所谓的 ROWID 扫描是通过 ROWID 所在的数据行记录去定位。ROWID 是一个伪列,数据库里并没有这个列,它是数据库查询过程中获取的一个物理地址,用于表示数据对应的行数。 用 sql 查询:
select t.* , rowid from 表格
随意获取一个 ROWID 序列:AAAWSJAAFAAAWwUAAA,前 6 位表示对象编号(Data Object number),其后 3 位文件编号(Relative file number),接着其后 6 位表示块编号(Block number), 再其后 3 位表示行编号(Row number)
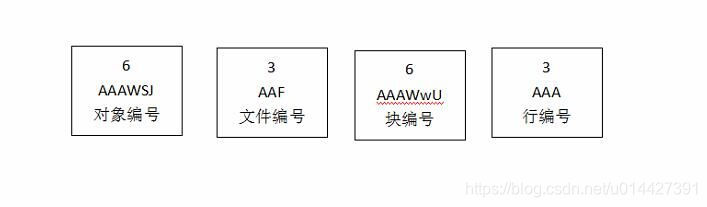
ROWID 编码方法是:A ~ Z 表示 0 到 25 ; a ~ z 表示 26 到 51 ; 0~9 表示 52 到 61 ;+表示 62 ;/表示 63 ;刚好 64 个字符。
这里随意找张表查一下文件编号、区编号、行编号,查询后会返回 rowid 的一系列物理地址和文件编号(rowid_relative_fno(rowid))、块编号(rowid_block_number(rowid))、行编号(rowid_row_number(rowid))
select t.seq,
rowid,
dbms_rowid.rowid_relative_fno(rowid),
dbms_rowid.rowid_block_number(rowid),
dbms_rowid.rowid_row_number(rowid)
from t_info t
SQL 查询一下表格名称为 TABLE 的对象编码
select owner,object_id,data_object_id,status from dba_objects where object_name='TABLE';
相对文件 id 和绝对文件编码 相对文件 id 是指相对于表空间,在表空间唯一;绝对文件编码是指相当于全局数据库而言的,全局唯一;下面 SQL 查询一下相对文件 id 和绝对文件编码
select file_name,file_id,relative_fno from dba_data_files;
访问索引( TABLE ACCESS BY INDEX SCAN )的情况就比较多了,可以分为:
- 索引唯一扫描( INDEX UNIQUE SCAN )
- 索引全扫描( INDEX FULL SCAN )
- 索引范围扫描( INDEX RANGE SCAN )
- 索引快速全扫描( INDEX FAST FULL SCAN )
- 索引跳跃式扫描( INDEX SKIP SCAN )
5.3.3 索引唯一扫描( INDEX UNIQUE SCAN )
- 索引唯一扫描( INDEX UNIQUE SCAN )
