
这是一个创建于 2193 天前的主题,其中的信息可能已经有所发展或是发生改变。
以下文章来源于腾讯技术工程 ,作者李海翔
作者:李海翔,网名“那海蓝蓝”,腾讯金融云数据库技术专家。中国人民大学信息学院工程硕士企业导师。著有《数据库事务处理的艺术:事务管理和并发访问控制》、《数据库查询优化器的艺术:原理解析与 SQL 性能优化》、《大数据管理》。
前言
2019 年 10 月 11 日至 13 日,CCF 数据库专委会在济南召开了国内规模最大的、每年一度的数据库学术盛会——第 36 届 CCF 中国数据库学术会议( NDBC 2019 ),腾讯 TDSQL 团队受邀在“数据库产学研合作论坛”,做了主题为“TDSQL 对未来分布式数据库的技术研发思考与实践”的技术报告,与国内数据库学界与业界核心技术人员共同探讨国产数据库面临的基础问题和技术发展方向,助力推动我国数据库技术自主可控发展。与此同时,本次会上,腾讯云数据库技术专家、金融级分布式数据库 TDSQL 团队专家工程师、中国人民大学信息学院工程硕士企业导师李海翔,当选成为了中国计算机学会( CCF )数据库专委会委员。未来,腾讯将加大投入,促进我国数据库产学研合作,推进数据库技术自主可控发展。
本次会议上,腾讯 TDSQL 团队带来了 TDSQL 对分布式数据库技术研发的深度思考与实践分享,主要包括三个方面:
1 ) 分布式事务的效率与正确性,如何在保证双一致性(事务一致性、分布式一致性)的前提下,提高分布式事务型集群的处理效率?
2 ) 新硬件和 AI 等技术,在云环境下,如何影响着数据库的架构?
3 )数据库各个模块间是否能解耦以降低研发的复杂度,同时缩短研发人才的培养周期?
腾讯 TDSQL 数据库的发展历程
TDSQL 是腾讯打造的金融级分布式数据库,对内支撑腾讯公司近 90%的金融、交易、计费类业务。2007 年,随着公司业务再一次腾飞,TDSQL 团队启动了一个 7*24 高可用服务项目,以保障腾讯计费等公司级别敏感业务高可用、核心数据零丢失、核心交易零错账。这也是 TDSQL 的前身。然而,考虑到当时选用的技术方案,技术层与业务层耦合较深。于是,腾讯技术团队开始了研发一款金融级数据库的项目。实现让数据库来解决高可用、数据一致性、水平伸缩等问题,而让业务系统只需要关注业务逻辑。2012 年,标准化的金融级分布式关系型数据库产品 TDSQL 研发完成,并在腾讯内部大规模推广使用。
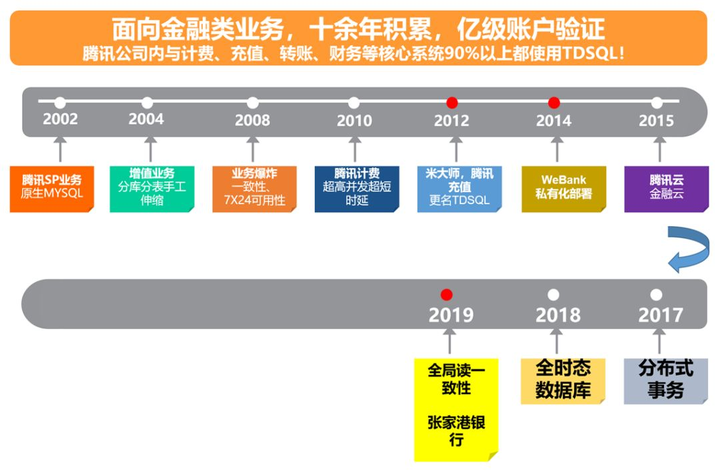
十多年研发演进中,TDSQL 在高可用、分布式方面做持续优化,同时不断提高性能,具备全球部署架构、水平伸缩、企业级安全等特性。
例如,2018 年,TDSQL 实现了原创性提出的全面地解决读一致性的算法,使得分布式事务的一致性和分布式系统的一致性统一在一起。同年,在业界颇为头疼的云数据库运维问题上,TDSQL 还提供了两大利器:“赤兔”运营管理平台和“扁鹊”智能 DBA 诊断系统。
