
这是一个创建于 3448 天前的主题,其中的信息可能已经有所发展或是发生改变。
摘要:友盟大数据平台的架构借鉴了 Lambda 架构思想,数据接入层让 Kafka 集群承担,后面由 Storm 消费,存储在 MongoDB 里面,通过 Kafka 自带的 Mirror 功能同步,两个 Kafka 集群,可以分离负载;计算有离线和实时两部分,实时是 Storm ,离线是 Hadoop ,数据仓库用 Hive ,数据挖掘正在从 Pig 迁移到 Spark ,大量的数据通过计算之后,存储在 HDFS 上,最后存储在 HBase 里面,通过 ES 来提供多级索引,以弥补 HBase 二级索引的缺失......
友盟从 2010 年成立开始就专注移动大数据, 5 年来不仅积累了大量的数据,而且积累了丰富的技术和经验,那么友盟的大数据平台是怎样架构的呢?在刚刚结束的 MDCC 2015 大会上,友盟的数据平台负责人吴磊在 Android 专场为大家做了技术分享。
以下是吴磊的口述,整理时略有删减。
关于友盟大数据平台
目前,友盟合作的 App 超过 64 万 ,同时为 23 万开发者团队提供服务,截止到 2015 年 7 月底,友盟数据平台总量 9 PB ,每天增量压缩后有 7TB ,每天要处理接近 82 亿的对话,实时处理 100K QPS ,离线处理 800 多个常规任务,集群规模是 500 多台服务器, 14000 个 CPU 核心。
关于友盟数据架构
友盟架构思想
友盟的架构主要参考了 Twitter 提出的 Lambda 架构思想。

如上图所示,最下面是快速处理层,新增数据在快速处理层计算,这部分数据比较小,可以快速完成,生成实时视图。
同时,新增数据会并入全量数据集,进行批处理,生成批处理视图。这样,系统同时具有了低延迟实时处理能力,也具有离线大数据处理能力。之后通过数据服务层,把两个视图合并起来,对外提供服务。在外部看来,这是一个完整的视图。 就这样,通过 lambda 架构我们可以将实时处理和批处理系统巧妙的结合起来。
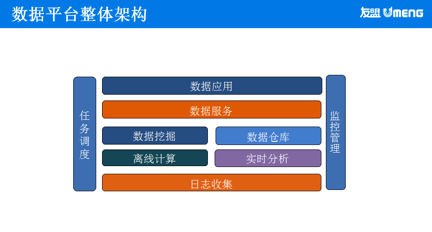
友盟数据平台整体架构
根据友盟的业务特点,数据平台由下向上分成这几个部分:最基础的是日志收集,接下来进入离线计算和实时分析,计算后的结果,会进行数据挖掘,有价值的数据进入数据仓库。接下来友盟会提供一个基于 REST Service 的数据服务,在此服务之上做各种数据应用例如:报表、数据分析报告,数据下载等等。两边的部分提供辅助的功能:包括任务调度和监控管理。
友盟数据流水线
结合友盟的业务架构和 lambda 架构思想,最终的系统如下图所示:最左边是数据采集层,友盟提供手机、平板、盒子的 SDK 给 App 集成, App 通过 SDK 发送日志到友盟平台;首先进入到 Nginx ,负载均衡之后传给基于 finagle 框架的日志接收器,接着来到数据接入层。
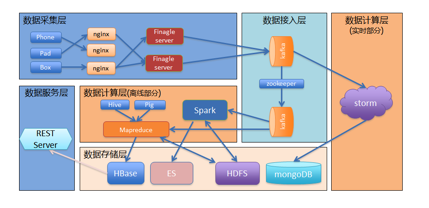
友盟使用两个 Kafka 集群来承担数据接入功能。上面这个 Kafka 集群被实时计算消费。下面的 kafka 是用于离线数据消费,两个集群之间通过 Kafka 的 mirror 功能进行同步。这么做的主要目的是 IO 负载的分离,避免离线部分过大的 IO 请求影响到实时计算部分;以及实时离线部分的业务解耦,方便两部分业务独立发展。
接下来是数据计算层,分别由离线计算层和实时计算层组成。离线部分,我们主要是基于 Hadoop Mapreduce 框架开发了一系列的 MR 任务。同时使用 Hive 建立我们的数据仓库,使用 pig 进行数据挖掘,现在我们也在逐步使用 Spark 来承担数据挖掘相关的工作。实时部分是通过 storm 来进行流式计算。
