推荐学习书目
› Learn Python the Hard Way
Python Sites
› PyPI - Python Package Index
› http://diveintopython.org/toc/index.html
› Pocoo
值得关注的项目
› PyPy
› Celery
› Jinja2
› Read the Docs
› gevent
› pyenv
› virtualenv
› Stackless Python
› Beautiful Soup
› 结巴中文分词
› Green Unicorn
› Sentry
› Shovel
› Pyflakes
› pytest
Python 编程
› pep8 Checker
Styles
› PEP 8
› Google Python Style Guide
› Code Style from The Hitchhiker's Guide

这是一个创建于 3333 天前的主题,其中的信息可能已经有所发展或是发生改变。
请教大家一个问题,先让我安利下这个项目 0.0 ,目前用 flask 写了个scrapy 的实时监控模块,代码虽然很丑陋,但是很好玩,使用也很方便,实现起来很简单,在 scrapy 运行的过程中,新建一个 middleware ,当有 request 经过 middleware 的时候,将当前 crawler 的状态保存到 redis ,这样在 redis 中就有实时的爬虫状态信息了,前端一直 ajax 获取 redis 里面的信息放到前端渲染出来就行了。
这是效果图
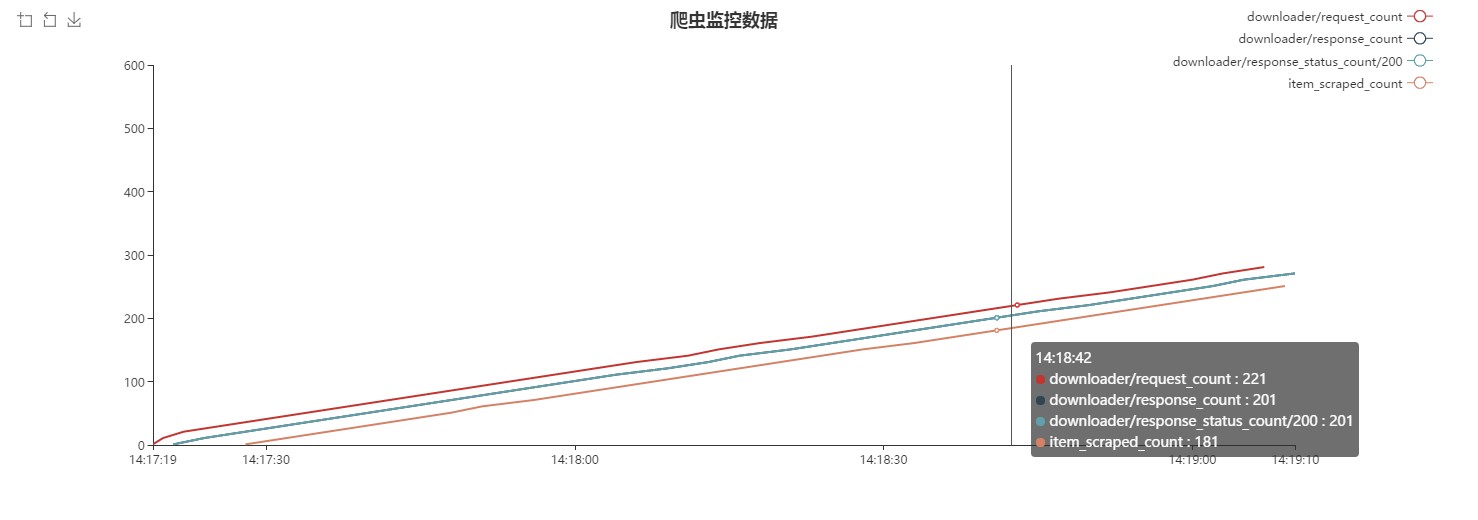
那么问题来了,目前是每一个 request 产生的时候就会保存一个当前信息,所以如果爬虫项目过大时, request 达到十万甚至百万级别的时候, redis 里面也会有相应数量的 stats 信息,这时候 redis 会不会占用很大的内存?这种情况有什么好的解决办法吗?谢谢各位 Dalao
 |
1
wlsnx 2016 年 12 月 26 日
内存主要消耗在 time.strftime('%Y-%m-%d %H:%M:%S') 上
'downloader/request_count', 'downloader/response_count','downloader/response_status_count/200', 'item_scraped_count' 看上去都是比较小的数字,占不了太多内存,就算乘以 100 万也不会太大 https://github.com/ioiogoo/scrapy-monitor/blob/master/visiter/visiter/monitor/statscol.py#L27 这里如果真的跳过了, 4 个列表中的数据是不是就不同步了 https://github.com/ioiogoo/scrapy-monitor/blob/master/visiter/visiter/monitor/app.py#L22 这里数据量超过 POINTLENGTH 以后,前端是不是就不更新了 |
 |
2
ioiogoo OP @wlsnx 感谢这么细致的回复。
1 、可能是我没有讲清楚,我存在 redis 里面的数据不是数字,因为前端展示的时候,那条线是由若干个点组成的,存在 redis 里面的数据是这样的, https://ooo.0o0.ooo/2016/12/26/5860df77c3e66.jpg 我取的时候会把所有数据以 list 的形式取出来,所以每条线的数据是这样的一个 list `[{'value': ['2016-12-26 17:08:37', 1]}, {'value': ['2016-12-26 17:08:40', 31]}, {'value': ['2016-12-26 17:08:44', 61]}, {'value': ['2016-12-26 17:08:49', 91]}]`, list 里的每一项代表一个点,所以项目到后面,这个 list 