从 2014 年开始,TDSQL 通过腾讯金融云平台对外开放。目前 TDSQL 已经为 500+机构提供数据库的公有云及专有云服务,客户覆盖计费、第三方支付、银行、保险、互联网金融、物联网、互联网+、政务等领域,助力客户业务从国际数据库切换为自主可控的分布式数据库。
今年,腾讯云 TDSQL 助力张家港行成功将银行传统核心系统由集中式数据库存储改造为分布式数据库存储,这是在国内银行首次在传统核心业务系统场景下,采用国产分布式数据库,打破了该领域对国外数据库的长期依赖。
TDSQL 的分布式事务处理技术
首先,我们分享一下 TDSQL 在实现“双一致性(事务一致性、分布式一致性)”,并提高分布式事务型集群的处理效率的探索实践。众所周知,数据库是一个高并发系统,所有的操作通过事务的语义加以约束。而事务的语义,表现为事务的四个特性——ACID:原子性( A )、一致性( C )、隔离性( I )、持久性( D )。而一个数据库系统,其最核心的技术,就是事务处理技术。为了保障 ACID,数据库使用了多种复杂技术,其中,技术的核心是并发访问控制算法。
事务处理技术,有两个初衷:一是数据正确性,二是并发高效率。TDSQL 的分布式事务处理模型,经历了 2 代,第一代采用的技术是 2PL+MVCC,第二代采用的是 OCC+2PL+MVCC。OCC 技术融合了 2PL 以解决高冲突不能高效率的问题,OCC 融合了 MVCC 消除了读写、写读互相阻塞的并发问题进一步提高了性能,自适应的 OCC 使得在 OCC 和 2PL 间动态自动切换,使得分布式事务处理机制更聪明。
但是,这些还不足以体现 TDSQL 如何着手提高分布式事务的效率。在架构上,TDSQL 是去中心化的架构,没有集中式单 Master 那样的处理分布式事务的单点瓶颈,事务协调器间传递相关联的分布式事务控制信息量被优化,分布式并发访问控制算法的冲突粒度控制在数据项一级从而提高了事务的并发度,因而效率更高。另外还有很多其他方面的优化,使得 TDSQL 的分布式事务处理效率较高。
而我们继续探讨,如图 1,在分布式背景下,怎么实现“双一致性(事务一致性、分布式一致性),并提高分布式事务型集群的处理效率?
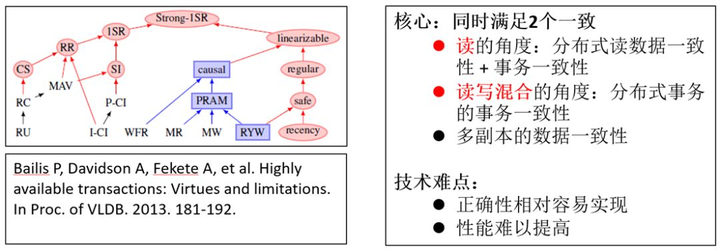
图 1 实现分布式事务面临的问题
该问题,是业界一个难题。Google 的 Spanner 系统实现了双一致,但事务处理的效率很低。TDSQL 在深入研究分布式事务处理的技术时,不仅解决了全局一致性问题( 2019DTCC 大会分享:分布式数据库全局读一致性),而且提出了一个“统一致性模型”,不仅在正确性上实现了双一致的功能,而且高效地解决了该问题。
在 TDSQL 看来,双一致性的正确性相对容易实现(尽管这也是一个很难解决的问题),但分布式事务型数据库的性能难以有效提高。
那么,有哪些因素,制约着分布式事务型数据库性能的提高呢?
