
这是一个创建于 2635 天前的主题,其中的信息可能已经有所发展或是发生改变。
pg 新手,目前在做某系统的数据库设计,遇到一些性能上的疑惑求前辈解答一下。开发机是 mac,存储 SSD,语言 golang:
-
3 张表数据量均百万,有 3 层不相关子查询,查询语句上刻意做到尽量筛出小表再连接,查询出来的数据最多几百条,已经建了索引,查询速度普遍在 10+ms,有什么优化思路吗?
-
一次插入 1w 条数据,数据量不大,七八个字段,平均每个字段 20 多字节,在程序内构造批量语句之后执行的,速度普遍在 500ms 左右,有什么优化思路吗?
-
还有就是一般数据库的单次查询速度维持在多少比较合适?啥时候考虑上读写分离?
主要是 leader 对查询速度不太满意,让我去尝试,我对数据库性能的评估比较懵,不知道得达到哪种程度...
 |
1
liprais 2017-09-05 09:27:37 +08:00 via iPhone
贴 query 和执行计划,不然都是空
|
 |
2
lizon OP sql
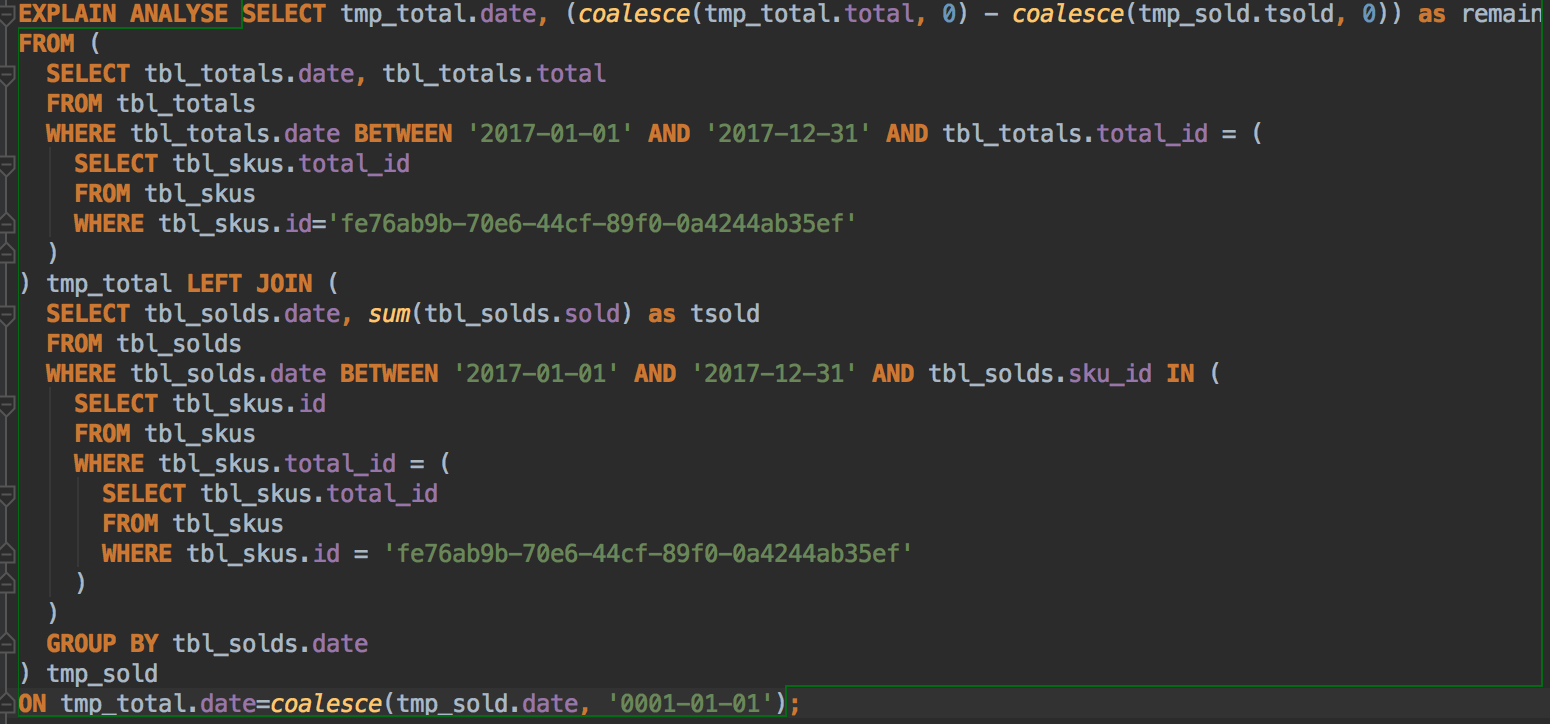 执行计划 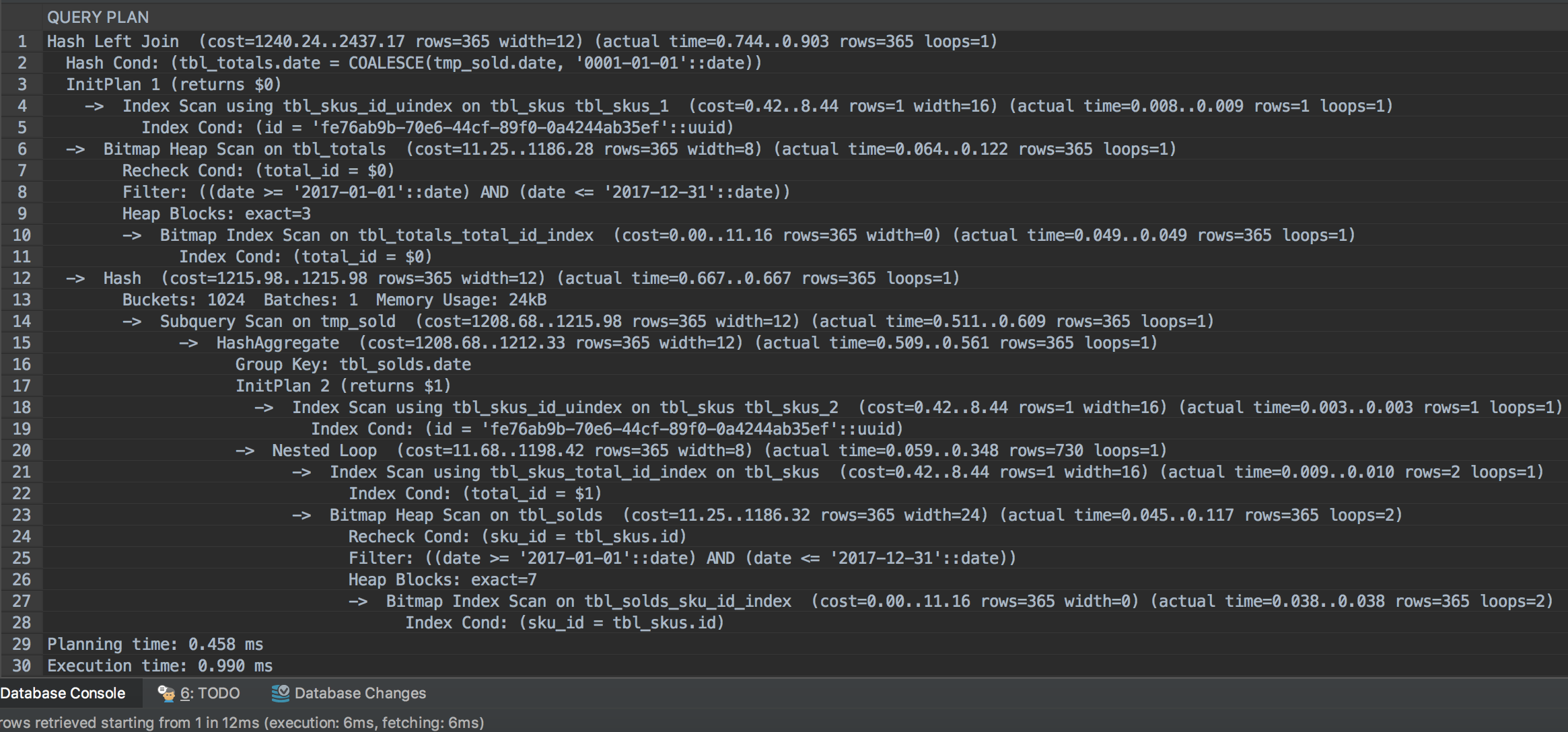 |
|
3
lizon OP 插入优化了一下,以前是把所有数据在程序里连成“ INSERT INTO...VALUES...;INSERT INTO...VALUES...;”,现在改成"INSERT INTO...VALUES(...),(...),(...)..." 100W 次插入 11s
|
 |
4
Tony8Finet 2017-09-06 00:06:55 +08:00 根据你机器的内存及系统使用状况调整 postgresql.conf 参数 (修改后需重新启动 PG):
shared_buffers = ?MB work_mem = ?MB # 正式产品线上版要注意以下引起的副作用, 小心使用!!! synchronous_commit = off commit_delay = 100000 fsync = off 另外参考 https://stackoverflow.com/questions/12206600/how-to-speed-up-insertion-performance-in-postgresql 例如: 将 insert 改以 copy 替代 若 postgresql 版本 >= 9.5, 可以在大量异动前将该资料表 logging 关闭, 完成后再恢复: ALTER TABLE table_test SET UNLOGGED; INSERT INTO ... VALUES(...), (...), ... ; ALTER TABLE table_test SET LOGGED; |
|
5
liprais 2017-09-06 00:17:46 +08:00 via iPad 每次查询的时候都要计算一年的时间里每天卖了多少?感觉可以每天的数据预先算好,毕竟昨天卖出去多少是不会变的,你的执行计划里最耗时的也是这一块
另外在 join condition 上用函数可能会有问题,可以在 select 的时候处理好.不过可能对性能没啥影响 批量导入最快的是 copy 命令 |