
这是一个创建于 2749 天前的主题,其中的信息可能已经有所发展或是发生改变。
5 月 6 日,数人云与优维科技主办了 [ DevOps&SRE 超越传统运维之道 · 深圳站] ,6 月北京站敬请关注~本文是腾讯 SNG 运维负责人——大梁分享的 DevOps 最后一棒,如何有效构建海量运营的持续反馈能力。同期嘉宾数人云王璞实录:活动实录丨 SRE 在传统企业中的落地实践。

梁定安,腾讯织云负责人,目前就职于腾讯社交网络运营部,开放运维联盟委员,腾讯云布道师,腾讯课堂运维讲师,EXIN DevOps Master 讲师,凤凰项目沙盘教练,复旦大学客座讲师。
DevOps 最后一棒
前言
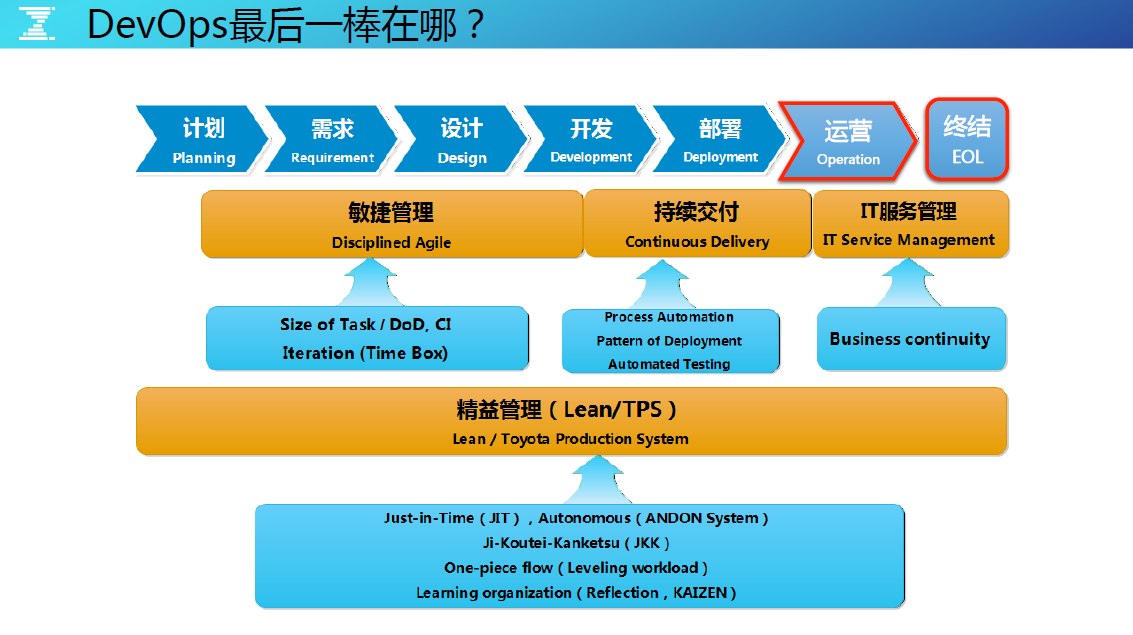
此图概括了整个 DevOps 体系,它最后的环节,是做运营和终结的环节。对于运营和终结的理解,我认为应该包含两个维度:第一个是这次运维活动质量的运营与终结;第二个是产品的技术运营与生命周期的终结。 今天聊下产品生命周期结束前的技术运营阶段,如何构建质量体系,实现持续反馈和优化的目标。
监控、告警与运维
持续反馈于运维的理解
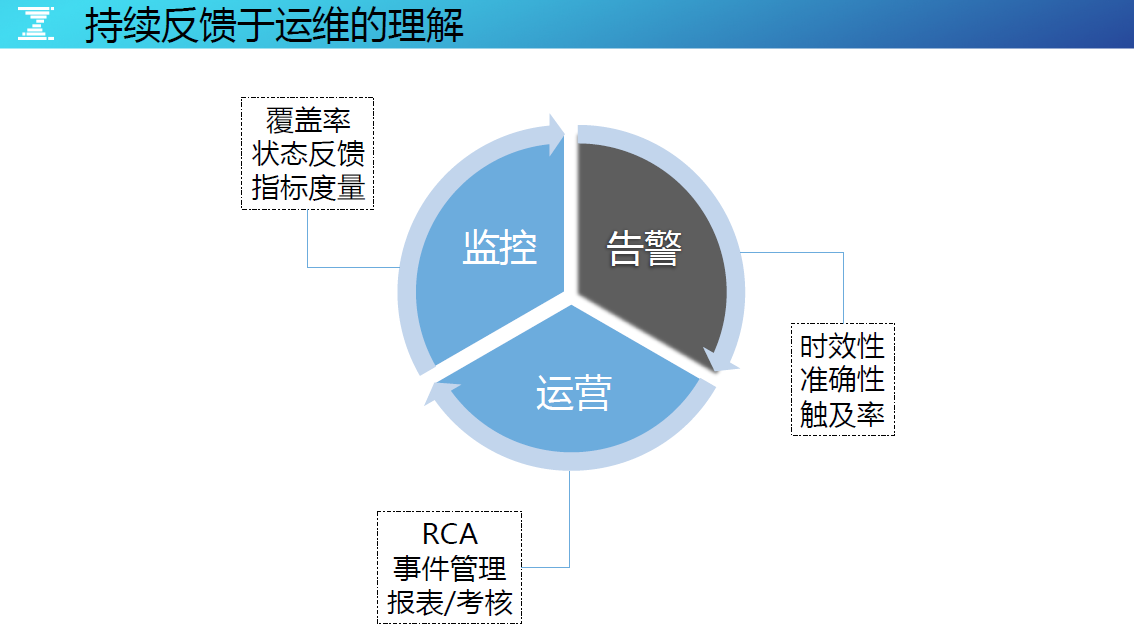
◆ 监控——覆盖率、状态反馈、指标度量
监控要做到 360 度无死角,业务出现什么问题都能发现,有了监控的反馈,可以看到实时监控的状态,同时,当指标发生变化的时候也需要注意反馈信息。
◆ 告警——时效性、准确性、触及率
业务越来越复杂,层次越来越多,每一个监控点都会产生数据指标、状态异常,会收到越来越多的告警。未看到或者看到未处理都需要承担责任,因为收到的并非都是错误告警。
◆ 运营—— RCA、事件管理、报表 /考核
问题再三出现必须从根源优化。通过事件管理机制保证 RCA 可以落地,最后通过报表和考核去给运维赋予权利,推动相关优化活动的开展,包括架构和代码的优化等。
监控、告警与运维
全面的监控点

腾讯业务按照不同的层级进行管理,自下而上,有服务器层、数据库、逻辑层。中间计算的这一层,有接入层、负载均衡、机房、DNS 服务、客户端、用户端等,为了做到无死角,我们布局了很多监控点。
实现舆情监控后,监控点做到了 100%的覆盖,但并不能高枕无忧,因为当监控点做得越多越立体化,360 度无死角后,每个最细节的点都有指标去度量,指标数据爆炸很可能成为另一个潜在的监控隐患。
监控、告警与运维
运营阶段要解决的问题
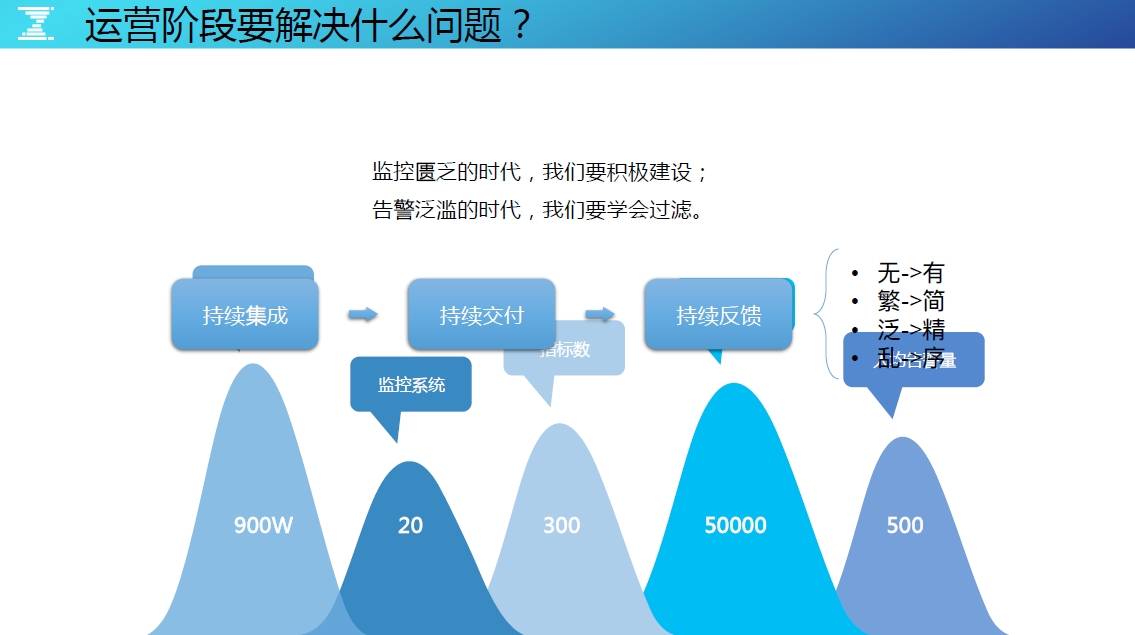
〓 繁——简
在具体生产过程中会产生运维的事件或者故障,经常会有死机,以及各层监控告警,这些繁琐的告警、故障,该如何简单化?