会很长,存在 redis 里面的数据也会非常多 2 、因为 scrapy 里面 stats.keys 非常多,可以看一下, https://ooo.0o0.ooo/2016/12/26/5860e03cd30aa.jpg ,而且很多数据意义不大,所以我只需要监控几个有意义的 key ,所以不在我 STATS_KEYS 里面的 key 或者当前 stats 没有这个 key 时我就跳过 3 、前面说了每条线是由若干个点组成,当点太多了的时候,可以设置 POINTLENGTH ,从 redis 里面只取出这么多个数据,限制前端显示的点数,也就相当于限制了时间范围 表达不是太好,如果还有什么问题我没讲清楚的欢迎探讨 |
|
3
wlsnx 2016 年 12 月 26 日
1. middleware 每取到一次数据,就会生成 4 个 {'value': ['2016-12-26 17:08:37', 1]} ,不如生成一个 {'value': ['2016-12-26 17:08:37', 1,2,3,4]},或者 {'value': [1482745171, 1,2,3,4]},或者[1482745171, 1,2,3,4]
2.https://github.com/ioiogoo/scrapy-monitor/blob/master/visiter/visiter/monitor/statscol.py#L25 已经保证只能取到 4 个值了,如果其中某个值为 None ,就只剩 3 个值了 3.如果我想改动这个值,是不是要修改配置文件,然后重启程序?为什么不动态计算,或者把总数给前端,从前端接受范围? |
|
4
ioiogoo OP @wlsnx
1. 1 、 2 、 3 等每一个 value 都要生成对应的 time ,不然怎么能记录下随时间的变化过程呢?坐标系上横轴是时间,纵轴是 value ,你这样的话就没有表现出随时间的变化啊,['2016-12-26 17:08:37', 1,2,3,4]}这样的 list4 个值都对应到一个时间,是没有意义的,所以必须是一个 time 对应一个 value 2.我默认设置的 STATS_KEYS 大部分爬虫都会有值的,当然如果为 None 的话,前端不会显示这条线,因为本身就没有数据,这点你可以仔细看上面的效果图最前面的部分,刚开始 item 还没有的时候,就不会显示这条线 3.这点的话的确是要修改配置文件才能起作用,后面我会加上动态修改的功能。 |
|
5
wlsnx 2016 年 12 月 26 日
一个 for 循环里 scrapy stat 是固定的,这个时间如果变化了,就是你 for 循环执行得太慢了,这个时间间隔都用来写 redis 了吧。我出于节省内存的角度考虑,可以把 4 个值合并到一起,如果某个值不存在,可以设置成 -1 。
考虑一种情况,你程序已经运行一次, redis 里有相应的结构了,然后再次运行,查找某个 key 时没找到,这时候你跳过了,而不是写一个无意义的值,等取数据的时候,你根据步长过滤数据,这一列的时间点可能和其他列完全不对应。这时候你图上的竖线就没有意义了。 |
|
6
ioiogoo OP @wlsnx 对对对,根据步长过滤数据就是会出现这样的情况, https://ooo.0o0.ooo/2016/12/26/5860f59bd6fb5.jpg ,但是因为时间间隔很短,所以问题不是很大,后面有时间再解决吧。
关于把 4 个值合并到一起,一开始我有想到这样做,一个是时间统一,二是只用新建一个 dict ,节省内存,三是减少插入 redis 的次数,但是缺点是,因为前端需要的数据是[{"value":[time, value]}]这样的格式,所以用上面方法的时候还需要把{['2016-12-26 17:08:37', 1,2,3,4]}的数据拆成 4 份再组装起来,也比较损耗性能,很烦,所以,我选择目前的方法。 |
 |
7
yanzixuan 2016 年 12 月 28 日
公司的爬虫监控差不多就是这么干的,但是我觉得没啥意义。
因为 ELK 一套分分中就能搭出来。。 |