V2EX = way to explore
V2EX 是一个关于分享和探索的地方
Sign Up Now
For Existing Member Sign In
如果想在 V2EX 获得更好的推广效果,欢迎了解 PRO 会员机制:
https://www.v2ex.com/pro/about
https://www.v2ex.com/pro/about

This topic created in 2723 days ago, the information mentioned may be changed or developed.
张观石,拥有 10 余年网站开发、架构、运维经验;目前关注互联网服务可靠性系统工程、运维平台的规划建设、网站高可用架构等方面;在音视频传输质量评估、微服务运维方面积累了丰富的经验。
目录 一、 直播平台的架构及运维挑战 (一) 音视频传输流程及挑战 (二) 一个直播间的流程 (三) 直播平台的运维挑战 二、 我们的思考和运维实践 (一) Google SRE 介绍 • SRE 是什么 • Google SRE 方法论 (二) 我们的思考:运维的六种能力 (三) 我们的运维实践
- 运维可靠性管理
- 感知能力
- 修复能力
- 反脆弱能力
- 保障能力
- 安全能力
虎牙直播介绍
虎牙直播是以游戏为主要内容,涵盖娱乐、综艺、教育、户外、体育等多种内容的直播平台,2018 年 5 月在纽交所上市。 虎牙算是整个直播行业比较重视技术的一家公司,大家可以对比下几家平台观看体验,我们应该是最好的一家了。英雄联盟 S8 是全球最大的电子竞技赛事,目前正在如火如荼进行,从今天开始进入了总决赛的淘汰赛阶段了。这会正在进行的是 IG 对 KT 队,IG 是中国的队伍,今年共有 3 只中国对进入了 8 强,是历年最好的成绩,比赛很精彩,如果不来今天的分享,我可能在家看比赛,或是去公司值班了。欢迎大家到虎牙直播平台观看直播,为 LPL 加油!(发布此稿时,中国队 IG 已经获得了总决赛冠军,虎牙平台观众数也突破了历史新高,直播过程无较大故障发生)。
今天的分享正好会讲到关于这次赛事的运维保障的技术。
一般网站比如电商类网站用户是卖家+买家, 卖家先编辑商品信息,发布后买家刷新后再看到,是异步的,卖家可以慢慢改,错了可以慢慢调。直播平台上,一个主播开播出现在摄像头面前,可能有成千上万的人同时观看,主播不能有任何小动作,不能离开,重新开播代价太大了,10 分钟不能播观众就跑了。要是互动不流畅,土豪也就不想看你了。主播更不可能停播配合我们运维人员做一些技术上的调整。如此看来,直播平台相对于传统网站还是有区别的。所以,这对运维的挑战就更大。 直播平台技术是比较复杂的,首先是音视频处理本身有很多高深的技术,其实是大规模的观众和主播,还要对实时性要求特别高。 今年英雄联盟总决赛 S8 是从韩国现场传送回国,传输路径也比较复杂。
一 直播平台的架构及运维挑战
(一)音视频传输流程及挑战