索引唯一性扫描(INDEX UNIQUE SCAN)是针对唯一性索引(UNIQUE INDEX)来说的,也就是建立唯一性索引才能索引唯一性扫描,唯一性扫描,其结果集只会返回一条记录。
- 索引范围扫描( INDEX RANGE SCAN )
5.3.4 索引范围扫描( INDEX RANGE SCAN )
- 索引范围扫描( INDEX RANGE SCAN )索引范围扫描(INDEX RANGE SCAN)适用于所有类型的 B 树索引,一般不包括唯一性索引,因为唯一性索引走索引唯一性扫描。 当扫描的对象是非唯一性索引的情况,where 谓词条件为 Between 、=、<、>等等的情况就是索引范围扫描,注意,可以是等值查询,也可以是范围查询。如果 where 条件里有一个索引键值列没限定为非空的,那就可以走索引范围扫描,如果改索引列是非空的,那就走索引全扫描
前面说了,同样的 SQL 建的索引不同,就可能是走索引唯一性扫描,也有可能走索引范围扫描。在同等的条件下,索引范围扫描所需要的逻辑读和索引唯一性扫描对比,逻辑读如何?索引范围扫描可能返回多条记录,所以优化器为了确认,肯定会多扫描,所以在同等条件,索引范围扫描所需要的逻辑读至少会比相应的唯一性扫描的逻辑读多 1
5.3.5 索引全扫描( INDEX FULL SCAN )
- 索引全扫描( INDEX FULL SCAN )
索引全扫描(INDEX FULL SCAN)适用于所有类型的 B 树索引(包括唯一性索引和非唯一性索引)。
索引全扫描过程简述:索引全扫描是指扫描目标索引所有叶子块的索引行,但不意思着需要扫描所有的分支块,索引全扫描时只需要访问必要的分支块,然后定位到位于改索引最左边的叶子块的第一行索引行,就可以利用改索引叶子块之间的双向指针链表,从左往右依次顺序扫描所有的叶子块的索引行
5.3.6 索引快速全扫描( INDEX FAST FULL SCAN )
- 索引快速全扫描( INDEX FAST FULL SCAN )
索引快速全扫描和索引全扫描很类似,也适用于所有类型的 B 树索引(包括唯一性索引和非唯一性索引)。和索引全扫描类似,也是扫描所有叶子块的索引行,这些都是索引快速全扫描和索引全扫描的相同点
索引快速全扫描和索引全扫描区别:
- 索引快速全扫描只适应于 CBO(基于成本的优化器)
- 索引快速全扫描可以使用多块读,也可以并行执行
- 索引全扫描会按照叶子块排序返回,而索引快速全扫描则是按照索引段内存储块顺序返回
- 索引快速全扫描的执行结果不一定是有序的,而索引全扫描的执行结果是有序的,因为索引快速全扫描是根据索引行在磁盘的物理存储顺序来扫描的,不是根据索引行的逻辑顺序来扫描的
5.3.7 索引跳跃式扫描( INDEX SKIP SCAN )
- 索引跳跃式扫描( INDEX SKIP SCAN )
