
上一篇分享了机器学习中特征的基本处理方法,然而上一篇还是没有解决一个根本的问题,就是如何选择因子。
上一篇传送门: https://uqer.io/community/share/583e9147228e5b49f34ad1ff 机器学习特征预处理 preprocessing 与 PCA 降维对模型有效性的帮助
这一章,我决定在特征工程之前的因子选择环节,进一步研究。
而因子那么多,怎么选择更有效的因子,这时候我想到之前看到的一篇研报。
研报中提及了一个因子贡献度的概念,简单解释一下。
因子贡献度的含义如下:
1.首先将股票池中的股票按因子进行排名,分别选出排名靠前的 20%和排名靠后的 20%股票构成两个组合;
2.我们将两个组合的平均收益差和股票池中所有股票涨跌前后 20%股票的平均收益差相除,得到的比值即为因子贡献度;
根据定义,这个数值应该在-1 至 1 之间, 1 证明这个因子和涨跌幅完全正相关,-1 完全负相关, 0 是无关。
那我们不如把第十一课的策略改动一下,增加一个因子贡献度的计算,然后取贡献度高的因子做模型的训练,提高准确性。
以下策略是以全 A 股做股票池,每次保留前 5 位的因子做模型训练的结果。因子库挑选了大部分成长能力类因子,盈利能力和收益质量类因子还有估值与市值类因子。
(个人对趋势类因子和技术分析的因子不是很信任)
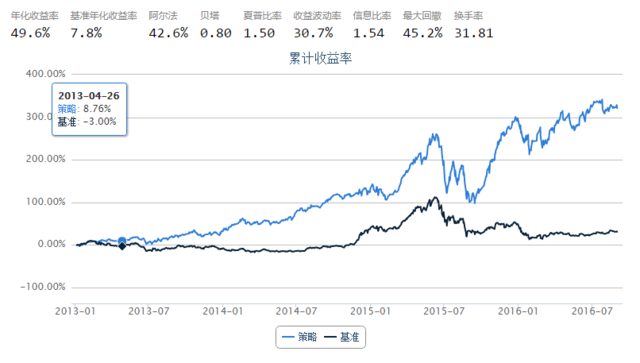
下面是策略源码,结果还是很不错的。
戳这里查看策略源码: https://uqer.io/community/share/58427dfc228e5b49f14ad45e
欢迎讨论!
上一篇传送门: https://uqer.io/community/share/583e9147228e5b49f34ad1ff 机器学习特征预处理 preprocessing 与 PCA 降维对模型有效性的帮助
这一章,我决定在特征工程之前的因子选择环节,进一步研究。
而因子那么多,怎么选择更有效的因子,这时候我想到之前看到的一篇研报。
研报中提及了一个因子贡献度的概念,简单解释一下。
因子贡献度的含义如下:
1.首先将股票池中的股票按因子进行排名,分别选出排名靠前的 20%和排名靠后的 20%股票构成两个组合;
2.我们将两个组合的平均收益差和股票池中所有股票涨跌前后 20%股票的平均收益差相除,得到的比值即为因子贡献度;
根据定义,这个数值应该在-1 至 1 之间, 1 证明这个因子和涨跌幅完全正相关,-1 完全负相关, 0 是无关。
那我们不如把第十一课的策略改动一下,增加一个因子贡献度的计算,然后取贡献度高的因子做模型的训练,提高准确性。
以下策略是以全 A 股做股票池,每次保留前 5 位的因子做模型训练的结果。因子库挑选了大部分成长能力类因子,盈利能力和收益质量类因子还有估值与市值类因子。
(个人对趋势类因子和技术分析的因子不是很信任)
下面是策略源码,结果还是很不错的。
戳这里查看策略源码: https://uqer.io/community/share/58427dfc228e5b49f14ad45e

欢迎讨论!
