推荐学习书目
› Learn Python the Hard Way
Python Sites
› PyPI - Python Package Index
› http://diveintopython.org/toc/index.html
› Pocoo
值得关注的项目
› PyPy
› Celery
› Jinja2
› Read the Docs
› gevent
› pyenv
› virtualenv
› Stackless Python
› Beautiful Soup
› 结巴中文分词
› Green Unicorn
› Sentry
› Shovel
› Pyflakes
› pytest
Python 编程
› pep8 Checker
Styles
› PEP 8
› Google Python Style Guide
› Code Style from The Hitchhiker's Guide

这是一个创建于 1789 天前的主题,其中的信息可能已经有所发展或是发生改变。
- 如图
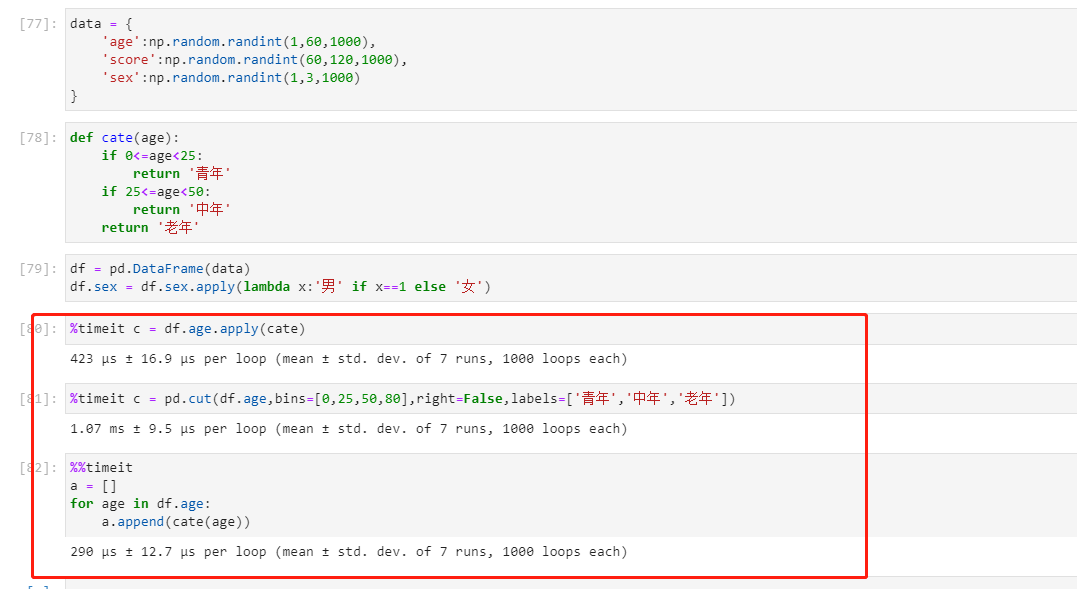
第 1 条附言 · 2021 年 3 月 31 日
- 数据量在几千条的时候,像apply,loc 等,就好像有个固定耗时,比原生慢很多
 |
1
chenbojian 2021 年 3 月 30 日
都小数据量了,不需要在意速度了吧
|
2
jr55475f112iz2tu 2021 年 3 月 30 日 via Android
毕竟是封装的
复杂统计模型也不能全部都手写吧 |
 |
3
xiaolinjia 2021 年 3 月 30 日
上次我测试的时候,发现
n1 = np.arange(cnt, dtype=np.int_) n2 = list(range(cnt)) n1 + 2 [mem + 2 for mem in n2] 当 cnt 较小的时候,numpy 的广播方式比下面 py 原生循环还慢。之前看文档说,numpy 用的 c 循环,所以比 py 的快。把我整的有点懵。 |
4
F281M6Dh8DXpD1g2 2021 年 3 月 30 日 via iPhone 你这对比的都不是一件事好么
|
 |
5
LeeReamond 2021 年 3 月 31 日
@xiaolinjia
https://gist.github.com/GoodManWEN/dc9372c7a0288837aa4ffd4b0ddc85f8 明显你测试有问题,我测试里长度为 100k 情况下 np 比原生快 200 倍,长度为 1k 下快 55 倍 |
|
6
xiaolinjia 2021 年 3 月 31 日
@LeeReamond 行吧,具体阈值我没测清除,不过 cnt 在 15 以内 py 的列表推导快过 np 广播。
|
|
7
LeeReamond 2021 年 3 月 31 日
@xiaolinjia 测了一下确实,我的阈值大概长度 25 左右时速度相等。
理论上 np 的主要开销在于 ffi,不同的优化程度 ffi 调用开销在几十到几百纳秒不等。C 语言进行这么短的计算的开销可以认为不存在,cache 不会 miss,大概几个 clock 之内搞定,可能个位数纳秒,或者 1 纳秒。 原生的话,主要在于新建和回收列表的开销,因为这部分已经高度优化了,cache 不 miss 的情况下可能几十纳秒,循环过程的开销也比较高,可能几十纳秒,加在一起得到一个合计的阈值。不过可以看出来 py 追求性能还是颇拉胯的,随着列表长度增长会有明显的开销增长,c 的话可能你长度为 1 和长度为 1000 感受不到什么区别。 |
 |
8
tisswb 2021 年 4 月 8 日
目前我用到的 pandas 适合做统计跟可视化等骚操作
|