如图 2,一些研究者认为,是网络带宽限制了性能;一些研究者认为,制约分布式事务型数据库性能的提高有 2 个因素,一是“latency”本身,二是“latency”延长了事务的生命周期,而长的事务生命周期导致并发事务发生冲突的概率增大,进而引发事务回滚降低了性能。

图 2 分布式事务的瓶颈
另外,影响正确性和性能的,是事务处理技术中的核心技术——并发访问控制算法。
如图 3 所示,实验表明,在事务型数据库中,OCC 算法效率更高,在多核环境下,OCC 算法比 2PL 算法性能高出 170 倍。但是,高的并发冲突下,OCC 的回滚率增加,表明 OCC 算法的缺点也很明显。
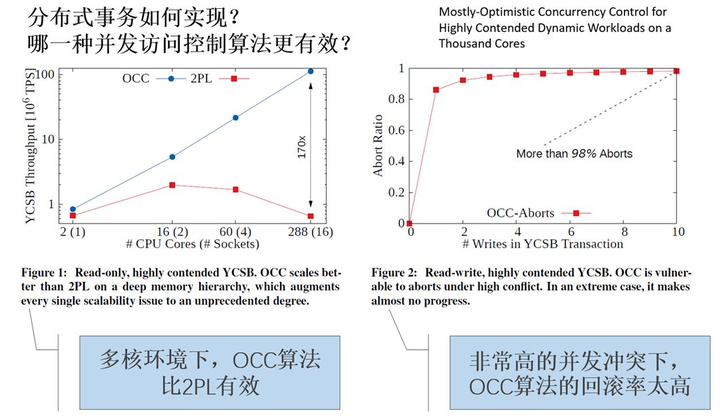
图 3 并发访问控制算法的优劣
但是,还有研究者对于多种并发访问控制算法进行了较验证,如图 4,发现传统的 OCC 算法比很多种知名的改进的 OCC 算法(如知名的 Tictoc、自适应的 OCC 等算法)更有效。这表明,不同人实现的不同的系统尽管采用了一样的算法思路,但是实际效果却大不相同(如 Tictoc 自身的测试结果表明其改进的 OCC 算法效率好于传统的 OCC 算法)。所以,我们在思考,不同实验得到不同的结论,其背后,真的影响分布式事务的效率的因素究竟是什么?
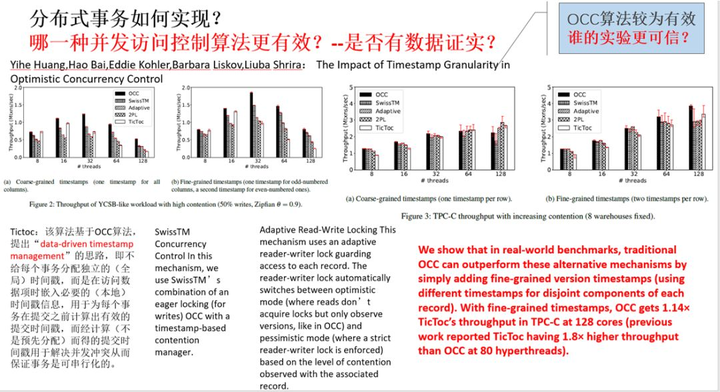
图 4 多种并发访问控制算法的比较之一
进一步探讨,如图 5 所示,不同研究者表明,自适应的 OCC ( OCC+2PL ),有着更好的性能(图 5 中间的子图)。综合图 3、图 4 和图 5,其实可以发现,不同的研究者的验证结果,是不能互相推证的,他们的验证结果,只能表明算法之间的大致趋势(如 OCC 性能会比 2PL 更好一些)差异,但不能精确表明算法之间的差异点究竟在哪里。
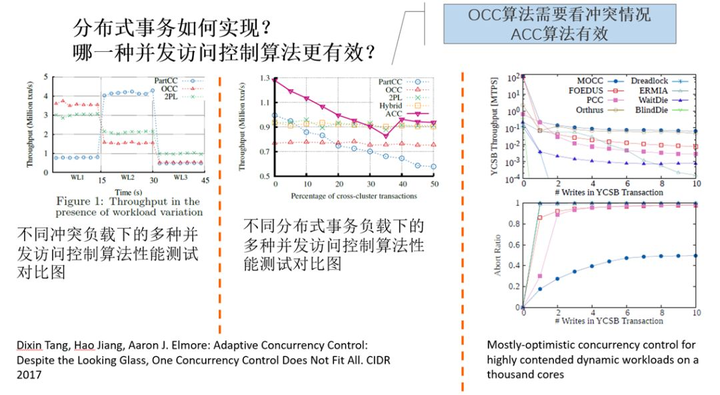
图 5 多种并发访问控制算法的比较之二
再对比图 6,腾讯在 MySQL 上做了热点更新功能,发现在高并发高竞争同一个数据项的情况下,影响 MySQL 性能的,不是 2PL 这个算法本身,而是为解决死锁问题时死锁检测算法消耗的 CPU 资源,故 MySQL 的事务吞吐量近乎为 0。禁止了死锁检测后,并用系统锁(非事务锁)互斥了在同一个数据项上的并发竞争后,MySQL 系统事务处理吞吐量上升的万倍左右。
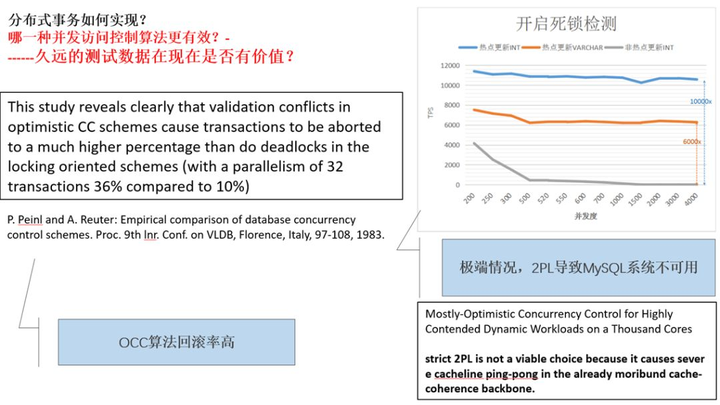
图 6 真实系统下的真实问题
这说明了,在不同系统下实现的相同算法的结果,只具有参考价值。如果在实际系统中,如 MySQL、PostgreSQL 中做实现,才更有实际参考意义。
分布式数据库的架构与解耦
TDSQL 团队在研发分布式事务型数据库的过程中,除了思考分布式事务处理技术( ACID 实现的所有技术)外,还深度探索测试验证、架构扩展、模块解耦等等各种重要的问题。新硬件和 AI 等技术,在云环境下,如何影响着数据库的架构?