〓 泛——精
举个例子,在一台核心的交换机下,假设其下连有 1000 台的机器分布到数据层、逻辑层、接入层等等,当这台交换机故障不可用时,由于有立体化监控的存在,每个监控点都会产生大量的告警信息,要如何发现这些告警是由哪台核心交换机故障引起的?
〓 乱——序
由于指标采集方式和计数据量的不同,直接导致了监控流处理效率是不一样的。告警收到的次序不一样,要如何排序并有效识别优先级?
所以在监控匮乏的时代要积极地搞建设,但是告警泛滥的时候要学会过滤。
监控、告警与运维
监控对象与度量指标
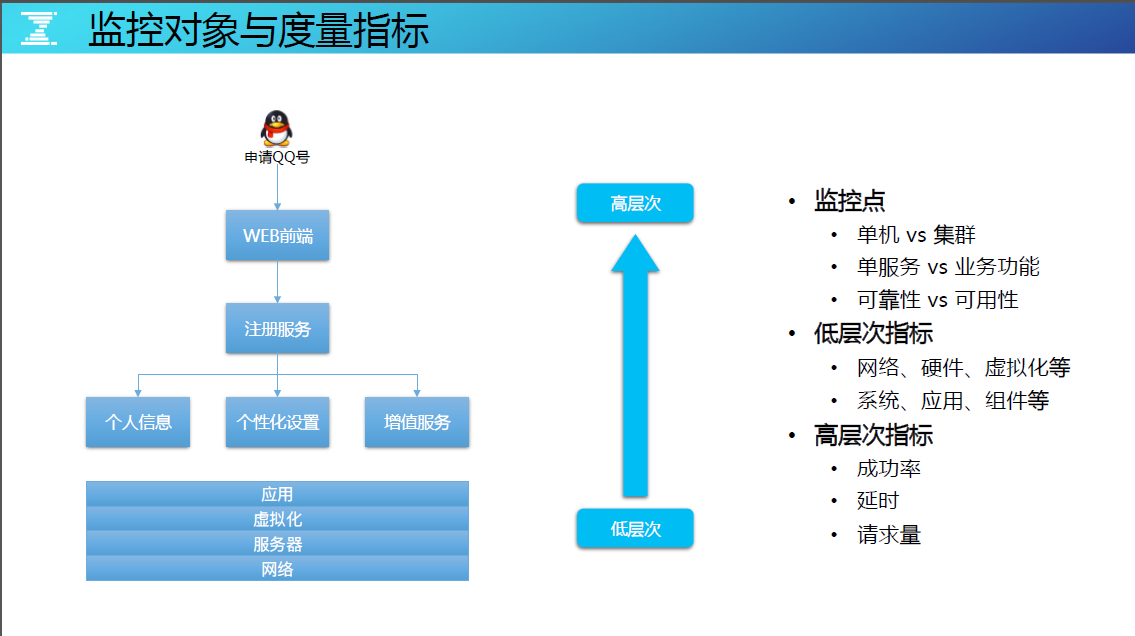
腾讯业务要监控的对象如上图左,按照业务逻辑从下往上,下面是通用的监控层面,网络、服务器、虚拟化还有应用,应用包括了组件的一些监控。
这里举了申请 QQ 号的业务场景案例,假设用户在 PC 端发起申请 QQ 号的业务请求,请求走到 WEB 前端,而后是注册服务,注册 QQ 包含了三个信息:个人信息、个性化设置、增值服务。是不是 QQ 会员,是否要开通会员类似的服务,这是业务逻辑。
基于立体化地监控,假设用组件监控,无论是 QQ 还是 QQ 空间、QQ 音乐,都有一些通用的指标可以衡量。如,打开的内存是多少?长连接数是多少?用户进程、吞吐量、流量、CPU,业务层面返回码分别是什么?省市连接的成功率、请求量的分布是什么?这都与具体的业务逻辑无关。
在做监控时,把指标划分成两大类:
☆ 低层次指标
把公共的、基础设施等在业务逻辑之下的指标称之为低层次指标,如网络、硬件、虚拟化等。
越低层次的指标让监控系统或是告警带来的噪音越大。在规划监控处理或者优化监控策略时,要尽量把低层次的指标自动化处理和收敛掉,尽量以高纬度指标来告警,因为这才是最核心最需要关注,最能反馈业务可用性的告警。如果一个公司用低层次指标来代替高层次的指标作用,那质量是很难管理的。
☆ 高层次指标
高层次指标要能更直接地反馈业务可用性的情况,如成功率、延时、请求率等。
高层次的指标,要能够实时反馈业务真实状况的,在海量规模的业务运维场景下,人没办法看到单机的层面,必须要看到集群的层面。
以模块为统一的运维对象,模块是提供单一业务功能的集群。为什么要管理到集群?简单理解就是把运维对象给抽象,做减法。拿腾讯的 SNG 来说,10 万+服务器,抽象成模块后只有一万多个模块,较之前面对 10 万个运维对象 N 个指标的告警量,现在面对一万个模块告警量要轻松不少,如果再把低层次的告警优化掉,可能只面对 5000 台的告警。
在高层次指标中,还要有效的区分开单服务的高层次指标,和业务功能的高层次指标。要理清两个概念,可靠性和可用性。
