
This topic created in 3511 days ago, the information mentioned may be changed or developed.
在这个人人都谈Spark的年代,小数也觉得有必要来发 Spark 的技术文章,帮助大家从入门到精通地了解和掌握 Spark ,从概念到编程,深刻体会它的迷人之处:) Spark 七步走, here we go !
一、为何选择 Spark
首先, Spark 是为了快速处理、易于使用和高级分析而设计的最有效的开源数据处理引擎,拥有来自 250 多个机构的参与者,其社区也有越来越多的开发者和用户加入。
第二,作为一个为了大规模分布式数据处理设计的通用计算引擎, Spark 通过一个统一包含 Spark 组件的引擎以及 API 访问库来支持多个工作负载,它支持流行的编程语言,包括 Scala 、 Java 、 Python 和 R 。
最后,它可以部署在不同的环境中,从各种数据源读取数据,与无数应用程序交互。
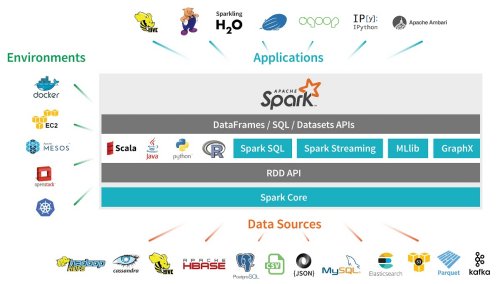
同时,这个统一的计算引擎使得在一个理想的环境下不同负载—— ETL ,互动查询(Spark SQL),高级分析(Machine Learning),图像处理(GraphX/ GraphFrames)和流(Spark Streaming)——都运行在相同的引擎上。

在随后的步骤中,您将得到其中一些组件的一个介绍,但是首先让我们介绍一下它关键概念和术语。
二、 Apache Spark 的概念、关键术语和关键词
今年 6 月, KDnuggete 发表了《 Apache Spark 的关键术语解释》( http://www.kdnuggets.com/2016/06/spark-key-terms-explained.html ),这是一个非常不错的介绍。下面补充一些 Spark 的术语词汇表,它们都将经常在本文中出现。
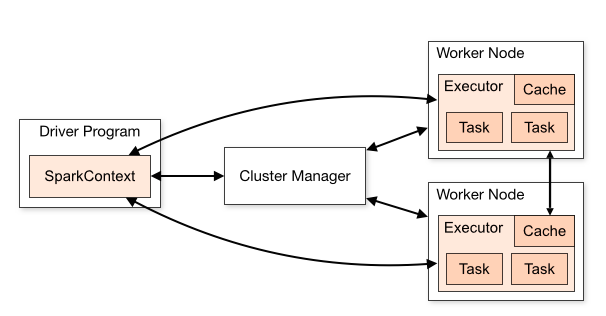
Spark Cluster 在云端或者安装 Spark 的数据中心预置的一组机器或者节点。那些机器就是 Spark workers 、 Spark Master (在一个独立的模式下的集群管理器)和至少一个 Spark Driver 。
Spark Master 顾名思义, Spark Master JVM 在一个独立的部署模式下作为集群的管理器, Spark Works 注册它们自己作为集群的一部分。根据部署模式,它作为一个资源管理器,决定在集群的哪台机器发布多少个执行器。
Spark Worker Spark Worker JVM ,在接到来自 Spark Master 的指令后,代表 Spark driver 发布执行器。 Spark 的应用程序,分解为任务单元,被每个 Worker 的执行器执行。简而言之, Worker 的工作是代表 Master 发布一个执行器。