数据库各个模块间是否能解耦以降低研发的复杂度,同时缩短研发人才的培养周期?
新硬件和 AI 等技术,从架构上深深地影响了传统的数据库,这表现在如何融合这些新技术:
- 首先,数据库可能会“增加”很多新模块进去,如图 7 中的左下子图,AI 调优数据库技术使得数据库系统被扩展了,增加了很多新组件进来。
- 其次,数据库的传统模块会被改变,如图 8 中的左下子图,在并行的事务型数据库系统中,提出基于 AI 技术对事务进行优化的模型。该模型采取存储过程的方式(此点类似 H-Store、VoltDB ),向数据库引擎提前提供所执行的事务,然后利用 AI 技术( Markov model,马尔可夫模型)对存储过程进行分析,确定那些存储过程所代表的事务间的语义,排定事务并发执行时哪些是互相冲突的,得到一个有固定结构的事务执行模型,如图 8 左下子图中右侧,是对 TPC-C 模型 NewOrder 进行的分析得到的事务调度图。
当多个 Client 发出 SQL 语句执行存储过程代表的并发事务时,据此模型即能推断事务的调度方式。这是 AI 技术改变事务处理中并发访问控制模块的一个典型事例。
图 8 中的右上子图,是 RDMA 对于事务处理技术的影响,该图展示了四种模型,其中“d”模型是基于 RDMA 从 2 个方面对事务处理构成影响,一是事务处理的控制流,二是事务执行过程中发生的数据流。影响分布式事务处理效率的,不仅仅是庞大的数据流,而相对数据量小的控制流,也是瓶颈,因此需要引入 RDMA 来加以解决网络带宽瓶颈。

图 7 数据库架构发生变化

图 8 数据库中的模块发生变化
传统的数据库系统,其复杂度极高,从外看高内聚,从内看高耦合,这使得数据库的复杂度骤然提升。当各种新技术产生,影响了数据库的架构时,数据库的复杂性被再提上一个台阶。在这种背景下,研发人才的培育,其成长周期就会更长。因此,我们在思考的一个问题是:从技术上看,如何解耦数据库内部间的诸多模块?耦合度高,研发人员需要掌握数个相关模块才能良好推进工作;如果模块间解耦较好,掌握单个模块就能方便推进工作,这样人才的培育周期相应也会缩短,软件的质量也会得到提高。
所以,数据库架构背景下各个模块解耦问题,是一个技术问题。解耦工作,可以在许多层次、许多模块间展开。解耦技术,各有其妙。
如图 7 右上子图所示,AWS 的 Aurora 提出的存储计算分离,就是存储和计算两大模块的解耦。而微软 Deuteronomy 系统在 08 年-16 年也有过一系列相关工作。Deuteronomy 一开始采用的方案是在存储层上面实现事务,而底层的存储采用的是 KV 模型。存储层只需要提供 KV 的原子性和幂等性,上层就可以比较容易实现事务的并发访问控制和恢复。后来的 Percolator、Spanner/F1、CockroachDB、TiDB 其实也是沿着这个思路在发展,底层是 Bigtable/Spanner 或者 RocksDB 这样的 KV 存储引擎,在存储之上封装一层事务。但是在类似 RocksDB 这样的 KV 存储中,对于 KV 记录的并发控制还是和存储紧耦合的。