可靠性是指单个服务失败的次数,由于单个服务的失败并不一定会影响整个 QQ 号申请业务功能可用性的下降,因为微服务自身有失败重试的逻辑,在腾讯的运维经验中,我们会在可靠性和可用性之间做出一定取舍。
低层次指标虽然比较基础或者可以自动化解决,但往往是一些高层次指标的根源问题,善用低层次指标能够帮助运维快速定位高层次指标故障。
监控、告警与运维
监控的本质
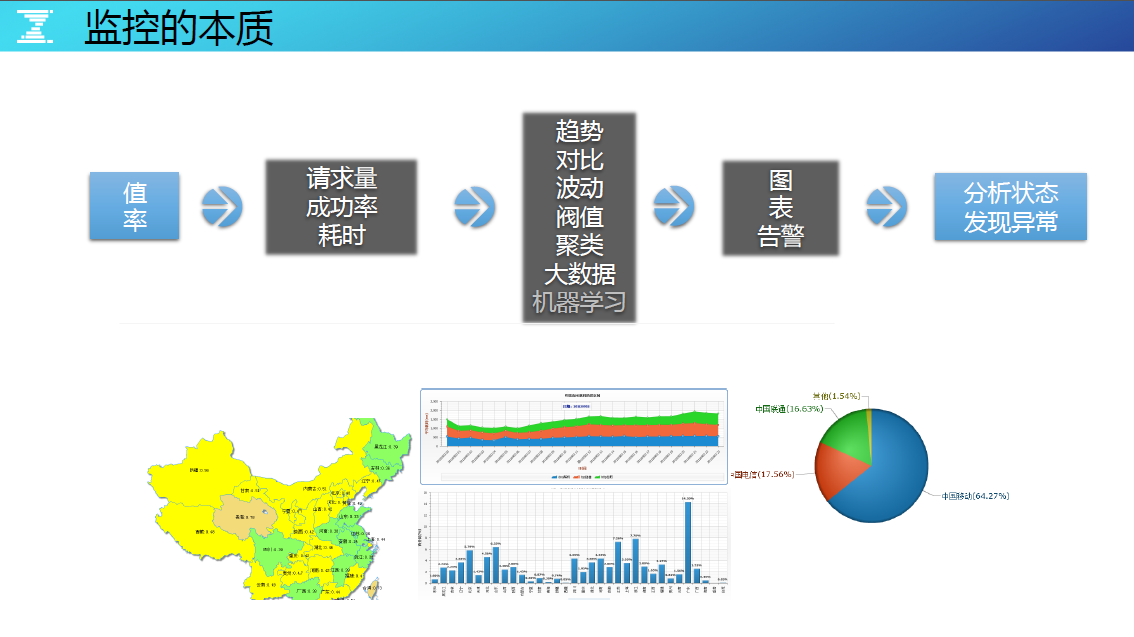
监控无非是监控很多的值和率。把值和率分开是有考虑的,因为值报上来就是一个值,率是经过一定的计算才变成率的,其实都是把扁平化的信息包装成高层次的指标。
监控最终的目标都是要分析状态和发现异常,要从图、表或数据中,分析现在业务的真实情况,分析现在服务是否有异常。
监控、告警与运维
误告警解决办法

立体化监控,会带来监控指标的爆炸,更有可能带来告警数据失控,如果不能妥善处理,就会把告警通知演变成“狼来了”,失去了原来警报的效用。想有效解决告警多、误告警多要面对几点:
◇ 关联分析
把一些真正重要的,需要通过事件、活动、指标提取出来。不要把什么事情都告警出来,从而过多消耗告警的诚信。
◇ 无误告警
怎么样把收敛策略、屏蔽策略用到极致,必要时可以将两者组合,以达到更强化的效果。
◇ 持续运营
做好持续运营就是做好跟进,确保重要事情有人跟、有人度量,防止问题再三出现,要在流程上有保障的机制。
这样就要求有一个质量体系来闭环管理,当监控发现业务架构不合理、代码不合理等问题,能够通过该质量体系,推动业务、开发、运维去将优化措施落地,这也是为了最终的商业价值,这是 DevOps 的观点。
监控、告警与运维
案例:海量数据分析思路
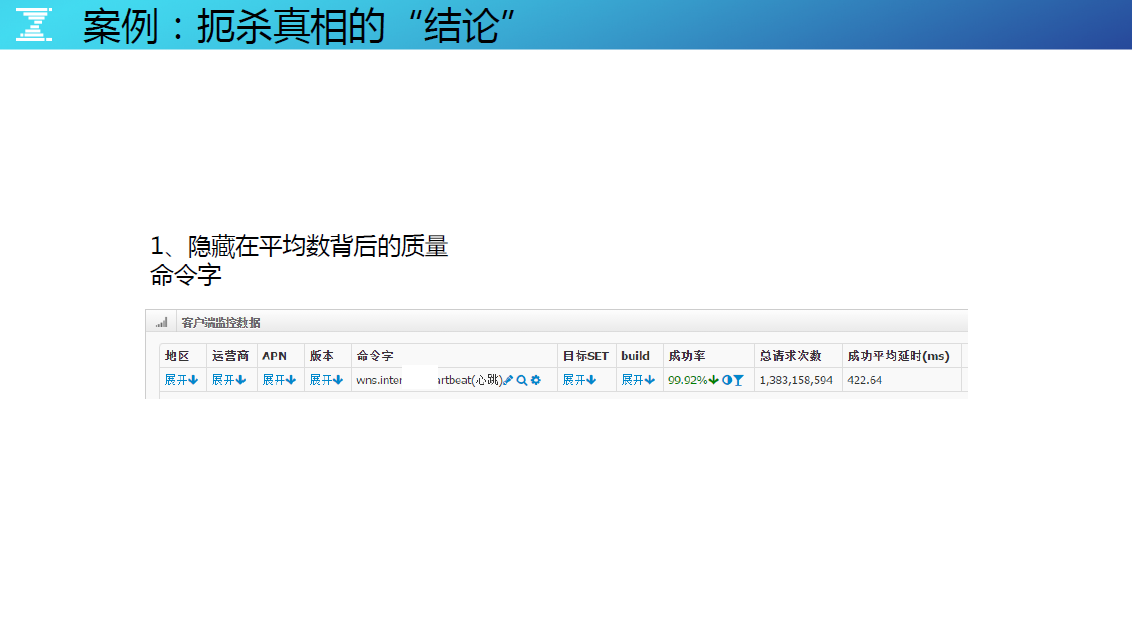
这是手机 Qzone 的一个多维监控案例。当客户端第一次连接服务端,会有一个心跳包,它是一个命令字,我们以成功率来度量其质量,其实就是考量它维持长连接的可靠性。(如果长连接断开移动客户端连服务端的话要跟基站建立长连接,起码 3、4 秒耗掉了,好友消息没有办法接收。)如图,一般的功能,我们要求三个 9 的质量。但是千万别被平均数所蒙骗了,一起展开看看真实的情况。
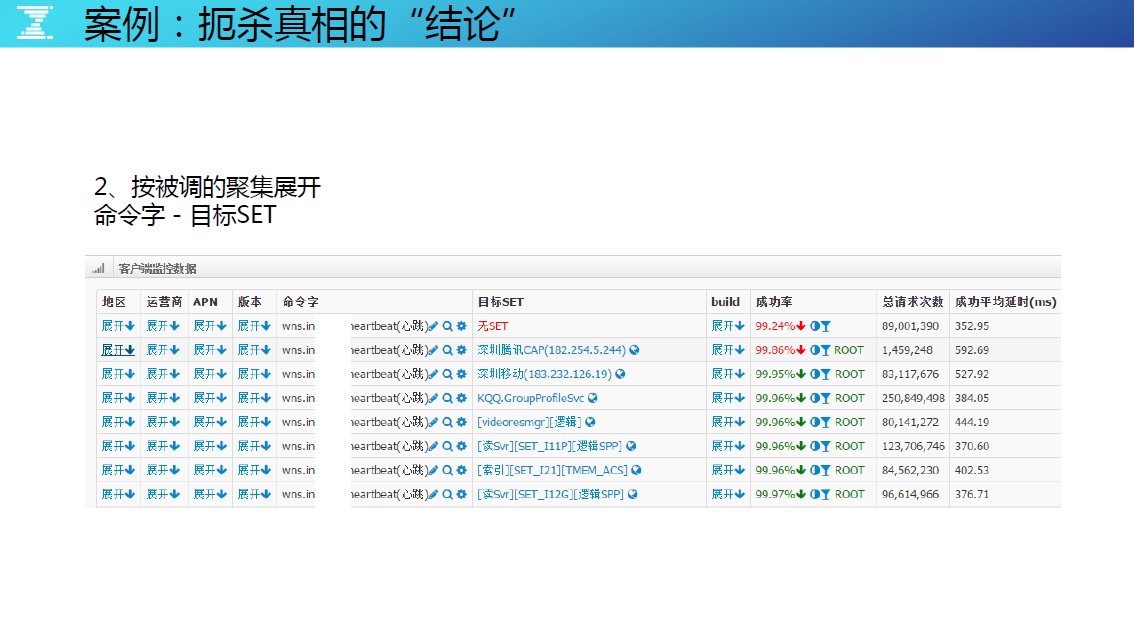
腾讯的服务是多地多活的,有一些分布在规模相对小的 AC 点,有些分布在比较大的 DC 点。根据全国用户访问服务端点的不同,腾讯内部称之为 SET。讲平均数按 SET 的维度展开,为什么“无 SET ”的成功率只有 2 个 9 ?再展开一下。
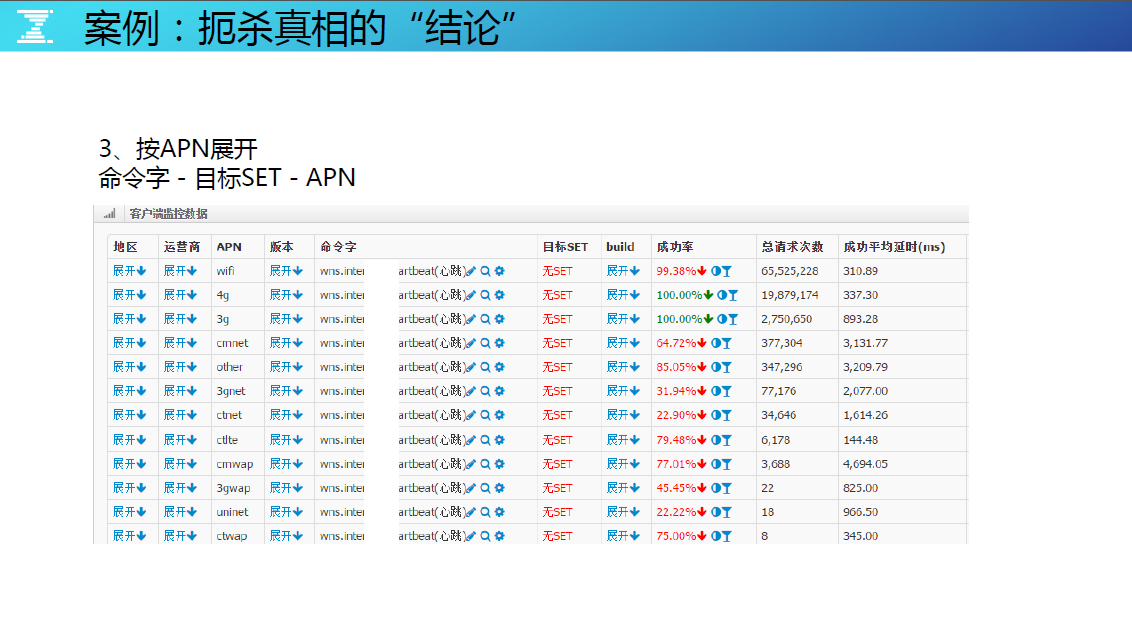
按 APN (接入方式 WIFI、4G、3G 等)展开,服务质量越来越差,只有两个绿了,发现 4G 是 100%,WIFI 环境为什么只有两个 9 了?
