关于这个队列实现的版本中:
为什么每次要从队列中选取距离最小的顶点出发?而不是按照广度优先的顺序?
代码如下:
def dijkstra1(graph, start):
distances = {vertex: float('inf') for vertex in graph}
distances[start] = 0
visited = set()
queue = list(graph.keys())
while queue:
vertex = min(queue, key=lambda vertex: distances[vertex])
queue.remove(vertex)
visited.add(vertex)
for neighbor in graph[vertex]:
if distances[vertex] + graph[vertex][neighbor] < distances[neighbor]:
distances[neighbor] = distances[vertex] + graph[vertex][neighbor]
if neighbor not in visited:
queue.append(neighbor)
return distances
我试着用广度优先搜索,发现也不影响实际结果,而且性能和用最小堆实现的差不多
from collections import deque
def dijkstra2(graph, start):
distances = {vertex: float('inf') for vertex in graph}
distances[start] = 0
visited = set()
queue = deque([start])
while queue:
vertex = queue.popleft()
visited.add(vertex)
for neighbor in graph[vertex]:
if distances[vertex] + graph[vertex][neighbor] < distances[neighbor]:
distances[neighbor] = distances[vertex] + graph[vertex][neighbor]
if neighbor not in visited:
queue.append(neighbor)
return distances
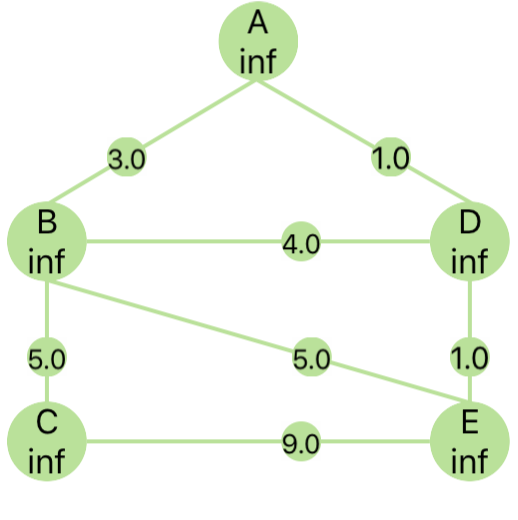
测试代码
g = {
'A': {'B': 3, 'D': 1},
'B': {'A': 3, 'C': 5, 'D': 4, 'E': 5},
'C': {'B': 5, 'E': 9},
'D': {'A': 1, 'B': 4, 'E': 1},
'E': {'B': 5, 'C': 9, 'D': 1}
}
print(dijkstra(g, 'A'))
测试图