存储和计算两大模块的解耦,促进了各自所囊括的子模块之间再次进行解耦,如图 9 所示,事务和存储层的解耦,该怎么进行?有的研究者,把事务处理功能提取到客户端进行(图 9 左子图),有的把事务处理功能放到中间件层实行按(图 9 中间子图),这 2 种方式不同于传统的在 Server 端进行事务处理(图 9 的右子图)。

图 9 事务和存储层解耦
另外,解耦工作,其实无处不在。图 10 展示了算法与数据结构之间的解耦。图 10 的左子图,是数据库的持久化部分和内存中数据之间的设计解耦。
图 10 的右子图,是索引的数据结构与物理存储层之间的解耦。 图 10 的左子图,对应 VLDB 2018 的论文"FineLine: Log-structuredTransactional Storage and Recovery",提出了一种事务存储和恢复机制 FineLine,舍弃了传统的 WAL,把所有需要持久化的数据存储到一个单一的数据结构,希望将数据库的持久化部分和内存中数据存储之间达到设计解耦。
FineLine 无需将内存中数据落盘到 DB,仅将内存中的 log 信息持久化到 Indexed log 中,然后通过 fetch 操作从 Indexed log 读取到数据的最新状态。通过将内存中的数据结构与其持久性表示尽量地解耦,消除了与传统基于磁盘的 RDBMS 相关的许多开销。除此之外,这种单一的持久化存储架构带来的另一个好处是,在系统发生故障后恢复的开销很低。由于 Indexed log 保持了与原子操作的一致性,当发生故障并重启时,可以从 Indexed log 中读取到已提交的最新数据记录。基于 no-steal 的策略,Undo 操作,Checkpoint 这些也都不需要。

图 10 计算与数据结构之间的解耦
数据库内部,各个模块之间的解耦,与模块粒度的划分,与具体实现的系统,都有密切关系。如图 11 展示了几个主流数据库之间解耦的关系,期待能抛砖引玉,引发更多思考。
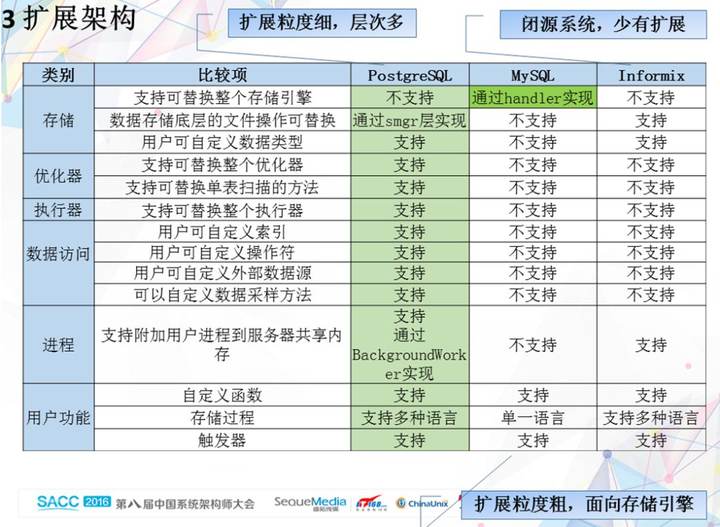
图 11 主流数据库解耦的比较
结语
数据库作为核心基础技术之一,在自主可控的时代发展潮流下,是我们必将要跨过的大山。路虽弥,不行则不至,历经十数年的研发演进,至少今天我们都已达成了许多重要的里程碑。当下而言,国产数据库从技术、人才、工业生态等各方面,都有待完善和发展,而未来更紧密的产学研结合、科技与传统产业融合趋势下,将进一步促进数据库自主可控发展。
江湖召集令
9 月 27 日-11 月 6 日,腾讯云数据库王者挑战赛(点击查看详情) 等你挑战!花几分钟参加比赛免费将☟☟抱回家!- MacBook/iPhone 11/AirPods
- 25 台 Kindle
- 8 万元腾讯云创业基金
- MySQL 之父 Michael Widenius 面对面交流
转发下方海报参与活动可以获得腾讯公仔和腾讯云数据库无门槛代金券,详情请扫描下方图片二维码咨询。

比赛详情&报名入口
请扫下方二维码

点击优惠购买腾讯自研数据库 CynosDB
 |
1
RedisMasterNode 2019-12-25 10:51:20 +08:00
江湖召集令
9 月 27 日-11 月 6 日 虽然对活动很感兴趣 但是我有 5 点想说 ...... |
 |
2
onhao 2019-12-25 17:40:30 +08:00
@RedisMasterNode 多了一点
|