Spark Executor 它是一个分配好处理器和内存数量的 JVM 容器, Spark 在其上运行它的任务。每个 Worker 节点通过一个可配置的核心(或线程) 发布自己的 Spark 执行器。除了执行 Spark 任务,每个执行器还在内存中存储和缓存数据分区。
Spark Driver 一旦它从 Spark Master 得到集群中所有的 Worker 的信息,驱动程序就为每个 Worker 的执行器分配 Spark 的任务。 Drive 也从每个执行器的任务中获得计算结果。
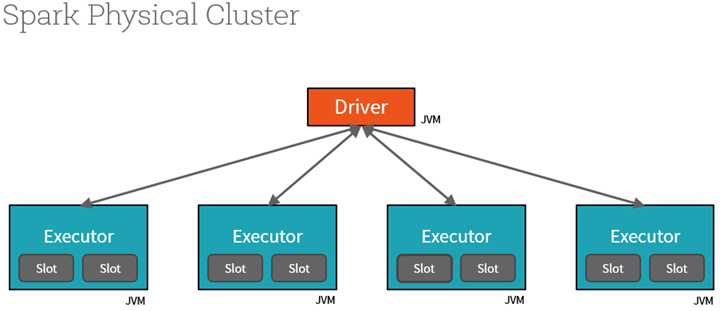
SparkSession 和 SparkContext
如图表所示,SparkContext 是访问所有 Spark 功能的渠道;在每个 JVM 只有一个 SparkContext 。 Spark 驱动程序使用它连接到集群管理器进行通信并提交 Spark 工作。它允许您配置 Spark 参数。通过 SparkContext ,驱动可以实例化其他 contexts ,例如 SQLContext 、 HiveContext 、 StreamingContext 。
使用 Apache Spark 2.0,SparkSession 可以通过一个统一的入口点访问所有提到的 Spark 的功能,同时可以更简单地访问 Spark 功能,以及贯穿底层 context 来操作数据。
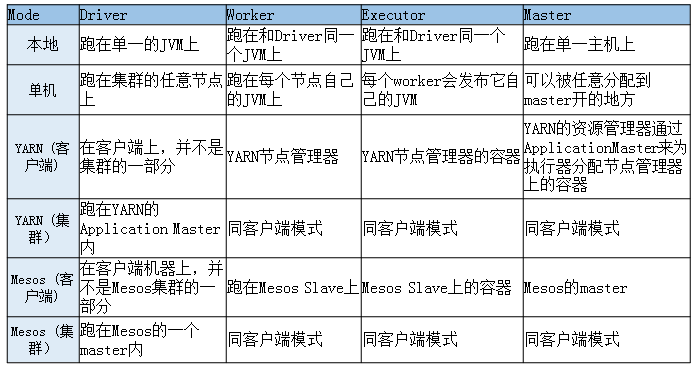
Spark 部署模式
Spark 支持四个集群部署模式,对应运行在 Spark 集群里的 Spark 的组件,每个都有自己的特点。所有模式中,本地模式是在一个单独的主机上运行,是目前为止最简单的。
作为初级或中级开发人员是不需要知道这个复杂表格的,在这里供您参考。此外,本文的第五步会深入介绍 Spark 体系结构的各个方面。
Spark 的 Apps, Jobs, Stages and Tasks
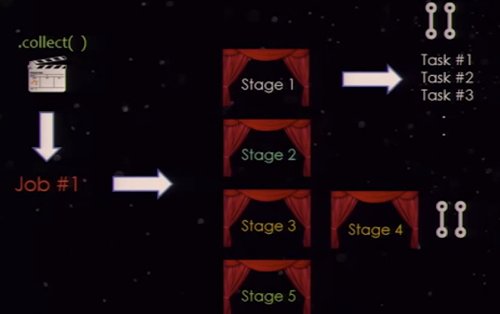
一个 Spark 应用通常包括了数个 Spark 的操作,可以分解为数据集上的 transformation 或者 action ,来使用 Spark 的 RDD 、数据框或者数据集。举例来说,在 Spark 应用,如果你调用一个 action ,这个 action 会产生一个 job 。一个 job 会分解成单一或者多个 stage ; stage 会进一步切分成单独的 task ; task 是执行单元, Spark driver 的调度会将其运送到 Spark worker 节点上的 Spark 执行器进行执行。通常多 task 会并行跑在同一个执行器上,在内存的分区数据集上分别进行单元进程。
文章来源: http://www.kdnuggets.com/2016/09/7-steps-mastering-apache-spark.html
No Comments Yet