音频流程是指平台从开播到观看一系列的流程。 https://s1.ax1x.com/2018/11/12/iLlDL8.png
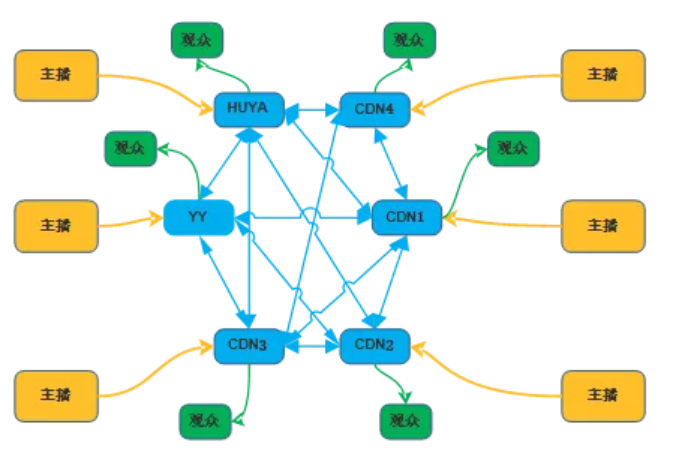{kind=link}
①开播主播多 同时开播的主播数量非常多。 ②上行选择多 图中,中间蓝色部分的线是可以支持上行的线路,每一个主播都可以到任何一条线路上,虎牙有自动调度,运维人员也可以进行调度,主播上行哪里。 ③ 转推路径多 确定一条上行线路后,还要互相转推到其他线路上,观众可以在任何一条线路看到主播的直播。 ④观众线路多 观众有很大的选择权,比如选择不同的清晰度、不同的线路,包括 H5 技术等,播放技术和观众选择不一样。 ⑤转码档位多 ⑥实时要求高
今年,虎牙运维研究团队又做了 P2P 技术,架构又比以前复杂了很多。
(二)一个直播间的流程
https://s1.ax1x.com/2018/11/12/iLl6oQ.png 上图是一个虎牙主播直播的流程。首先,主播可以选择一个开播方式(进程开播、桌面直播、摄像头开播、手游投屏、手游桌面、OBS、导播系统、VR 直播、第三方推流等)进行直播,经过 4 种推流方式( HUYA、UDP、YY、RTMP、CDN ),直推到某条线路上,转推多家 CDN,从 CDN 边缘到中心,然后再选择转码率,最后分发到不同省、市的运营商,之后就到观众的客户端。
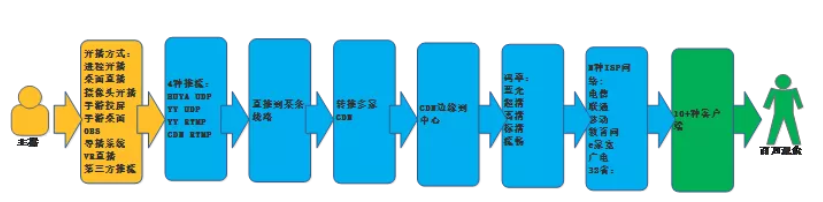{kind=link}
(三)直播平台的运维挑战
因为音视频本身的复杂度,加上业务的实时性,对运维造成很大的挑战。传统的运维可以对开源组件做部署、配置、优化、高可用部署等。而音视频技术变化很快,自成一个体系,主播端和观众端的逻辑性强,由于中间传输路线多,运维人员很难参与其中,所以我们必须换一种工作方式。 google 的 SRE 给了我们很大的启发,我们在 SRE 的方法论指导下,比较深入地参与到了音视频传输业务中,虽然我们不叫 SRE,还是叫业务运维,不过做法吸收了 SRE 的很多思路。 今天要分享的也是这方面的内容,希望对大家有些启发。
二 我们的思考和运维实践
(一) Google SRE 介绍 • SRE 是什么 S 是 Site/Service/Software,运维的对象,网站业务服务线上的服务 R 是 reliability,关注可靠性,质量,理解为对外部最终用户的质量和价值 E 是 Engineer 工程师、Engineering 工程化。 运维的本质是人和机器参与的一项系统性工程,这种工程跟软件工程不太一样的是,我们是负责业务上线后稳定运营,可靠性、质量、成本等。有人比喻业务研发和运维的关系就像是:生孩子与养孩子,哪个更难哪个更容易呢? • Google SRE 方法论: •关注研发工作,减少琐事
•保障 SLO&度量风险 •做好监控及黄金指标 •应急事件处理 •变更管理 •需求预测和容量规划 •资源部署 •效率与性能
