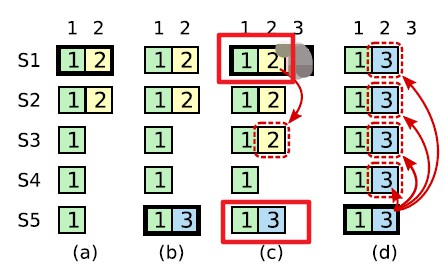
- 如下图(C)的情况:
问题一:
- 当 leader S1 收到其他大多数 node 的 AppendEntryReply(AER)的成功时,也就是大多数成功 replicate以后,标记当前 log(s)为 commit 状态,更新 commitIndex,然后 apply 到状态机中。
- 我的实现是在下一次的 HeartBeat(HB)或者 AE 分发的时候,follower 才更新刚才的 log 的状态为 commit,如果在 leader 更新完 commitIndex 但没有完成向 follower 发送确认时,leader failed(收到更高的 term 的 RequestVote 或者 AE,然后 turn to follower)。
- 这和 figure8 的情况有点类似,这次的问题是:原来的 leader S1 已经把 Term2 的 log commit 掉了(更新了 commitIndex),后来的 leader S5 又修改了那个 index 对应的 log,因为 commit 以后不能在修改,这样原来的 leader S1 恢复以后,没有办法接受新 leader S5 的 log,也没有办法在成为 leader,就卡在这了,怎么破?
问题二:
- 如果在图中(c)中 Term2 的 log 在所有节点上都成功 commit,然后 leader 宕掉,S5 被选为 leader,这时 Term2 的 log 不也会被 overwrite 掉吗?