实时部分的计算结果会存储到 MongoDB ,离线部分的数据存储在 HDFS 。离线分析的结果存储在 HBase 。因为 HBase 缺少二级索引的相关功能,所以我们引入了 Elastic Search 来为 HBase 相关表提供索引查询功能。最后通过统一的 REST Service 来对外提供数据服务。
关于友盟实践
通过以上的介绍,大家可能对整个大数据平台的结构和概念有了初步的了解。正如 Linux 之父的名言,“ Talk is cheap, show me the code !”一样,其实知道是相对容易的,难的是如何去实现。所以接下来,我给大家分享一些友盟在实践中得到的一些经验。
友盟实践之数据采集
首先是从数据采集来说起,数据采集部分面临了很大的挑战。
第一是大流量,友盟服务大量开发者,接受数以亿计的设备发来日志,每天要处理 80 亿次对话,数据量非常大。
高并发也是移动互联网的特点。比如:用户在早上上班路上,中午吃饭后以及晚上睡觉前,是使用的高峰期,这个时候会对我们造成非常高的并发请求。
还有扩展性,因为移动互联网是在高速发展的,最开始我们一台机器就可以抗住,随着发展我们现在可能需要 10 台, 20 台,如果系统没有横向扩展能力将会是很痛苦的事情。
友盟的数据平台经历了一个发展的过程。在 2010 年刚开始的时候,因为快速上线的要求,我们是基于 RoR 开发的,在后台通过 Resque 进行一些离线的处理。这个架构,随着互联网的爆发,面临巨大的数据压力,很快就不能适用了。
接下来,我们就切换到基于 Finagle Server 的日志服务器。这个 Finagle Server 是 Twitter 开源出来的一个异步服务器框架,很适合移动互联网的访问特点:高并发,小数据量。切换到 Finagle Server 之后,我们单台服务器的处理能力得到了极大的提升。同时日志收集服务的无状态特性可以支持横向扩展,所以当我们面临非常高压力的时候可以简单地通过增加临时服务器来解决。
友盟实践之数据清洗
大数据的特点之一是数据多样化,如果不进行清洗会对后面的计算产生困扰。在数据清洗方面,我们花了很多精力,并踩了很多的坑。
1 、首先说“唯一标识”。
做数据分析,第一件事情就是要拿到“唯一标识”。安卓系统里作为唯一标识的,常用的是 IMEI , MAC , AndroidID 。首先因为安卓碎片化问题,通过 API 在采集这些数据的时候,常常会有采集不到的情况。
还有其他一些异常的情况,比如有很多山寨机没有合法的 IMEI ,所以会很多机器共用一个 IMEI ,导致 IMEI 重复;有些 ROM 刷机后会更改 MAC 地址,导致 MAC 重复;大部分电视盒子本身就没有 IMEI 。这种情况下我们单纯用 IMEI 或者 MAC ,或者安卓 ID ,来进行标识的的话,就会出现问题。
友盟采用的办法是由单独的服务来统一计算。后台会有离线任务来进行计算,发现重复率很高的标识符,加入到黑名单里。在计算的时候,直接跳过黑名单里的标识,换用另一种算法进行计算。
2 、在“数据标准化”时,也遇到了很多的坑
比如:“设备型号”,并不是直接采集 model 这个字段就可以解决的。拿小米 3 举例,这个手机会有很多版本,不同的批次 model 字段不一样。对于这种情况,如果我们不进行统一标准化,我们算出来的结果,肯定有问题。