(二)我们的思考:运维的六种能力
常有人问我们运维是做什么的,我们说是做质量、效率、成本 ,具体怎么做,要怎么做呢,几句话很难讲清楚。《 SRE Google 运维解密》这本书强调实践方法论,能落地,但不够体系,可能是由不同的人写不同的章节。我有机会顺着可靠性这条路径,找到了传统行业的可靠性研究,发现了另外一片世界。大家都以为 SRE 是 google 提出来的,其实传统行业的 SRE 已经存在了几十年了,已经成为了一门学科。我个人研究之后,认为这门学科讲得更体系更完整,于是希望能套到互联网的服务中来。我参照照传统行业一些可靠性的理论、对框架做了一些迁移,将自己的思考转化成了一个运维的思考框架,叫做运维的六种能力,将其分为以下 6 点: https://s1.ax1x.com/2018/11/12/iLl2Js.png SER 眼中的可靠性:规定条件规定时间内完成规定功能 可靠性的两个故事: 二战时某次美军近半飞机无法起飞,发现是某些电子管不可靠引起的。朝鲜战争中美军电子设备不可靠,维修成本比制造成本高了几倍。从而诞生了可靠性这门学科。
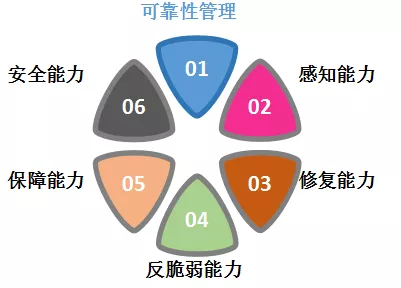{kind=link}
①可靠性管理
首先要分析目标业务的可靠性模型,然后画出可靠性逻辑框图,评估每个环节和总体的可靠性性,进行度量和评价,可以是定性的,也可以是定量的。 ②感知能力 在业务上线、建立连接之后,学会如何感知其状态、变化及问题。
③修复能力 当可靠性在设计阶段不够完善时,修复能力可以帮助我们在用户没有感知的状态下修复故障。 ④反脆弱能力 业务运行在一定内部或外部环境里,寻找脆弱点和风险点,然后对它的脆弱点进行分析,并设计出反脆弱的能力,最终推动业务研发修改技术架构。 ⑤保障能力
很多业务需要具备保障能力,建立保障性的设计,实现快速交付资源和快速能力到位。 ⑥安全能力 如何保证我们业务安全、数据安全。
(三)我们的运维实践
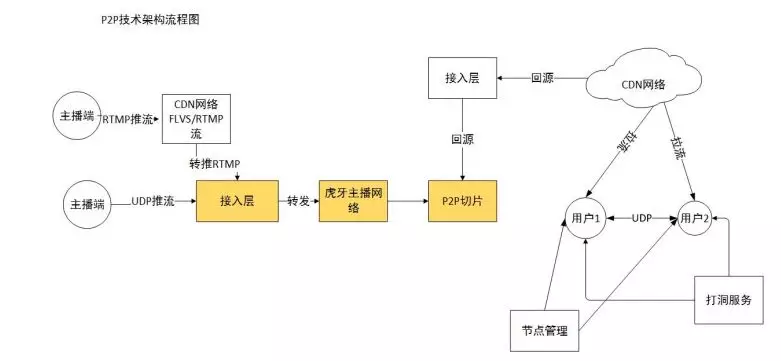
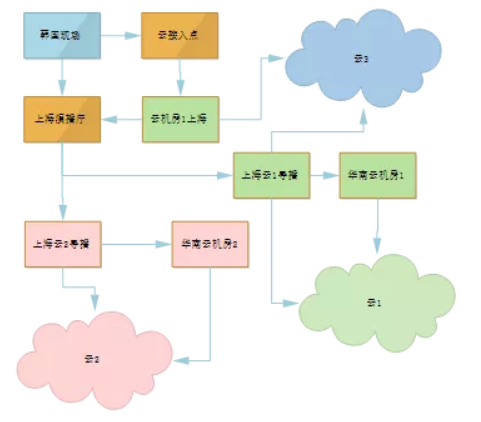
我们主要关注所负责业务的核心服务的核心指标,我们将每一条端到端链路都看做是一个服务,那么服务指标可以是成功率、延迟或其他,将指标能达到某个程度作为目标;研发和运维团队会对这个服务画出部署构架图、可靠性逻辑框图(见下图);建立业务的可靠性模型,同时还会做一些 FMECA ;分析失败模式及其带来的影响,以及讨论设计解决方案;对一些关键的服务,要把故障树画出来,度量风险,选择优先风险,推动解决;可靠性是管理出来,是运维出来的,但首先是设计出来的,可靠性设计的方法包括避错、改错、容错等。 https://s1.ax1x.com/2018/11/12/iLlRWn.png 下图是我们负责运维的同学画的 P2P 技术架构流程图。 https://s1.ax1x.com/2018/11/12/iLlWzq.png 下图是主播上行经过的环节,这对运维人员做监控时有指导意义。