索引跳跃式扫描(INDEX SKIP SCAN)适用于所有类型的***复合 B 树索引***(包括唯一性索引和非唯一性索引),索引跳跃式扫描可以使那些在 where 条件中没有目标索引的前导列指定查询条件但是有索引的非前导列指定查询条件的目标 SQL 依然可以使用跳跃索引
如图执行计划就有 INDEX RANGE SCAN 、INDEX UNIQUE SCAN 等等
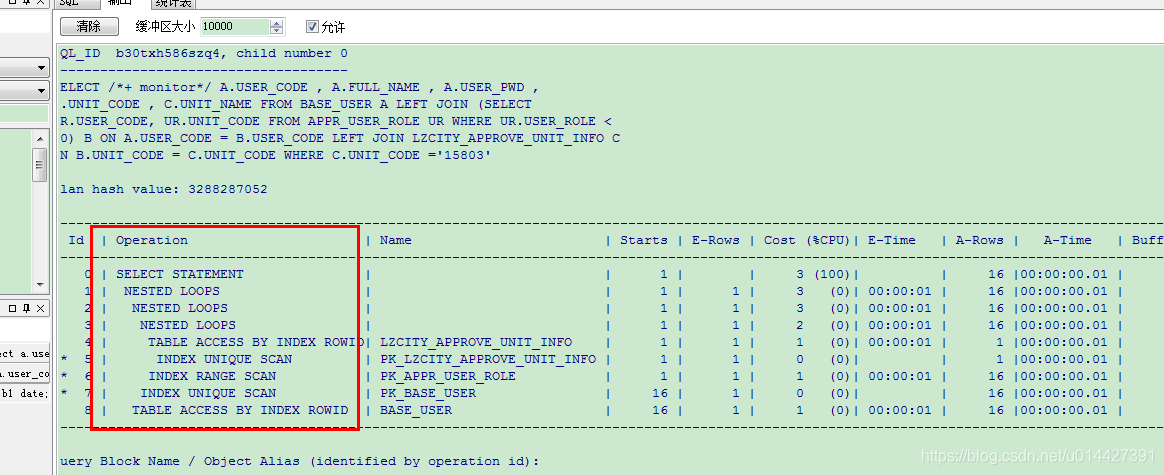
5.4 表连接方法
如图,执行计划中有如下 NESTED LOOPS 等等这些,是什么?这种其实就是 Oracle 中表连接的方法
两个表之间的表连接方法有排序合并连接、嵌套循环连接、哈希连接、笛卡尔连接
-
排序合并连接( merge sort join ) merge sort join 是先将关联表的关联列各自做排序,然后从各自的排序表中抽取数据,到另一个排序表中做匹配
-
嵌套循环连接( Nested loop join ) Nested loops 工作方式是循环从一张表中读取数据(驱动表 outer table),然后访问另一张表(被查找表 inner table,通常有索引)。驱动表中的每一行与 inner 表中的相应记录 JOIN 。类似一个嵌套的循环。对于被连接的数据子集较小的情况,nested loop 连接是个较好的选择
-
哈希连接( Hash join ) 散列连接是 CBO 做大数据集连接时的常用方式,优化器使用两个表中较小的表(或数据源)利用连接键在内存中建立散列表,然后扫描较大的表并探测散列表,找出与散列表匹配的行。
-
笛卡尔连接( Cross join ) 如果两个表做表连接而没有连接条件,而会产生笛卡尔积,在实际工作中应该尽可能避免笛卡尔积
对于这些连接的详细介绍可以查看《收获,不止 sql 调优》一书,或者查看我做的读书笔记
5.5 explain 参数信息
前面的学习,我们已经知道了执行计划执行的顺序、sql 是做索引,还是全表扫描,或者是 rowid 扫描,但是如图执行计划还有很多参数,如图,比如 Starts,E-Rows,Cost (%CPU)等等,这些参数表示什么含义?
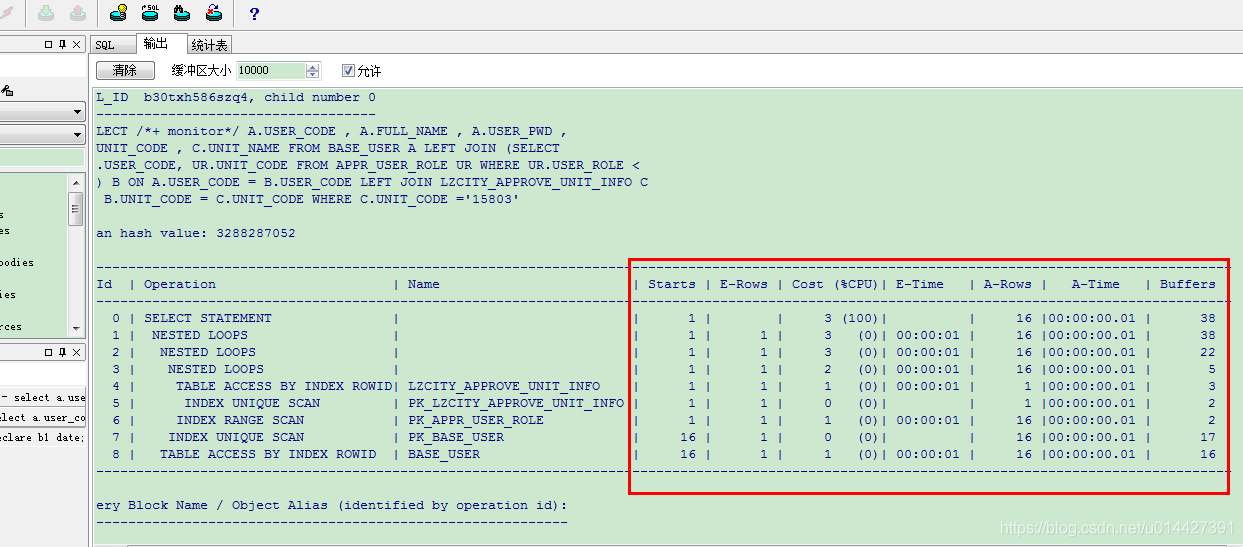 执行计划关键信息介绍:
执行计划关键信息介绍:
- Starts:该 SQL 执行的次数
- E-Rows:为执行计划预计的行数
- Cost (%CPU):CPU cost 在整个 cost 中占的百分比
- A-Rows:实际返回的行数,E-Rows 和 A-Rows 作比较,就可以看出具体那一步执行计划出问题了
- A-Time:每一步实际执行的时间,可以看出耗时的 SQL
- Buffers:每一步实际执行的逻辑读或一致性读
目前尚无回复