
背景
偶然发现外部系统都会使用 requestId 来追踪请求的调用栈,但是我参与的项目中没有,排查问题时非常依赖于日志中的各种关键字,定位 bug 时只能一边看代码,一边使用各种关键字追踪这个请求的调用栈。
尤其是当这个服务有多个实例的时候,不可能登录到每个实例看请求打在哪个实例上,只能在日志平台一点点根据关键字排查,但这个日志平台出现过吞日志等问题(不知道是不是没上报成功还是啥),增加定位问题的难度
想知道大家排查问题时有什么最佳实践吗,基于 requestId 是不是一个好方法呢?
偶然发现外部系统都会使用 requestId 来追踪请求的调用栈,但是我参与的项目中没有,排查问题时非常依赖于日志中的各种关键字,定位 bug 时只能一边看代码,一边使用各种关键字追踪这个请求的调用栈。
尤其是当这个服务有多个实例的时候,不可能登录到每个实例看请求打在哪个实例上,只能在日志平台一点点根据关键字排查,但这个日志平台出现过吞日志等问题(不知道是不是没上报成功还是啥),增加定位问题的难度
想知道大家排查问题时有什么最佳实践吗,基于 requestId 是不是一个好方法呢?
 |
1
nulIptr Jan 23, 2025
搜索关键字 opentracing
|
 |
2
Charlie17Li OP @nulIptr 我理解 OpenTracing 是用来解决微服务中请求在多个服务间的调用链路,对吗?我现在面临的问题是:一个服务内的调用逻辑
|
 |
3
main1234 Jan 23, 2025 在 http 做个 middleware ,middleware 会判断
1.如果 header 中有 X-Request-ID ,使用该 id 作为 requestID 2.如果 header 中没有,会生成 requestID 将 requestID 放到 ctx 中 然后 ctx 从上传到下,log 时候将 ctx 中的 requestID 取出来打印,请求时候将 id 放到 header 中 |
 |
4
Solix Jan 23, 2025 via iPhone
EFK 把日志拿出来再看就顺多了
|
 |
5
Desdemor Jan 23, 2025
链路追踪 你搜搜,这不是最基本的吗,有的框架本身就自带
|
 |
6
Sendya Jan 23, 2025
@Charlie17Li #2 opentracing 用于服务内的调用链路一样很好用,可以记录到每一个函数调用,参数,等数据
|
 |
7
kingcanfish Jan 23, 2025
直接 debug.Stack() 打印调用栈到日志里不行吗
|
 |
8
Ayanokouji Jan 23, 2025
requestID 只能解决一部分问题,不能解决全部问题。
go 的 error 和 log 是个技术活,可以看看我之前的帖子,参考下思路 /t/1101542 |
|
9
Ayanokouji Jan 23, 2025
@Ayanokouji 我现在采用的方案是 oops
|
 |
10
hashakei Jan 23, 2025
一般的基础框架会封装的,实际是在 context 透传下去的。
|
 |
11
Nitromethane Jan 23, 2025
@kingcanfish 打堆栈在生产环境可能会影响性能
|