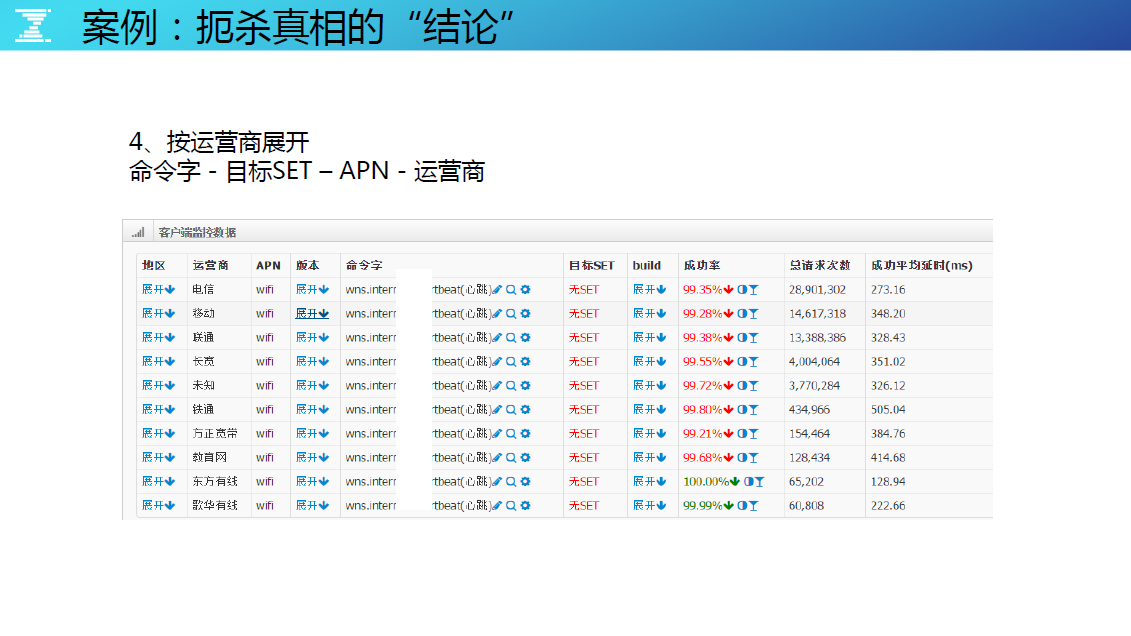
按运营商展开,质量数据更红(差)了,虽然符合预期,但最终的问题还没有找到。
继续按地区展开,发现全是红的,但还是没有头绪。
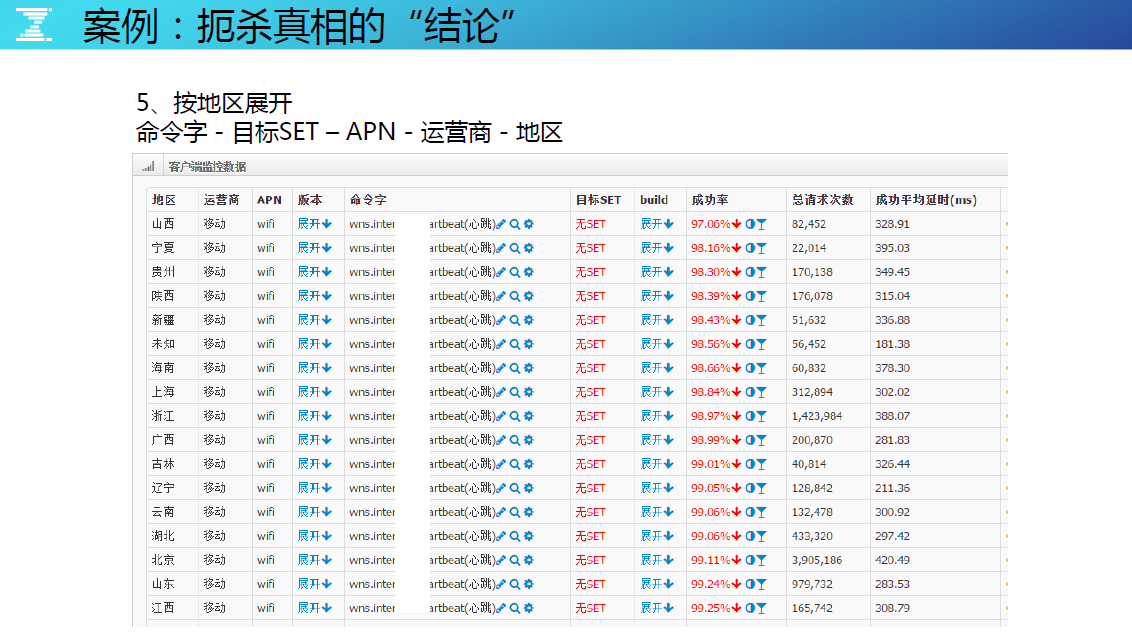
当再次按地域展开时,展开到浙江地区,发现出错的全是安卓版本。而 IOS 的版本全是 100%的成功率,共性问题呼之欲出。
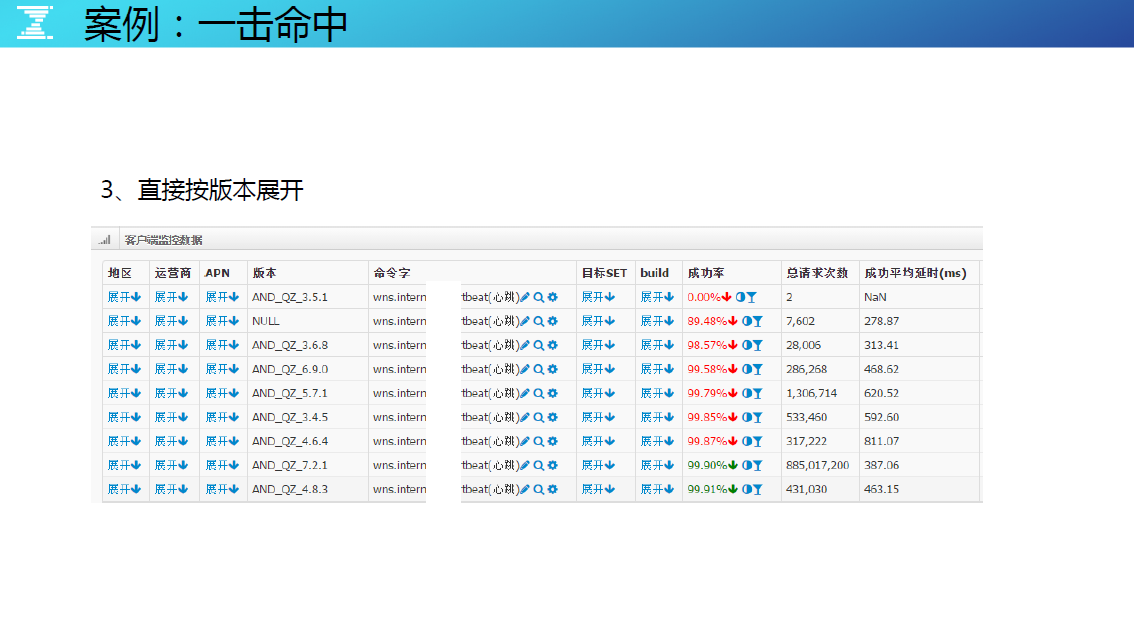
这时候回过头来检讨一下排障的思路,可能打开的方式不对。在第三步的时候直接展开,好像真相就已经出来了,其实是安卓的某几个版本可能有这样的隐患,导致这个心跳逻辑有问题。
这里说明一个问题,对待海量多维数据的处理,分析方案很重要,在规划和建设监控体系时,应该考虑好这点。今天给大家带来 3 个小技巧,希望能给大家在做监控数据分析时有帮助。
海量分析三技巧
海量分析三技巧
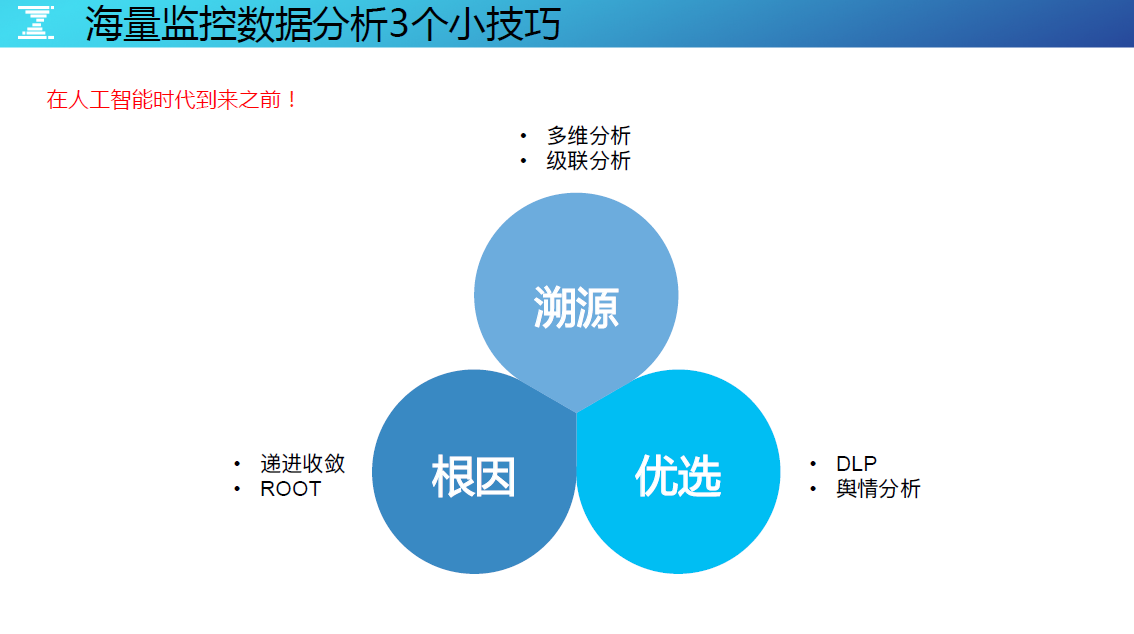
海量监控数据分析的技巧:溯源、根因和优选。
为了加快告警信息量的处理往往把监控的协议格式化,格式化处理完了之后再进一步格式化,把很多原始数据的蛛丝马迹丢掉了,导致没有办法查到真正的问题。因为之前做的格式化会让监控数据失真,影响排障的效率,所以上报协议的时候尽可能的保留字段。
海量分析三技巧
溯源分析
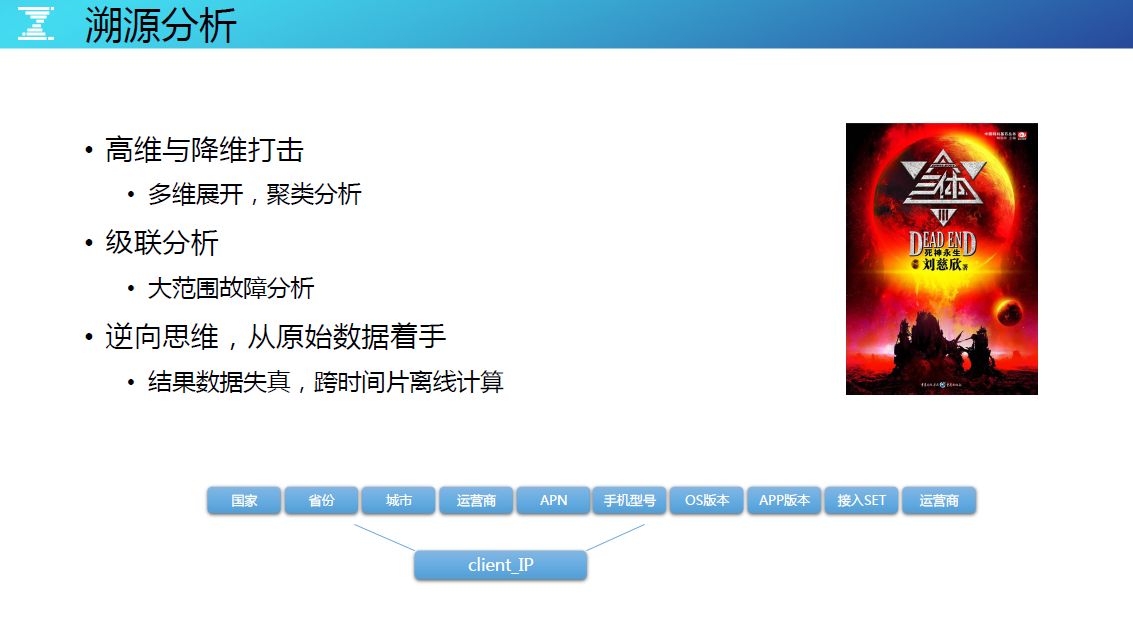
〓 高维与降维打击
高维与降维打击,把一个指标的结果值或率以不同的纬度展开,要把每一个维度的指标组合状态异常都变成告警,这是很不现实的,因为压根处理不过来。反而多维度的指标异常能通过日常报表汇总分析就能发现异常,然后通过考核去持续的推动,把异常指标给理顺、优化掉,这是就是高维、降维的打击。
〓 级联分析
网络有一个词叫微突发,网络突然拥塞了,导致一大波低层次和高层次的告警产生。比如,一个交换机异常,引发下联服务器爆炸式的告警。当此类情况发生,统一告警平台全部不理,做好全局的收敛,以保证监控告警的有效性不受影响。
〓 逆向思维
