
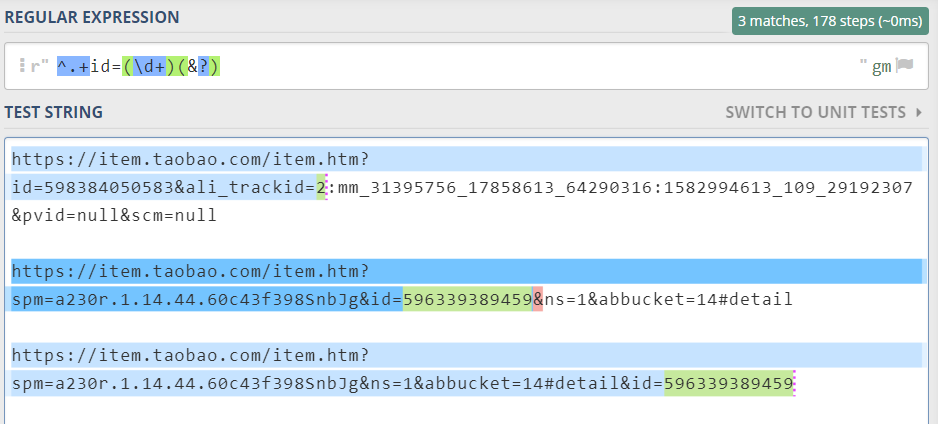
想要提取淘宝商品链接 Url 里的 id,但在下面第一条测试中遇到了些问题,会把后面"trackid=2"也识别进去
我用的正则表达式:
^.+id=(\d+)(&?)
测试 Url 如下
https://item.taobao.com/item.htm?id=598384050583&ali_trackid=2:mm_31395756_17858613_64290316:1582994613_109_29192307&pvid=null&scm=null
https://item.taobao.com/item.htm?spm=a230r.1.14.44.60c43f398SnbJg&id=596339389459&ns=1&abbucket=14#detail
https://item.taobao.com/item.htm?spm=a230r.1.14.44.60c43f398SnbJg&ns=1&abbucket=14#detail&id=596339389459






{kind=link}