
前言
前阵子写的日志分析工具NginxPulse,自开源以来,已过去 2 周时间,目前 GitHub 已收获 1.5k 的 star 。收到了不少用户的反馈建议,花了点时间将这些问题都处理了下。
本文就跟大家分享下新版本都解决了哪些问题,优化了哪些内容,欢迎各位感兴趣的开发者阅读本文。
抛弃 SQLite
有不少用户反馈说日志文件很大的时候( 10G+),解析速度非常慢,需要解析好几个小时,解析完成之后数据看板的查询也比较慢(接口响应在 5 秒左右)。
于是,我重写了日志解析策略(解析阶段不做 IP 归属地查询,仅入库其他数据,将日志中 IP 记录起来),日志解析完毕后,将记录的 IP 做去重处理,随后去做归属地的查询处理(优先本地的 ip2region 库,远程的 API 调用查询做兜底),最后将解析到的归属地回填至对应的数据库表中,这样一套下来就可以大大提升日志的解析速度。
数据库的数据量大了之后,SQLite 的表现就有点差强人意了,请教了一些后端朋友,他们给了我一些方案,结合我自身的实际场景后,最后选定了 PostgreSQL 作为新的数据库选型。
这套方案落地后,用户群的好兄弟说:他原先需要解析 1 个小时的日志,新版只需要 10 多分钟。
UI 配置可视化使用
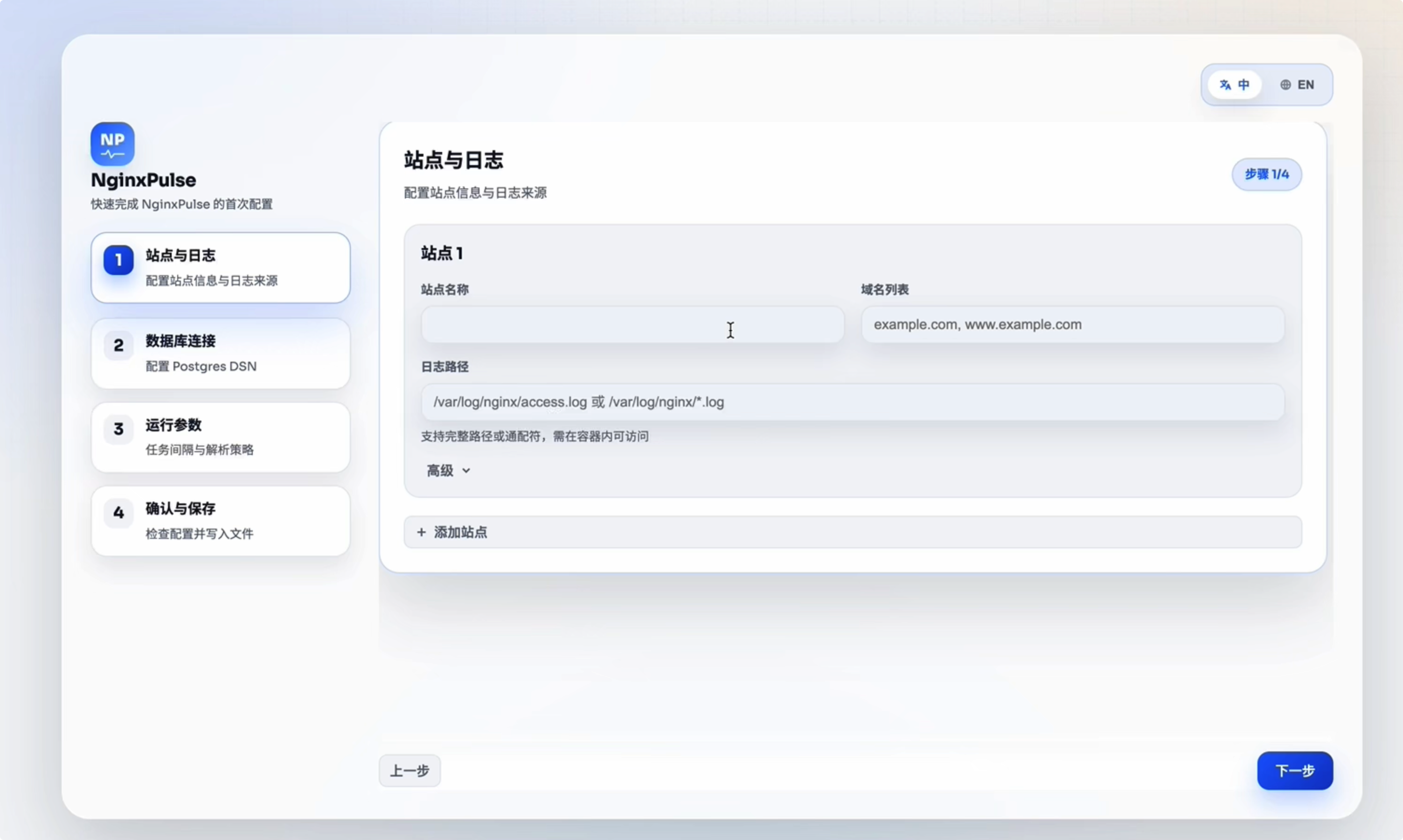
有一部分用户反馈说他非专业人士,这些晦涩的配置对他来说使用门槛太高了,希望能有一个 UI 配置页面,他只需要点一点、敲敲键盘,就能完成这些配置。
我将整个配置流程做成了 4 步,同时也准备一个[演示视频](NginxPulse 支持 UI 配置化了) - https://www.bilibili.com/video/BV1hqzyBVEU9:
- 配置站点
- 配置数据库
- 配置运行参数
- 确认最终配置
新增 wiki 文档
因为配置过于庞大,仓库主页浏览 README.md 比较费劲,希望能整理一份 wiki 文档发上去。