不能只看结果数据,要回到原始数据来看。如果要做到逆向思维可生效,流处理集群在真正加工完,存储的结果数据之前要做最基础的分析,把那部分日志备份到大数据平台做离线的计算,然后结果数据再走正常的流,去做告警也好,异常波动也好,因为很多异常的东西必须要看到原始数据。我们曾经深入分析相册上传照片的流水日志,找到了大量异常的用户照片,从而节省了大量的运营成本,这些都是结果数据无法做到的效果。
海量分析三技巧
根因分析
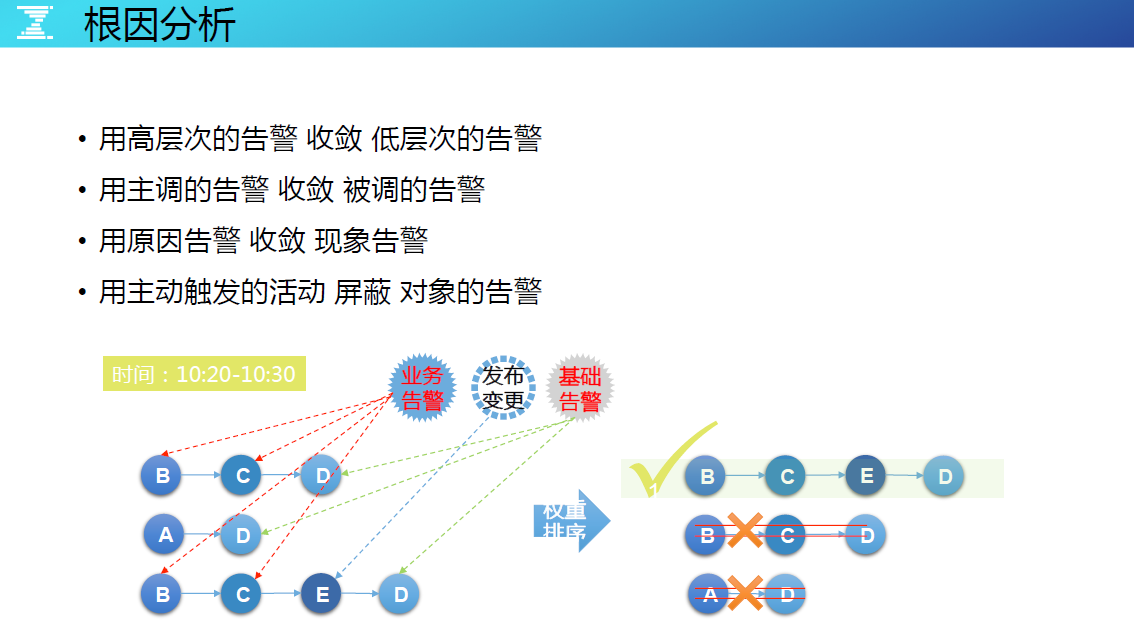
用高层次的告警 收敛 低层次的告警 同一个集群下既产生了低层次告警,又产生了高层次告警,低层次的告警不用发。
用主调的告警 收敛 被调的告警 模块 A 调用模块 B,B 挂了,A 受不受影响?从保障业务可用性的角度,如果 A 没有产生告警,证明该场景只是 B 的可靠性告警,告警通知开发而不是运维。但如果 B 挂了,A 也产生了告警,运维就应该收到 A 的告警,B 还是告警给开发。推进告警分级(分值、分级、分人、分通道)的机制,其实是慢慢把一些运维要做的事情分给开发,运维只看核心的,软件可靠性这些开发来看,可靠性是开发的问题,可用性是运营质量的问题。
用原因告警 收敛 现象告警: 在业务逻辑的调用联调中,用原因告警收敛掉现象告警。
用主动触发的活动 屏蔽 对象的告警: 有些告警是由于变更行为引起的,要收敛掉。如正在做升级引发了告警,运维系统要能关联这些事件与告警。有高层次告警、低层次告警,还有运维的活动事件,都把这些集中在一起,通过权重的算法,有一个排序决策说告警应该是告这条链路,而不是每一个对象都重复告警。
海量分析三技巧
优选指标
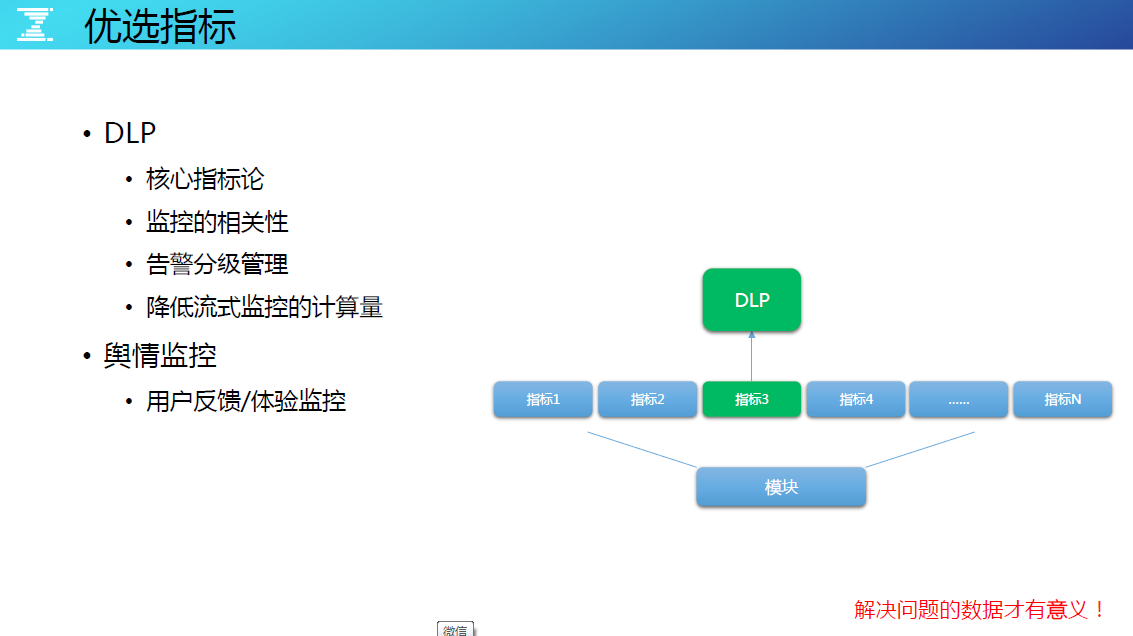
核心指标论
优选指标应该是第一次对外分享,腾讯内部的系统代号叫 DLP,是一种通过人工来筛选核心指标的方法,在大数据时代的今天,这种做法稍稍有些不够优雅。如一个模块可能有 300 - 400 个指标,这 300 - 400 个指标中,包含有低层次的指标,高层次的指标,但当这个模块出问题的时候,这 300 - 400 个指标可能都会产生告警,那么应该怎么样收敛呢?倘若我们提前已经对该模块进行过核心指标的人工筛选,这个指标能代表模块最真实的指标。
监控的相关性
