
这是一个创建于 3116 天前的主题,其中的信息可能已经有所发展或是发生改变。
比如说,我基于 1996-2005 年的数据,拟合了两个模型, 得到拟合优度如图
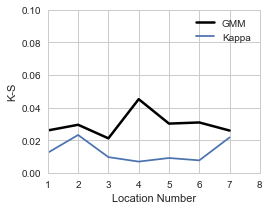
可以看到GMM 是比Kappa略差的 (越接近 0,拟合效果越好)
但是,数据本身是有变动性的,实际上可能值在 0.05 以内就已经很好,再低已经没有价值
这个时候,拿着拟合的模型,对未知数据(2006-2015),计算拟合优度
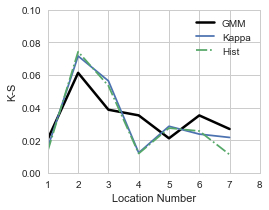
即可发现这个现象
简单来说,也就是
-
考虑数据本身变动性(非平稳性)的情况下,对于拟合的要求不能过高
-
两张图的结论,也从 Kappa 比 GMM 略好,变成了两者都足够好
我的问题:
-
我自己不是学统计的,想问下有什么比较专业的方法可以用来分析、阐明这个问题?
-
比如,对比数据本身的变动性(不考虑时间因素),可以用 Bootstrap, 重复抽样来研究
 |
1
27 2017 年 10 月 14 日
这是在说其中一个模型过拟合了?
|

|
3
27 2017 年 10 月 14 日
一般在训练过程中的拟合结果是不能证明模型的优劣的,需要拿到测试集上跑结果才能看出来
不太了解你这两个模型是什么,假如测试效果一样的话,那么更简单的模型更好,因为泛化性更强 |