
先上代码 github,这个项目现在仍然在积极开发和维护的阶段,通过这个项目你可以组建自己的集群并且训练自己的中国象棋 alpha go:
icyChessZero
中国有 13+亿人,中国象棋的受众也很广,但是有关中国象棋 alpha go/zero 方面的开源项目其实并不多,国内有名的更是几根手指都能数过来,而且在内容上高度相似,都是使用 alpha zero 的网络 + alpha go 的训练方式,列举两个相对突出一些的:
- 佳佳 zero: 是一个团队在维护,把 Leela Zero(一个国际象棋 alpha zero 项目) 迁移来做中国象棋的项目,目前就 elo 分来说是最强的,有那么一丢丢商业化趋势
- cczero: 几乎只有一个人在维护代码,同样是一个民间自发组成,维护的中国象棋项目,目标是最强开源项目 这两个项目都是比较棒的,那么为什么我还要自己写一个呢?这就要从更早说起了
早在 alpha go 出来之后,alpha zero 出来之前,我就有要用神经网络来做中国象棋的想法,不过那个时候其实大家都不太知道怎么做这个东西,毕竟象棋和围棋很不一样,我当时写了一个比较幼稚的网络,希望单纯通过一个网络,不加任何类似蒙特卡洛的算法来通过预测人类落子规律的方法来,毕竟在围棋中一个单纯的策略网络就可以达到业余几段的棋力水平,我追求的也并不是天下第一,业余几段对于我来说,很 ok。
当时写爬虫爬了很多国内比赛棋谱,包括了很多我们耳熟能详的象棋大师的比赛,然后开始自己训练一个网络来预测人类的落子:
这个是我当时实现的那个很 naive 的网络代码:
icyElephant

我当时的方法是使用 2 个网络来预测人类的一步,一个叫做 select 网络(图 1 中的网络 1 )负责预测人类会移动哪个子,另一个叫 move 网络,负责预测移动的子落子点在哪里,对比 alpha zero 的方法,alpha zero 使用一个网络就完成了两个工作:

从直觉上来说,似乎先预测选子,再预测落子的网络逻辑更符合人类的思考过程,然而这两个网络,在实际使用真实对局数据训练时准确率相差非常小:

并且我当时的方法( select-move 网络)不适合用在蒙特卡洛树搜索中预测每个走法的概率,所以后来在写 icyChessZero 的时候也是用了 alpha zero 的策略网络的形式。在训练完这个网络之后,我发现,虽然象棋走法预测的准确率也不算很低,但是单纯和这个预测走子的网络对弈,我发现这个网络虽然开局有模有样,但是一旦到了中局和残局,网络经常作出匪夷所思的送子行为,这个现象我认为是因为围棋和象棋的差异性造成的,由于围棋的局势更适合直接从棋盘评估(所谓的“势”),而象棋则更多涉及逻辑推理。
到这一步为止,其实还是有很多项目都可以做到,比如说之前知乎有一篇系列文章:
ENG Bo:28 天自制你的 AlphaGo
叫 28 天自制 alpha go 的文章(虽然这个系列文章后来太监了,作者卖灯去了,估计是因为算力不够),但是再往下做的话,其实是有一定门槛的,使用蒙特卡洛树进行子对弈,并且进行神经网络的增强学习训练,需要巨大的算力,这个门槛,其他的开源项目一般是通过众筹训练的方式解决的,比如 cczero 和佳佳 zero,但是有越过这个门槛的,也就有没越过这个门槛的,比如之前知乎上的另一个项目:
程世东:AlphaZero 实践——中国象棋(附论文翻译)
这个项目就因为训练增强学习所需要的巨量资源所限制,虽然代码写出来了,但是因为算力不够,作者在烧了几百美元之后只能作罢。
那么我是怎么面对这个问题的呢?我利用了我在校生的身份,把手深到了我能够到的每一台 gpu 机器,求爷爷告奶奶的搞到了四五台机器,组了一个集群,虽然仍然算力不够,但是至少可以开始训练了。
想要从根本上解决这个问题,只能用巨量的算力,但是我们也能通过一些提高效率的方法来缓解一些这个问题,一些常用的方法比如:
- 使用 c/c++ 加速代码
- 使用多进程同时跑多个网络的前向
- 使用协程来将多个前向组成 batch,提高 gpu 利用效率
- 使用协程 /多进程的蒙特卡洛树算法,提速蒙特卡洛树的搜索速度
- 使用多台机器分布式跑棋谱,利用更多 gpu
除了 C/C++加速的方法我还没有使用,其他的方法我都使用了,细节参考:
在实现了使用蒙特卡洛树搜索走子的功能之后,我让监督学习的网络 和 监督学习+蒙特卡洛树的两种算法进行了对战,结果如下:
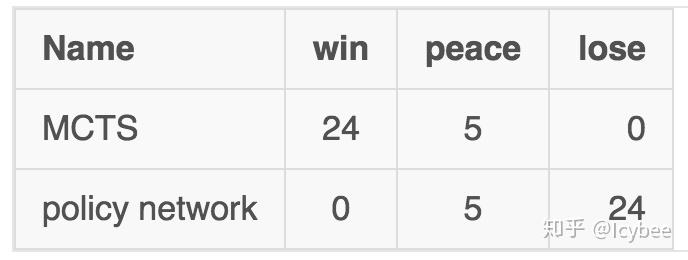
在 29 盘对局中,蒙特卡洛树一盘都没有输,平的 5 局都是超出当时的步数限制( 100 步,为了节省时间)判和的,判和时无一例外都是 mcts 优势。这明确证明蒙特卡洛树能够有效提升 policy 网络的棋力。
这个项目原理简单,但是实现起来全是逻辑,我从三月(存疑)开始写,一直没时间写,断断续续的写,5 月跑了几天,出了一些 bug,后来一堆事情又涌上来,这项目就又搁置了起来,到 7,8 月,我意外的发现终于又有一些时间了,于是终于,我完成了我的中国象棋 alpha go zero 的第一版。
然后开始了漫长的训练过程,由于我的算力非常有限,到目前为止也只是一个 4,5 台 gpu server 的集群在训练这个版本的 alpha zero,我一开始的评估结果是以实验室的资源大概至少 10 年能跑出来吧,后来随着计算越来越精确,我发现在短短一年,甚至半年之内完成训练是很有可能的(我的目标只是达到中上人类水平,由于收到算力和时间的限制),但是一台机器肯定不够,需要有很多机器,于是我写了分布式版本,甚至花了一周时间重构了很多代码,这次重构以后一些 bug 莫名其妙的消失了,elo 曲线总算开始正常上升。


ps 一句:如果你在北邮有闲置的 GPU 服务器的权限,又有意愿加入集群一起训练,希望能够联系我
我认为,并不是只有训练出一个最强的网络才是有价值的(当然如果有资源能够训练最强的我也不介意 [手动捂脸] ),探究在这个训练过程中的优化点,考究 alpha zero 这个强化学习过程中是否有不合理的地方,这些都是有价值的。
这次开源的代码同时包含了集群 master 和 slave 的代码,一个组建集群的 minimal sample 我已经上传到了 google drive:
这个 minimal sample 可以直接用 google colab (免费)运行,只要把这个文件存到自己的 google drive 之后用 colab 打开就行(注意开启 gpu 加速):

在 google colab 中运行这个 minimal sample 的所有代码,应该能够看到类似下面的结果,说明一个随机的权重已经被初始化并且用于蒙特卡洛树的子对弈:

根据其他项目的进度和情况,想要达到我的小目标应该需要 4000 ~ 5000 elo 的分数,现在这个项目已经达到了 700elo 左右的分数,所以达到目标并不是不可能的。
另外这个项目参考了很多同类项目的实现,比如:
https://zhuanlan.zhihu.com/p/34433581
https://github.com/junxiaosong/AlphaZero_Gomoku
写这个项目的目的也是希望在探索的路上多走一条道,多一个人。
最后给其他对 alpha zero 算法感兴趣的人一点建议:
如果没有足够算力的话,没事不要碰象棋,围棋这种复杂游戏,可以从五子棋这种简单游戏入手训练,五子棋这种简单游戏对算力的门槛要求会低很多。
另外,如果想探讨一些技术问题可以站内私聊,评论,或者通过 [email protected] 联系我