监控是相关的,例如 300 个指标告警了,最核心的那个也会告警,最核心的告警了这 300 个指标可以不告警,只看核心的就可以了,为什么要人首选核心指标,因为暂时没有办法人工识别。
告警分级管理
基于核心的指标对告警做分级,非核心的开发自己收,核心的运维收,做到高规格保障。
降低流式监控的计算量
监控点越多,流的数据越大,整个监控流处理集群规模很大,10 万台机器光是流处理的集群都是接近 1500 台,当运营成本压力大时,也可以重点保障 DLP 指标的优先计算资源,保证优先给予容量的支持。
SNG 织云监控系统
用户舆情分析监控
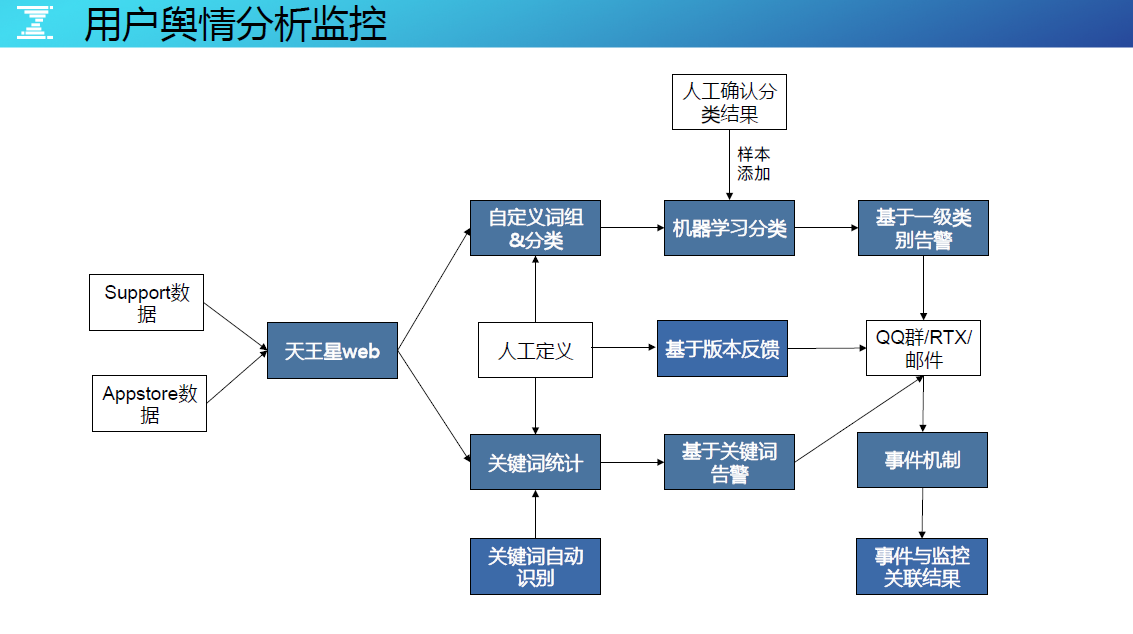
还有一个很核心的指标,就是织云用户舆情监控系统。简单介绍这个系统,用户舆情监控顾名思义就是监控用户的声音和反馈。用户的意见反馈来源可以分几部分,一是 AppStore 的入口,另一个是 App 内嵌的反馈入口,还有的就是腾讯的用户反馈论坛,所有的数据都会被汇集到织云舆情监控平台上,然后通过机器学习实现自动分类。系统会把类似“ QQ 空间打不开”、“ QQ 空间用不好”等这些词汇进行语意分析和归类,然后统一告警成“ QQ 空间异常”,时间间隔是 15 分钟颗粒度,技术细节不重点介绍。
当实现了用户舆情监控后,我们基本有把握说业务监控是 360 度无死角的(假设用户都会反馈问题,且不考虑时间因素)。但这套监控先天就有门槛,因为要基于用户的主动反馈行为,同时需要较多的用户反馈数据量,腾讯的用户量基数很大,用户主动反馈的量也很大。舆情监控可以用于监控技术上的质量问题,也能用于监控产品的体验或交互问题。
SNG 织云监控系统
有策略更要有自动化
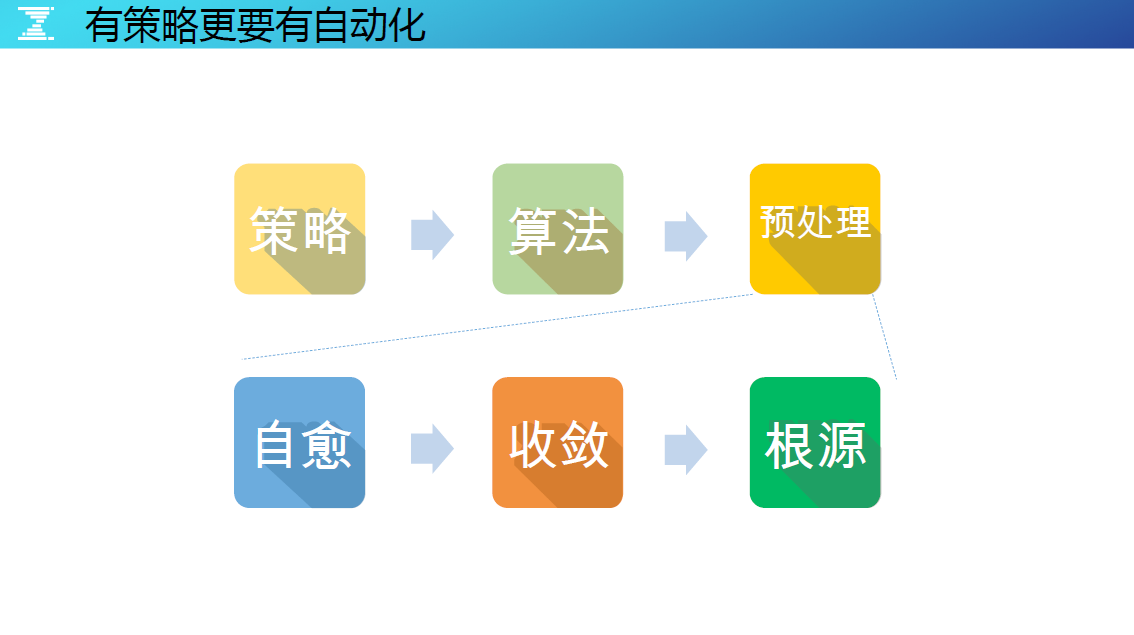
告警自动化处理的前提是标准化运维体系,在 SNG 织云监控体系下,所有告警处理会先经过预处理策略,然后再经过统一告警平台的策略和算法,最终才被决策会否发出。
SNG 织云监控系统
精准试用的算法与策略
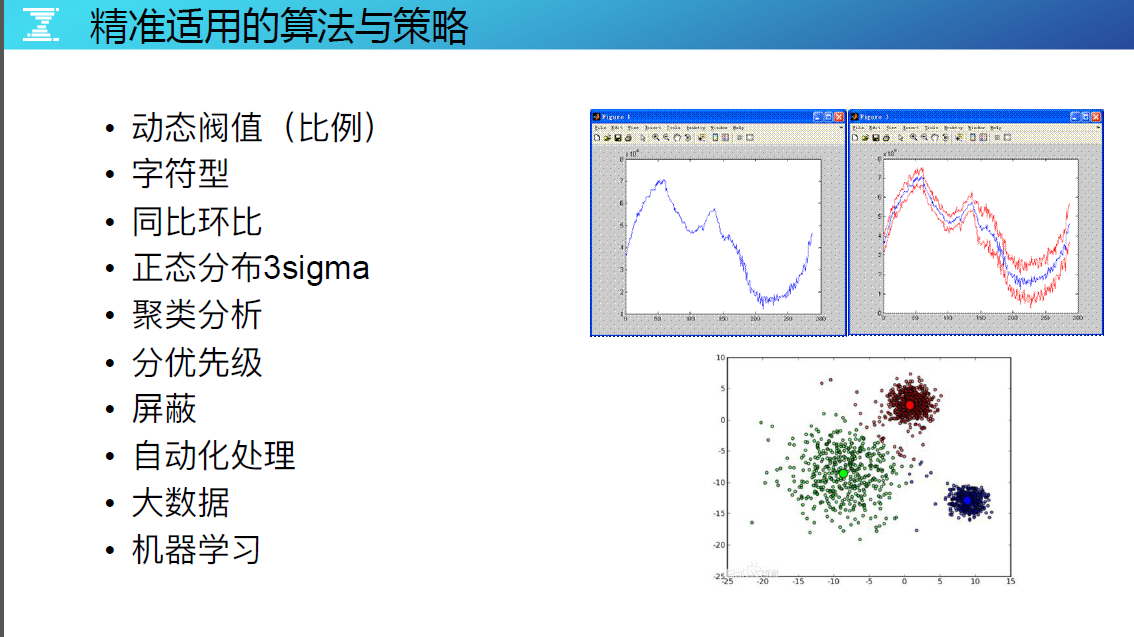
在定义指标状态异常时,我们的经验是尽量不要用固定阀值,要用也是动态阀值,否则在监控对象的阀值管理上就会有大量人工管理的成本。其他的推荐策略如图。
SNG 织云监控系统
常见业务监控图形与策略