花了点时间,简化了下 README ,整理了一份: https://github.com/likaia/nginxpulse/wiki
访问明细模块优化
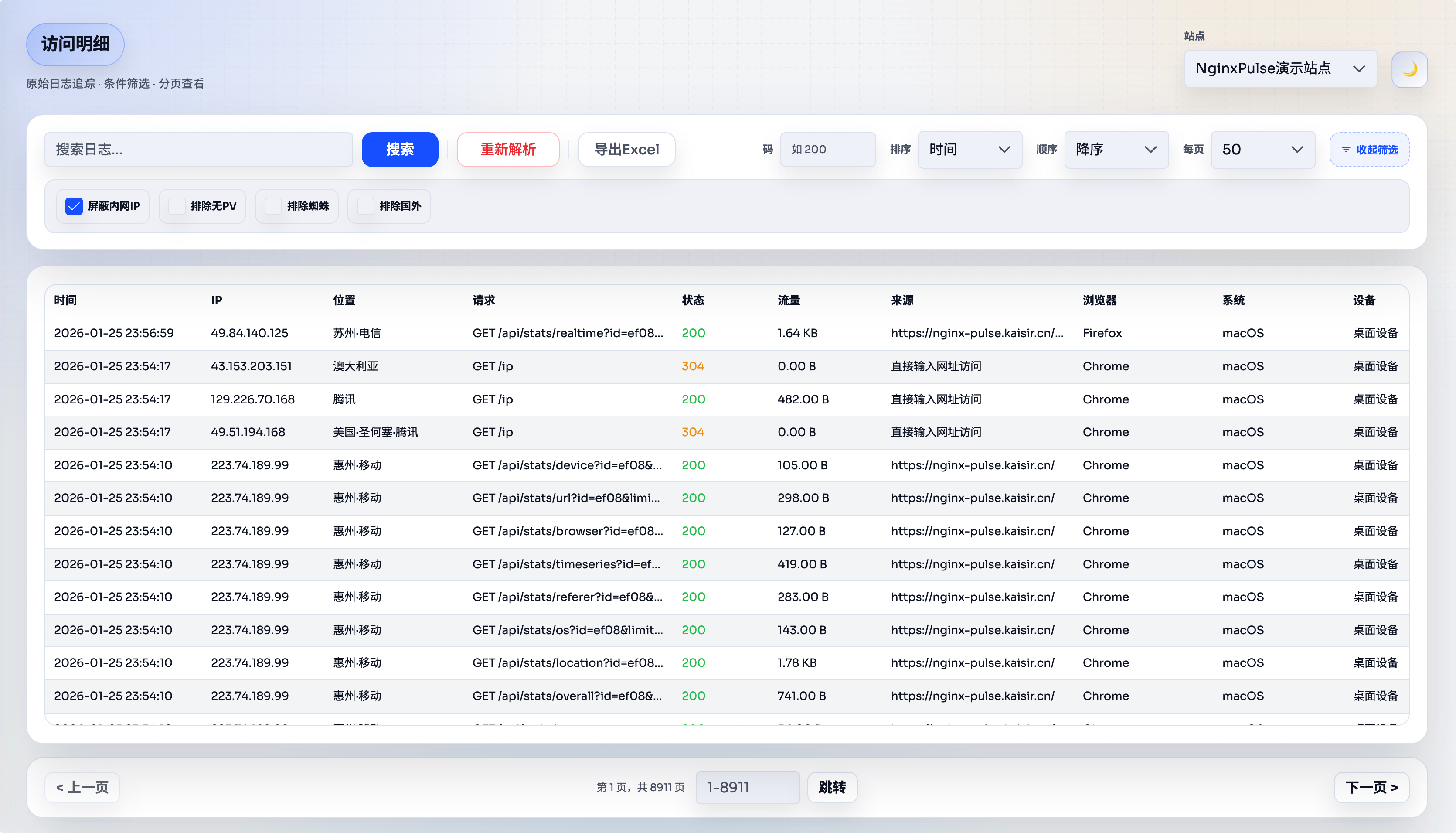
有部分用户反馈说希望增加更多的筛选条件以及导出 Excel 功能,现在它来了:
概况模块优化
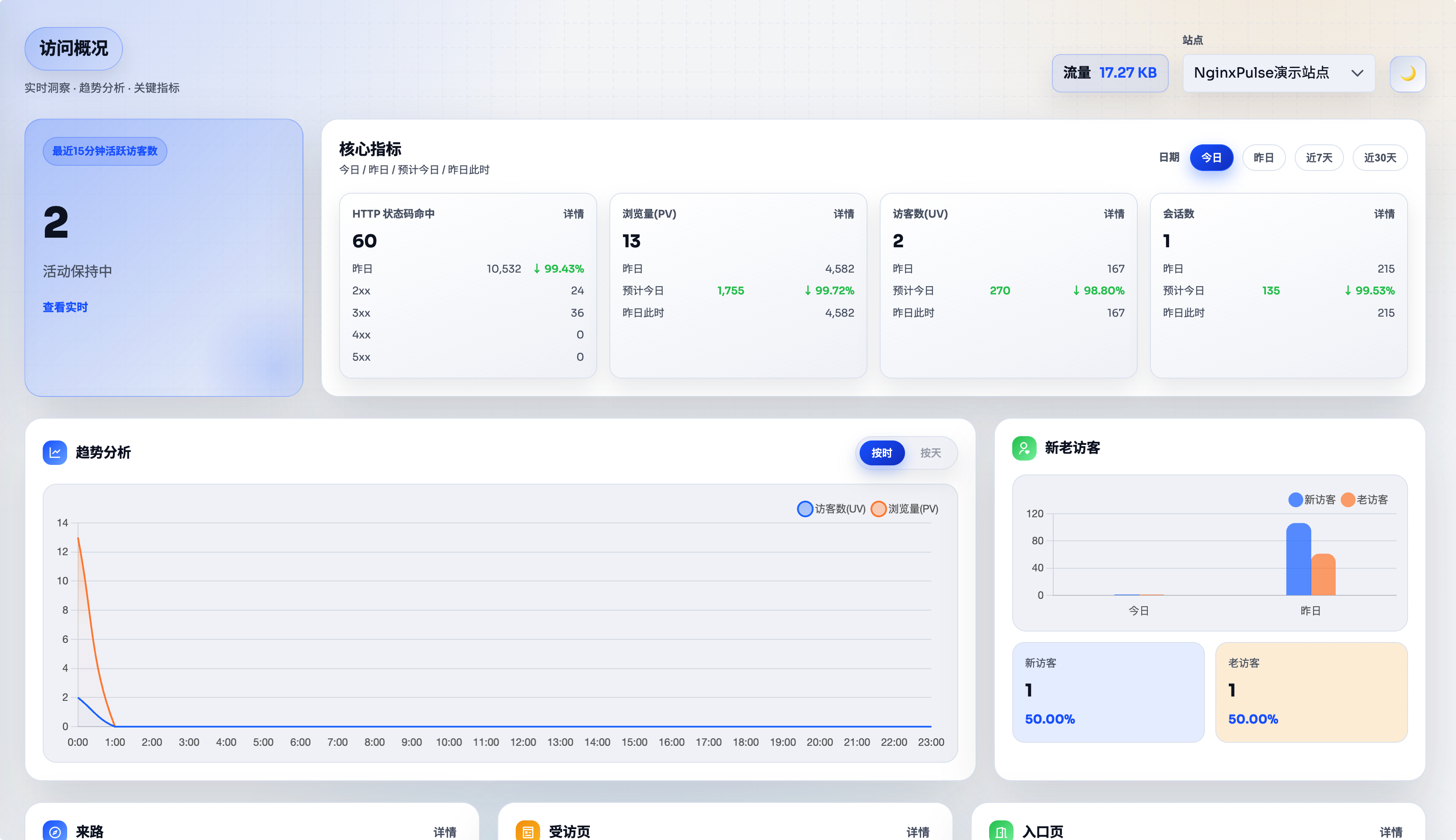
概况页面的日期筛选之前放在趋势分析卡片的上方,但是他的切换影响的维度还包含了指标,于是我就调整了下它的位置,新版如下图所示:
项目地址
- GitHub 地址: https://github.com/likaia/nginxpulse
- dockerhub 地址: https://hub.docker.com/r/magiccoders/nginxpulse/
写在最后
至此,文章就分享完毕了。
我是神奇的程序员,一位前端开发工程师。
如果你对我感兴趣,请移步我的个人网站,进一步了解。











