推荐学习书目
› Learn Python the Hard Way
Python Sites
› PyPI - Python Package Index
› http://diveintopython.org/toc/index.html
› Pocoo
值得关注的项目
› PyPy
› Celery
› Jinja2
› Read the Docs
› gevent
› pyenv
› virtualenv
› Stackless Python
› Beautiful Soup
› 结巴中文分词
› Green Unicorn
› Sentry
› Shovel
› Pyflakes
› pytest
Python 编程
› pep8 Checker
Styles
› PEP 8
› Google Python Style Guide
› Code Style from The Hitchhiker's Guide

Chinese-Text-Classification,用卷积神经网络基于 Tensorflow 实现的中文文本分类。
1722332572 · 2017-11-09 15:35:18 +08:00 · 5165 次点击这是一个创建于 2639 天前的主题,其中的信息可能已经有所发展或是发生改变。
用卷积神经网络基于 Tensorflow 实现的中文文本分类
项目地址: https://github.com/fendouai/Chinese-Text-Classification 欢迎提问:http://tensorflow123.com/
这个项目是基于以下项目改写: cnn-text-classification-tf
主要的改动:
- 兼容 tensorflow 1.2 以上
- 增加了中文数据集
- 增加了中文处理流程
特性:
- 兼容最新 TensorFlow
- 中文数据集
- 基于 jieba 的中文处理工具
- 模型训练,模型保存,模型评估的完整实现
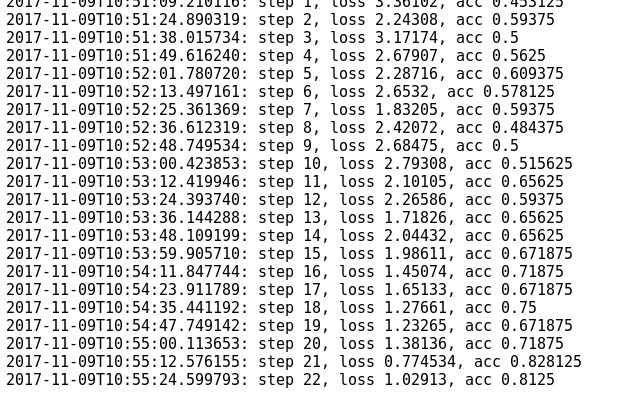
训练结果

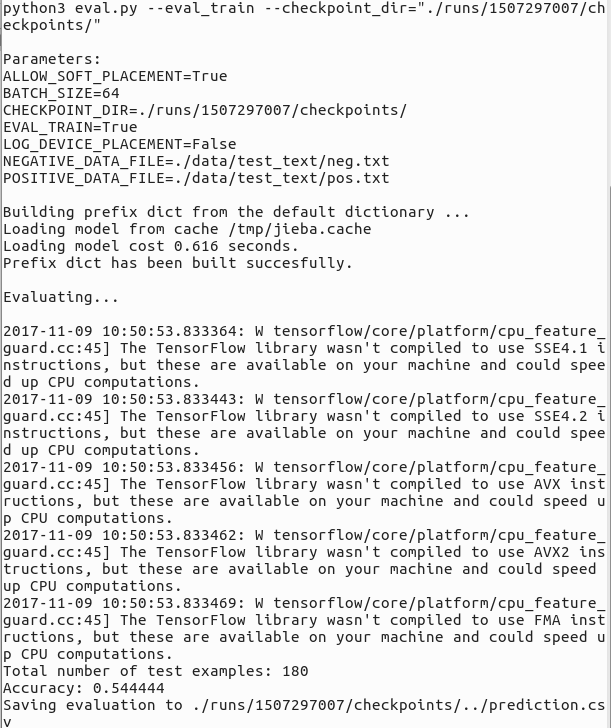
模型评估
7 条回复 • 2017-11-10 17:00:46 +08:00
 |
1
hcymk2 2017-11-09 15:38:43 +08:00
昨天还在找例子,今天就看到了。
|
 |
2
1722332572 OP @hcymk2 找什么例子
|
|
3
hcymk2 2017-11-09 21:15:20 +08:00
@1722332572
Tensorflow 的中文文本分类啊, 原来准备是用 svm 简单搞搞的 |
|
4
1722332572 OP @hcymk2 也准备搞一下 SVM
|
 |
5
wzha2008 2017-11-10 11:31:39 +08:00
cnn 做文本分类,理想很丰满,现实很骨感啊;费老大劲构建模型和调优,还是干不过好的传统模型
|
|
6
1722332572 OP @wzha2008 都是泪,今天又试了不分词。
|
 |
7
data2world 2017-11-10 17:00:46 +08:00
可以试试 fasttext,个人觉得还是多花点在原始数据上面。
|