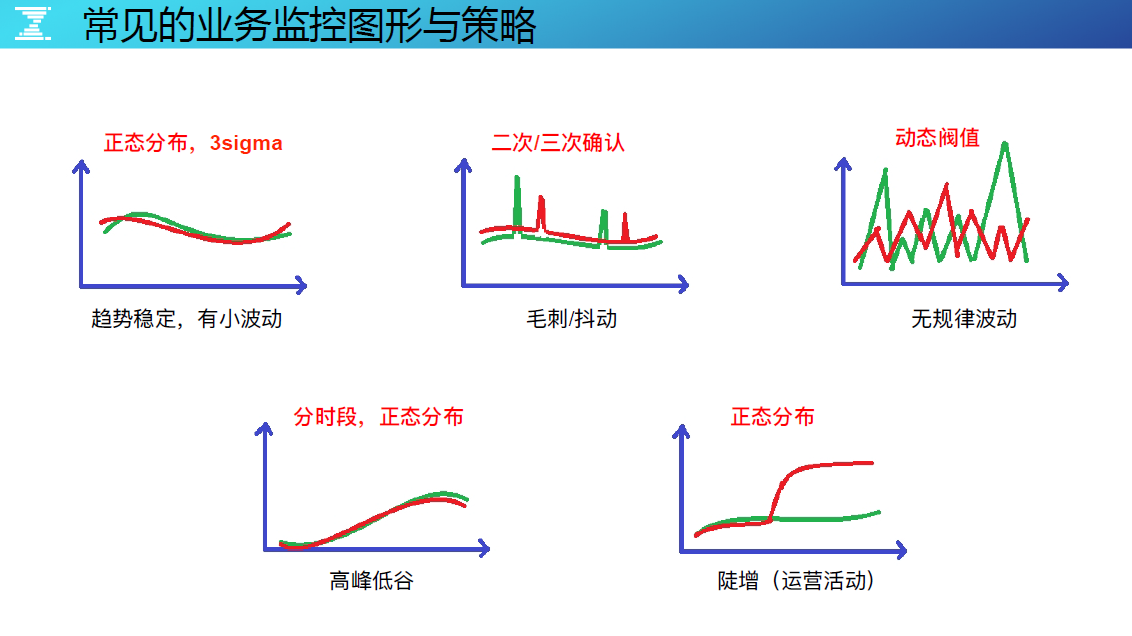
我们在日常运维工作中,面对的监控图形如上图,趋势有小波动、毛刺、无规律的,建议有针对性的套用监控策略,让监控告警更精准。
SNG 织云监控系统
案例:监控自愈
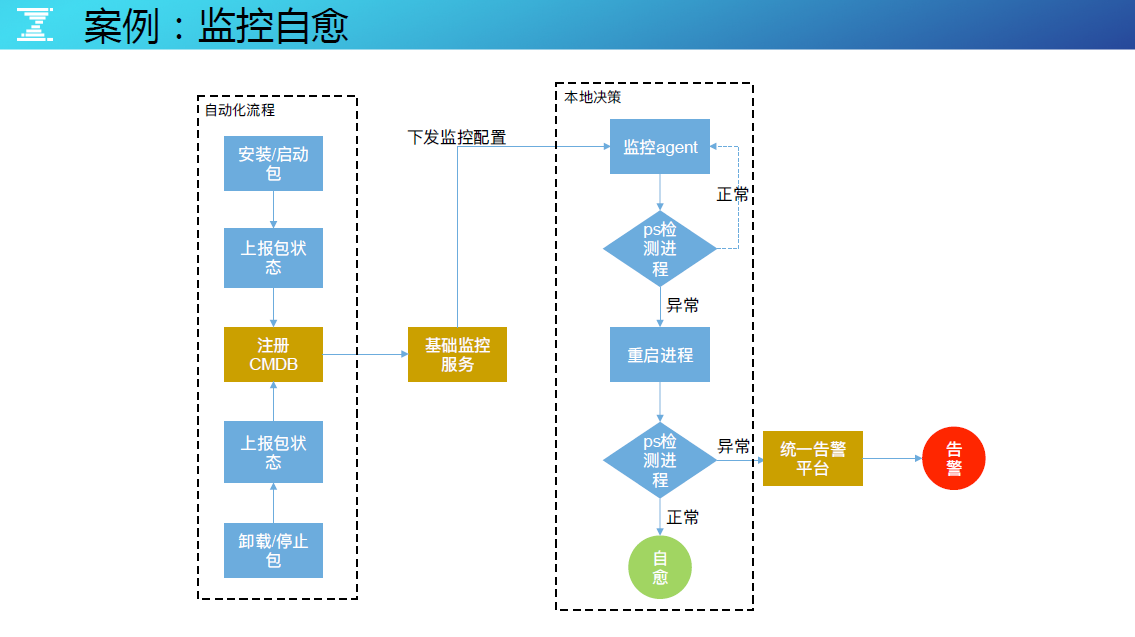
分享一个织云监控实现进程自愈的案例,流程中的模块在部署时,运维自动化流程就会把进程和端口的信息注册到 CMDB 中,然后监控服务会读取该模块需要监控的进程与端口信息,并把监控配置发送每台机器的监控 Agent 上,本地的监控 Agent 通过定时 Ps 检测进程和端口的运行情况,如果发生异常,则自动通过标准化的管理找到命令进行启动,如果启动成功便实现了进程自愈。
如果启动不了发给统一告警平台,统一告警平台来决策是否需要告警。当该告警原因是因为基础设施正在做变更影响时,也不会发出告警。一系列的监控自愈方案都是构建在织云的自动化运维体系中。
SNG 织云监控系统
常见的收敛算法
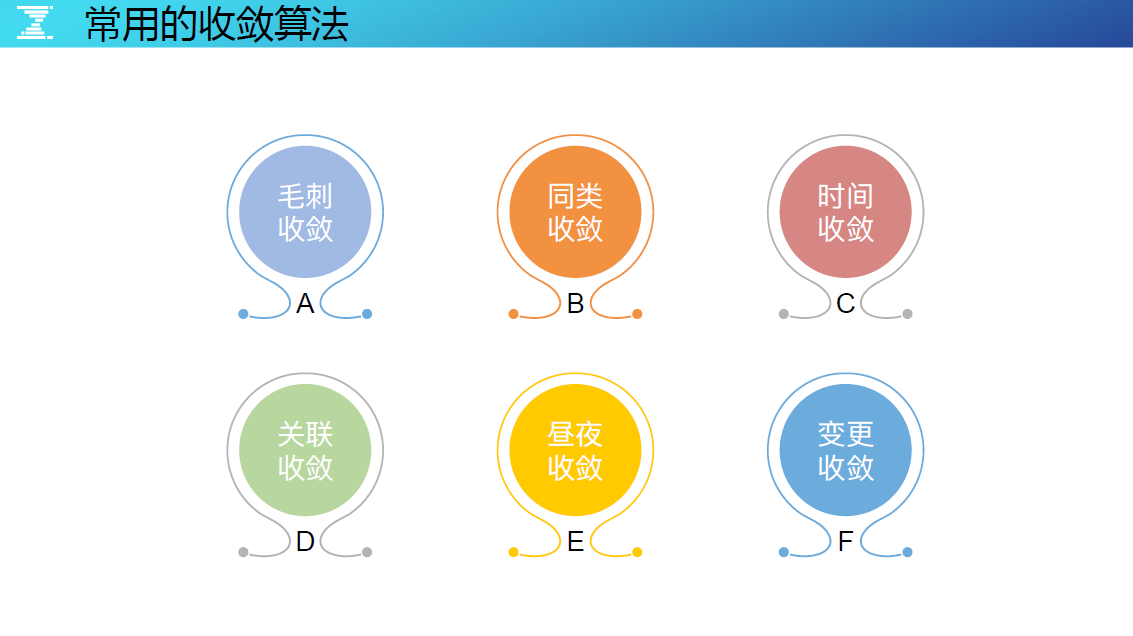
◇ 毛刺收敛
在织云监控中,告警策略为了防止毛刺的影响,会将告警策略定义为 10 分钟发生 3 次类似的模式。
◇ 同类收敛
一个模块有 300 个监控实例,产生了 300 条告警,只要有一条告诉给运维,对于运维同类收敛掉了。
◇ 时间收敛
生产环境中有很多定时的任务,如定时跑量会引起 I/O 的陡增等异常,这种可以针对性的收敛掉。
◇ 昼夜收敛
有一些告警,在分布式服务的高可用架构下,晚上不需要告警出来,可以等白天才告警,更人性化的管理。
◇ 变更收敛
如果告警时间点有运维的活动,就要收敛掉它。怎么做到的?取决于要把运维的活动都收口在标准化运维的平台,运维平台对生产环节都要将变更日志写入在变更记录中心,然后统一告警系统能够关联变更记录来决策是收敛还是发出告警。
SNG 织云监控系统
织云监控构建的质量体系
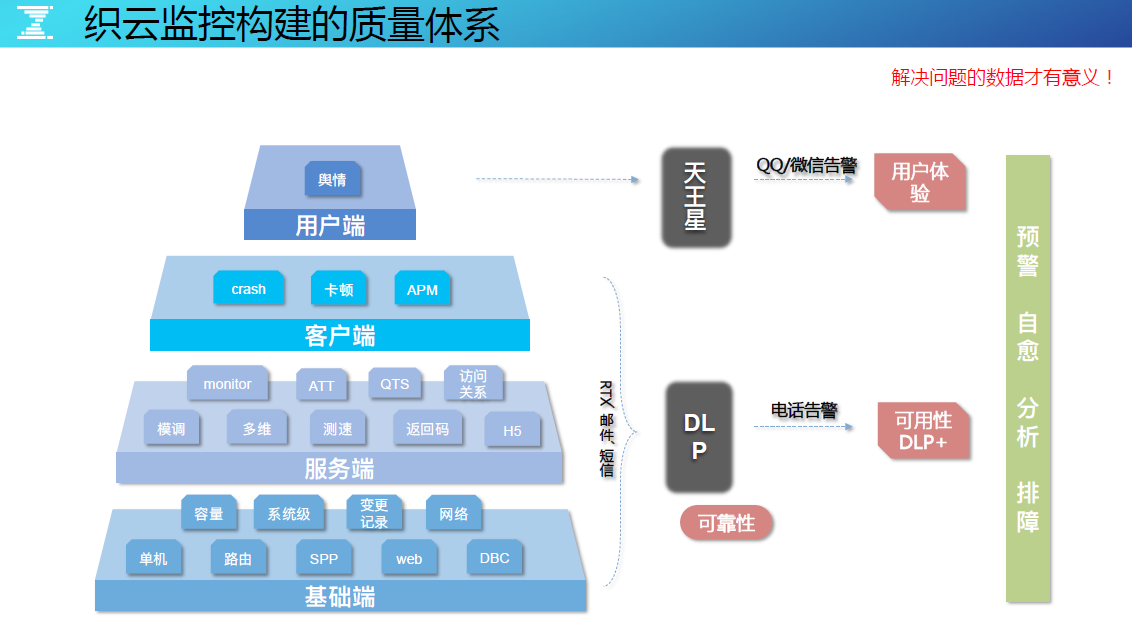
织云监控构建的质量体系,分成用户端、客户端、服务端、基础端,定义核心指标 DLP,并且善用分级告警、分渠道告警,结合短信、QQ、微信和电话等渠道实现告警通知,整个质量监控体系都是围绕预警、自愈、分析、排障碍的能力构建。