还会出现多机一型的情况,例如 m1 ,大家都知道是这是一款 2011 年出现的热门手机,很有意思的是时过三年之后活跃设备数量发生了再次突增。经过调查发现,原来是他的一个对手厂家,在 2014 年底生产了一款畅销的产品, model 字段也叫 m1 。因此,我们就需要把设备型号,通过专门手段来和产品名称对应上,统一标准化。
另外在数据标准化过程中,还会遇到“地域识别”的问题。地域识别是用 IP 地址来识别的。因为中国 IP 地址管理并不是非常规范,所以经常会出现,上一秒钟大家还在北京,下一秒就到深圳的情况。对于解决这样的问题,我们是选用设备一天中最常出现的 IP 地址作为当天的地域标识。
还有“时间识别”,也是很大的问题。最开始我们采用的都是客户端时间。但是客户时间有很大的随意性,用户的一个错误设置,就会导致时间不一致;另外一些山寨机会有 Bug ,机器重启之后,时间直接就变成 1970 年 1 月 1 号了;还有一种可能,产生数据的时候没有网络连接,当他重新联网了,日志才会汇报到平台,这样的话数据就会产生延迟。
为了解决这些时间不一致的问题,我们统一使用服务器端时间。但是这样又带来了新的问题:统计时间和真实时间的差异,但是这个差异值是从小时间窗口(例如一个小时,或一天)观察出来的,从大的时间窗口来看是正确的。
3 、“数据格式的归一化”也很重要。
因为我们 SDK ,经过很多版的进化,上报上来的日志会有多种格式。早期的时候我们是采用 Json 格式,后期的话我们使用 Thrift 的格式。在数据平台处理的时候,两种格式切换很麻烦,所在我们在处理之前,我们把它统一成 Protobuf ,来进行后期计算。
友盟实践之数据计算
在数据计算的时候,根据不同业务对于时延的容忍程度的高低,分为实时计算,离线计算和准实时计算。
实时计算,面临的挑战之一是时效性。因为实时计算是对延时非常敏感的,毫秒级的水平。如果说,你把不合适的计算,比如一些很耗 cpu 的计算放进来,会直接导致实时计算的延迟。所以在架构时,需要考量,把哪些放到实时部分合适,哪些不适合。另外实时计算往往会在写数据库时会产生 IO 延迟,需要对实时数据库专门进行专门优化。我们实时计算部分选用了 MongoDB 存储数据,同时不断优化 MongoDB 的写请求来解决这个问题。
另外一个挑战是突发流量。用户使用 App 的频率并不均匀,早上、中午、晚上会有很高的使用率,尤其是晚上 10:00-12:00 这个时间段会对我们系统带来非常大的压力,得益于之前的架构设计,在达到一定的阈值之后,会触发报警,运维的同学会进行临时扩容来应对这些突发流量。
因为实时计算通常是增量计算,因此会产生误差积累的问题。 Lambda 架构决定了实时和离线是两套独立的计算系统,所以必然会出现误差。如果你长时间使用实时计算的结果,这个误差会越来越大。我们现在解决的办法是在实时处理时,不要给他太大的时间窗口,比如说最多不要超过一天,超过一天之后,就要开始清理,离线部分的计算每天计算一次,保证在这个时候离线部分的数据计算完成,这样我们就可以用离线的数据来覆盖实时数据,从而消除这个数据误差。
离线计算,也会面临一些问题。最常遇到的麻烦是数据倾斜问题。数据倾斜这个事情,几乎是天然存在的,比如说一些大 App 的数据量,和小的 App 的数据量存在着巨大的差距,常常会在离线计算的时候产生长尾现象,并行的 MR 作业中总是有一两个任务拖后腿,甚至超出单机计算能力。
产生数据倾斜的原因有很多种,针对不同的原因,有不同的解决办法。最常见的原因是因为粒度划分太粗导致的,比如说我们计算的时候,如果以 App ID 来进行分区,很容易导致数据倾斜。针对这种情况,友盟的解决办法的是进行更细一步的划分,比如说我们通过 App ID 加设备 ID 进行分区,然后再将结果聚合起来,这样就可以减少数据倾斜的发生。