 |
12
sophos Jan 23, 2025
现在不应该是 OpenTelemetry 了吗,Opentracing 前两年就被废弃了 ;-)
仅供参考: https://github.com/go-kod/kod/blob/main/interceptor/ktrace/trace.go https://github.com/go-kod/kod-ext/blob/main/core/otel/otel.go |
 |
13
simonlu9 Jan 23, 2025
刚好写了个插件,可以参考一下 https://github.com/simonlu9/log-alarm-spring-boot
|
 |
14
jrwt Jan 23, 2025
一个服务内的多个实例的调用逻辑不也是走网络吗?我们这边是自己定义的网络协议,协议内部就预留请求 id 部分,没有则生成,有就直接使用,在日志打印出来,采集起来,就完事了。
|
 |
15
layxy Jan 23, 2025
说白了就是在请求链路记录 requestId,可以封装下日志,打印的时候带 requestId,这样排查问题就简单了,现在 go 的日志框架例如 zap 支持结构化日志,直接扔到 es 或者其他存储里也省事,省的解析了
|
 |
16
maxwellz Jan 23, 2025
@Ayanokouji #9 我也在用这个,但是有一个问题,有时候会忘,直接用 fmt.Errorf 或者 err 在某一层被设置为了其他类型的 err ,这种情况你是咋解决的,提供一个封装好的 error 模块嘛
|
 |
17
FarmerChillax Jan 23, 2025
现在肯定用 opentelemetry ,Opentracing 已经被废弃了
|
 |
18
vhwwls Jan 23, 2025
@FarmerChillax #17 正解,用 OTEL 才是对的,OpenTracing 和 OpenCensus 已经 Archived 了。
|
|
19
vhwwls Jan 23, 2025
@Charlie17Li #2 OpenTracing 已经没了,用 OpenTelemetry 。
|
 |
20
Corrots Jan 23, 2025
都是发 opentelemetry 和 opentracing ,这些链路追踪 tracing 的采样率不可能开到 100%,对性能影响还蛮大的。
其实就可以按照 #3 说的方式来,在 http 通过 middleware 在 header 中添加 X-Request-ID ,前端 web 和 客户端最好也能配合改造下。这样对于大量微服务的业务场景,可以通过 X-Request-ID 将请求在微服务间串起来 |
|
21
Ayanokouji Jan 24, 2025
@maxwellz 没辙啊,顶多封几个 error util ,go 标准库的 error ,就是会丢上下文。
或者 fmt.Errorf 的时候,打印日志。 |
|
22
FarmerChillax Jan 24, 2025
@Corrots 这里有两个问题:
一是对实际情况来说采样率开不开到 100%只是采样,和埋点没有啥关,这里和性能应该也扯不上关系。 二是对性能的影响需要有数据来论证,并且是结合楼主实际业务的。比如添加了这些埋点后,性能指标有什么变化? 另外对性能影响的大小是由埋点决定的,那么也就是说具体对性能的影响是可控的,因此楼主使用时根据实际情况埋点即可。 这里衍生出来的问题则是,你的服务真的对性能有那么高的要求吗?如果是,那么你的这个服务的业务逻辑本身就应该是很薄很简单的,而不是柔和了一大坨逻辑在里面。 如果说逻辑本身就很简单很薄,那么埋点数量也必然不需要很多。 如果逻辑本身就很复杂,那么应该讨论的是本身埋点造成的耗时与原本的业务耗时的比例,这个比例我理解也不会高。 最后对于楼主的项目连 OTEL 这类基础设施都没有,要么就是历史久远,要么就是不重要。不重要的概率应该更大,因此这里引入 OTEL 我觉得也不会有什么问题。 |
 |
23
qloog Jan 24, 2025
一般使用了 opentelemetry 协议+ 实现了协议的框架都可以做到。
目前主流协议: https://opentelemetry.io/ 使用的框架,比如: https://github.com/go-eagle/eagle 框架只要把一些常用组件支持 opentelemetry 协议即可,比如 - HTTP Client - HTTP Server - 日志 - 数据库 - Redis - 函数追踪 - gRPC 当前服务和上下游服务都接口后即可追踪到,示例: 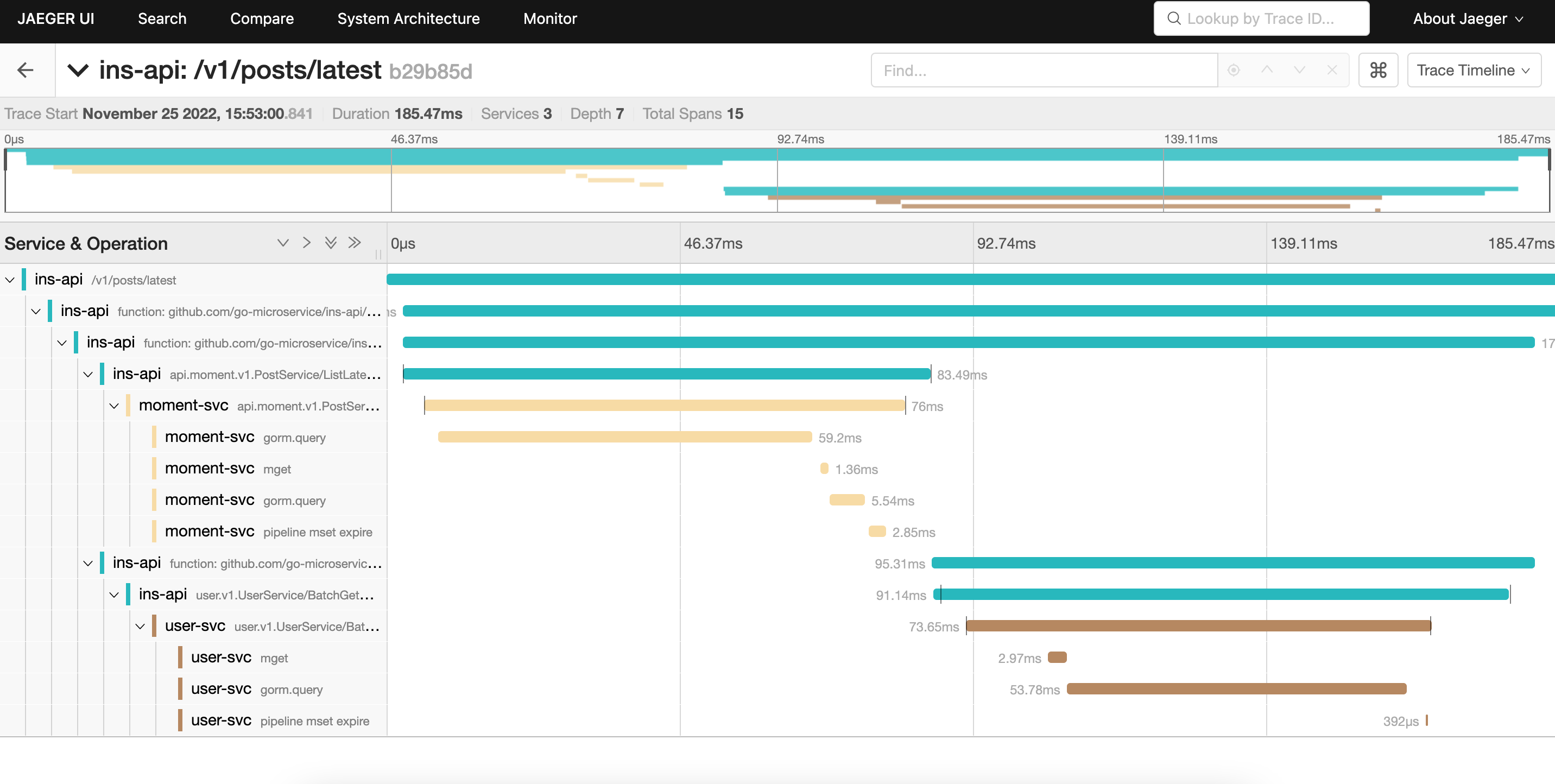 更多可以查看: https://go-eagle.org/docs/component/tracing/component |
 |
24
fxjson Jan 24, 2025
我自己的 gin 框架 https://github.com/fanqingxuan/go-gin 与 3 楼说的一致,但是我没有考虑微服务,毕竟绝大多数没必要使用微服务
func TraceId() gin.HandlerFunc { return func(ctx *gin.Context) { ctx.Set(traceid.TraceIdFieldName, traceid.New()) ctx.Next() } } |
|
25
qloog Jan 24, 2025
|
|
26
qloog Jan 24, 2025
又没出来,继续补,两种,看哪种可以出来:
 [img]  [/img] [/img] |
 |
28
zeromake Jan 24, 2025
之前用了 opentelemetry ,用 jaeger all in 卡的要死,还经常挂然后都丢了,用户量不大的,感觉得正常分组件部署,先不用多服务链路追踪了,手搓了一个简单的日志版链路追踪,不用依赖 jaeger 上报直接写入日志就完事了
|
 |
29
xiaocaiji111 Jan 24, 2025
服务内就用 context ,然后需要日志自己封装下。我们应用不管什么时候打印日志,默认会打印 traceId ,后续不用手动指定。类似下面这种格式。
time="2025-01-24 19:47:46.670" level=INFO source=xxx.go:36 msg="host[127.0.0.1] GET /ping" trace_id=e6cde54e22f944d8 fullPath=/ping |