SNG 织云监控系统
织云监控:质量体系
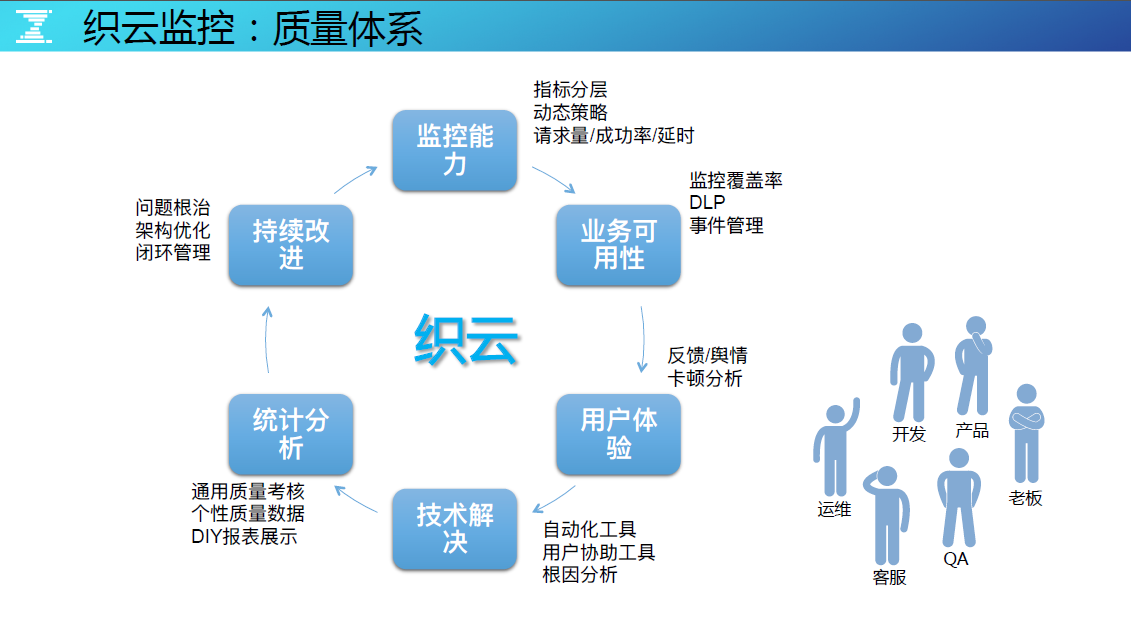
织云监控的质量体系,希望打造一个闭环,能够实现持续反馈、度量、优化,让团队间能够有效地协同工作,更高效更有效。
监控能力
全局地看、需要什么样的监控能力和监控点,同时要理清指标是怎么分层的,哪些指标是重要的?最终把它转成业务看得懂的高层次指标。
业务可用性
运维要看什么,要看可靠性还是可用性,如果规模不大看可靠性可以,但是在海量的场景下可靠性太细,要抽象核心指标来度量,用于衡量可用性。可靠性则可以通过考核体系去度量与管理,结合 QA 和老板的力量来推动开发团队的投入与优化。
用户体验
做技术运营会有视角的盲点,会经常迷恋可用性的数据是 4 个 9、5 个 9,但这并不完全代表服务质量好,当用户连接不上我们的服务端时,几个 9 的意义都不大。这是一个很现实的问题,因此用户体验监控一定要做,因为内部的可用性再高都不代表用户用得好。
技术解决
要有技术解决方案和自动化工具,还要有协助用户排障的工具,以及根因分析的算法平台等等。
统计分析
最终形成可度量的指标、可考核的、可展示的,最好是 DIY 展示的,监控数据的统计 /报表能力服务化,应发挥更多的角色来使用监控数据,而非仅限于运维角色。
持续改进
最终持续的改进无论是架构的问题、代码的问题,还是因为标准化的问题或非功能落地推进不了的问题,都是需要数字来度量和推动。最好,这个数字要能间接的反馈商业的价值,也就是 DevOps 提倡的思路。
最后,质量体系肯定是反作用于监控能力再去形成这样的闭环,跟开发怎么沟通?跟产品怎么沟通?跟 QA、跟客服怎么沟通?要把他们用起来,要把他们关注的点牵引住,最终落到运维想实现的目标上是最好的,这很 DevOps,也撬动了老板的思维,争取从上而下的支持做好质量体系的建设。
DevOps 最后一棒
结语
我们经常说 DevOps 很难落地,为什么难?因为我们总是想要去影响老板,先改变文化再改变工作方法,但这谈何容易。如果是运维和开发能联合起来,先从小的重点的业务抓起,用数据说话体现 DevOps 能给业务带来的最终的商业价值,说不定会起到事半功倍的效果。
目前尚无回复