逻辑框图越画越细,每个点都会分析、统计它的可靠性。 https://s1.ax1x.com/2018/11/12/iLloeU.png 1.可靠性管理的要点 ①如何识别风险 可以从几个方面判断: 复杂度;技术成熟度;重要程度;环境严酷程度 ②如何验证可靠性水平 开发阶段前性能测试;上线压测;容量模型;改进测试;模拟故障测试等 ③实践 建立可靠性指标大盘;黄金指标&SLO ;主播上行 APM ;全链路的可靠性;多维度的析评估体系;日报,月报,实时可靠性等。
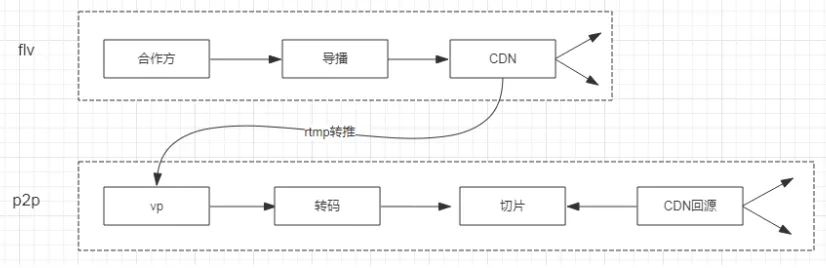{kind=link}
{kind=link}
{kind=link}
2.感知能力 什么是感知力,包括但不限于监控的覆盖度,告警的实时性,准确性,触达率,问题定位能力,趋势预测能力 。 ①监控、状态感知能力 以监控数据作为基础,提高人工感知能力和机器感知能力,监控是感知的基础,监控指标多了,不能说就有了感知力,这远远不够。 ②故障感知能力
帮助运维人员感知业务的状态、变化和其他问题
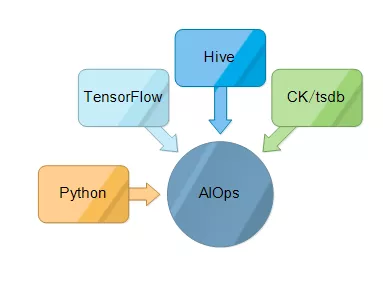
④AIOps 大多是加强运维感知能力 大数据;智能告警 自动化测试、压力测试 拨测、APM 日志 trace 可阅读,可分析
https://s1.ax1x.com/2018/11/12/iLlTwF.png 3.修复能力
{kind=link}
SRE 是与故障做斗争的系统工程。程序写得再好,也很难达到完全不出故障。 衡量修复能力-MTTR: 对于大部分的故障,都应该知道它的故障模式,根据故障模式就可以制定故障预案(规定条件规定时间规定人进行修复),根据预案做出一些修复工具,即人工修复或智能自愈。当发生一些考虑不到的情况出现时,需要维修和技术保养,进行扩容或者优化。根据平均修复时间和最大修复时间进行修复评价。 虎牙的一些实践: 主播上行切换:从早期主播重新开播修复上行问题,到后台手工切换,到主播端自动切换。修复时间( MTTR )从半个小时缩短到 5 分钟,到秒级。 观众调度系统:基于主播端,观众端调度,小运营商调度、无缝切换,按协议调度等,机房一键上下线。 故障修复更高一级是自愈,这也是故障修复能力转化为软件架构设计的高度。
4.反脆弱能力 反脆弱的设计: 保证服务在脆弱条件下的保持容忍范围内的健壮性。 软件总是在不同环境运行、不同条件下运行,这个条件就是可靠性中“规定的条件”。环境总是有很多脆弱点,要做脆弱性分析、反脆弱设计,最后评估评审。互联网常见的脆弱性因素,有机房、运营商、网络、单机故障,业务突发事件负载高、流量大,也可能微服务请求超时。健壮性设计,容灾性设计、高可用的设计、资源冗余等。这也是 google SRE 种说的拥抱风险、度量风险、评估风险容忍能力。
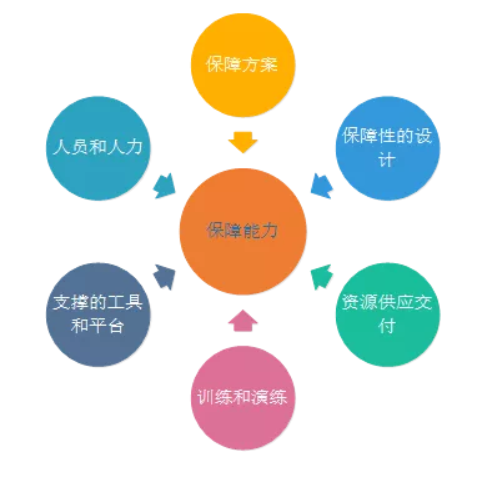