第二个问题是数据压缩的问题。离线计算的时候,往往输入输出都会很大,因此我们要注意时时刻刻进行压缩,用消耗 cpu 时间来换取存储空间的节省。这样做能够节省数据传输中的 IO 延迟,反而能够降低整个任务的完成时间。
接下来会面临资源调度的困难,因为我们各种任务优先级是不一样的,比如一些关键的指标,要在特定时间算出来,有些任务则是早几个小时都可以。 Hadoop 自带的调度器无论是公平调度还是能力调度器都不能实现我们的需求, 我们是通过修改 hadoop 的调度器代码来实现的。
另外我们还有一类任务对时延比较敏感,但是又不适合放到实时计算中的。这类任务我们称之为准实时任务。例如报表的下载服务,因为是 IO 密集型任务,放入实时不太合适,但是它又对时间比较敏感,可能用户等三五分钟还是可以接受的,但是等一两个小时就很难接受了。对于这些准实时任务我们之前采用的是通过预留一定资源来运行 MR 来实现的。现在用 spark Streaming 专门来做这些事情。
在进行准实时计算时,里面也有一个资源占用的问题,在预留的过程中,会导致你的资源占用率过低,如何平衡是个问题;第二点很多实时计算的任务,往往也采用了增量计算模式,需要解决增量计算的误差累计问题,我们通过一定时间的全量计算来弥补这个缺陷。
友盟实践之数据存储
数据存储,根据我们之前的计算模式,我们也分为在线存储和离线存储两部分。在实时部分的计算结果我们主要存在 MongoDB 里面,必须对写 IO 进行优化。离线数据计算结果一般存储在 HBase 里。但是 HBase 缺少二级索引。我们引入了 Elastic Search ,来帮助 HBaes 进行索引相关的工作。
在做数据服务的时候通过数据缓存能够解决数据冷热的问题。友盟数据缓存用的是 Redis ,同时使用了 TwemProxy 来作负载均衡。友盟在数据缓存这方面的经验就是需要预加数据,比如:每天凌晨计算完数据之后,在用户真正访问之前,需要把部分计算结果预先加载上去,这样等到用户访问的时候,就已经在内存里了。
友盟实践之数据增值
整个大数据的系统,价值最大的部分,就在于数据增值,对于友盟来说,目前数据增值主要分两个大的方向。
1 、首先是内部数据打通。
友盟实现了个性化“微”推送,基于用户事件,结合用户画像、以及和阿里百川合作提供更多的维度信息,来为开发者提供更精准的推送。
比如:对一个汽车电商类的 App ,可以圈定一部分有车的用户来推送汽车配件相关信息;然后圈定一部分无车用户来推送售车相关信息。
2 、友盟在数据挖掘方面做了很多工作。
友盟针对现有的设备,进行了用户画像相关计算,通过用户画像能够了解用户的属性和兴趣,方便后续的数据横向打通。同时我们提供了设备评级这个产品。这主要是针对一些作弊行为来设计的。比如说一些 App ,进行推广的时候会发现,有些渠道的推广数据会有不真实的情况。
为此通过数据平台的统计算法和机器学习算法,把我们现有的所有设备,进行评级,哪些是垃圾设备,哪些是真实设备,能够很好的识别出来。这样一来,如果开发者有相关需求,我们可以提供设备评级相关指标,来帮助开发者测评这些推广渠道,到底哪些可信,哪些不可信。
围绕着这些渠道刷量的问题,我们还推出了健康指数。设备评级产品,只是从设备和渠道的角度,来观察作弊的问题;而健康指数是从一个 App 整体的角度来观察作弊情况。
 |
1
vozon 2015-12-04 10:19:46 +08:00
ios 的 ID 问题是怎么解决的? 不同平台的 ID 有打通的可能性吗?
|