S8 源流的反脆弱性设计 https://s1.ax1x.com/2018/11/12/iLl7o4.png 5.保障能力 软件架构设计特性和计划的保障资源,能快速满足使用要求的能力。 https://s1.ax1x.com/2018/11/12/iLlvy6.png 可靠性保障的设计,要做到无状态,可切换,可调度,可重试等,比如说我们怎么样实现替换一台故障机器,且要求在 10 分钟内提供业务服务。 做可靠性保障要做一个闭环,分析目标、风险、脆弱性;设计 SLO-感知还有保障、修复、演练。感知 SLI 的变化以及相关的子 SLI 的变化,尽快修复 SLI 退化情况,在设计时尽量考虑到各种脆弱条件,做出反脆弱的保障方案。
{kind=link}
{kind=link}
我们的一些实践: •带宽资源保障: 能分钟级实现带宽调度,能 1 分钟内实现切流 •服务器保障: 3 分钟能拿到多个机房服务器 3 分钟能把核心服务部署起来 保障能力需要架构设计、接口的设计 我们在直播间的做了一些特殊设计 保障能力是多方面能力的综合体现: •考验的是自动化的程度,要有支撑系统的保障,要有自动化工具的保障 •要做人力和人员的规划,考验故障时人员到位时间 •要做硬件、软件资源的供应保障 •是对软件架构的要求,是否支持平滑扩容 •要有演练,确保能执行 6.安全能力 安全是最基本的能力,也是最大的风险之一。 数据安全:层出不穷的数据泄露事件,用户信息涉密事件。 业务安全:优惠券被刷,支付漏洞,主播言行、登录风控等。 用户安全,比如滴滴的安全事件。
以上内容来自张观石老师的分享。
由 msup 主办的第七届 TOP100 全球软件案例研究峰会将于 11 月 30 日至 12 月 3 日在北京国家会议中心举行,张观石老师将作为大会讲师为大家带来《直播平台的运维保障实践》话题。
案例目标
相对于 Web 服务,直播音视频的运维更特殊,业界没有很好的参考的经验,刚接手时,这方面运维的挑战比较大。
( 1 )虎牙直播目前是异构多云的架构,从整个链路看,任何观众都可以看到任何线路上任何主播的情况,复杂度高; ( 2 )研发人员以及各个团队会比较关注自己环节上的事情,所以在虎牙运维团队引入了多 CDN 以后,不仅技术和管理复杂性大幅提高,而且视频流路径在这么复杂的场景下,必须深入音视频运维工作,这对运维质量和运维人员技能提出了更高的要求。
成功(或教训)要点
直播音视频的传输质量评估体系,音视频质量数据的全链路监控,以及对于互联网服务可靠性系统工程的思考。
案例重点
运维效率的提升,直播质量的提升。
案例启示
由于直播平台不同以往任何架构的特殊性,以及当时视频板块技术的有限性,促使我们必须尽快找到运维的着力点。后来,我们接轨了近年来一直倡导的 DevOps 和 SRE 解决了这一困局。 https://s1.ax1x.com/2018/11/12/iL1SeO.png
{kind=link}
No Comments Yet