
以下整理自 7 月 14 日第十二期技术分享内容,由 时速云 研发工程师 孟远 分享。
在本次分享开始前,让我们先回想下 Pod 。 Pod 直译是豆荚,可以把容器想像成豆荚里的豆子,把一个或多个关系紧密的豆子包在一起就是豆荚(一个 Pod )。在 k8s 中我们不会直接操作容器,而是把容器包装成 Pod 再进行管理(关于 Pod ,大家可以参考第二期的分享“谈谈 Pod 在微服务中的运用”)。 Pod 是运行服务的基础,那我们如何来管理 Pod 呢,下面我们就来聊一聊。分为这三个部分:
1. 使用 Replication Controller 来部署、升级 Pod
2. Replica Set – 下一代 Replication Controller
3. Deployment – 更加方便的管理 Pod 和 Replica Set
先举个例子
假设我们有一个 Pod 在提供线上服务,现在有如下几个场景,大家想想如何应对:
-
节日活动,网站访问量突增
-
遭到攻击,网站访问量突增
-
运行 Pod 的节点发生故障
第 1 种情况, 活动前预先多启动几个 Pod ,活动结束后再结束掉多余的,虽然要启动和结束的 Pod 有点多,但也能有条不紊按计划进行
第 2 种情况, 正在睡觉突然手机响了说网站反应特慢卡得要死,赶紧爬起来边扩容边查找攻击模式、封 IP 等等……
第 3 种情况, 正在休假突然手机又响了说网站上不去,赶紧打开电脑查看原因,启动 新的 Pod
Pod 需要手动管理,好累……
能否在 Pod 发生问题时自动恢复呢,我们先来看下 Replication Controller (以下简称 RC )
先说RC 是什么。 RC 保证在同一时间能够运行指定数量的 Pod 副本,保证 Pod 总是可用。如果实际 Pod 数量比指定的多就结束掉多余的,如果实际数量比指定的少就启动缺少的。当 Pod 失败、被删除或被终结时 RC 会自动创建新的 Pod 来保证副本数量。
所以即使只有一个 Pod 也应该使用 RC 来进行管理。
接下来我们看下如何创建 RC ,看这个定义文件 rc.yaml
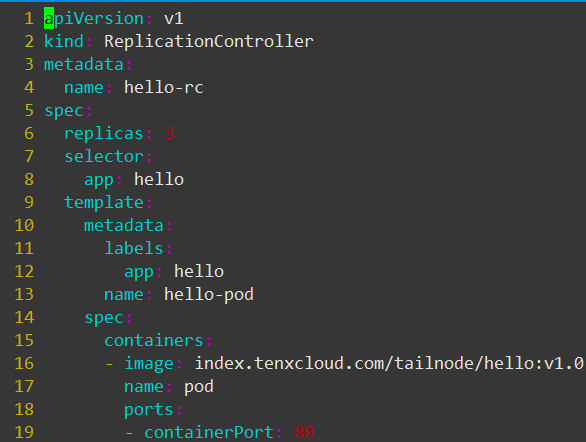
这个文件定义了 RC 的属性,我们先关注如下字段:
spec.replicas :副本数量 3
spec.selector : RC 通过 spec.selector 来筛选要控制的 Pod
spec.template :这里写 Pod 的定义(但不需要 apiVersion 和 kind )
spec.template.metadata.labels : Pod 的 label ,可以看到这个 label 与 spec.selector 相同
这个文件的意思是定义了一个 RC 对象,它的名字是 hello-rc ( metadata.name:hello-rc ),保证有 3 个 Pod 运行( spec.replicas:3 ), Pod 的镜像是 index.tenxcloud.com/tailnode/hello:v1.0 ( spec.template.spec.containers.image: index.tenxcloud.com/tailnode/hello:v1.0 )
关键在于 spec.selector 与 spec.template.metadata.labels ,这两个字段必须相同,否则下一步创建 RC 会失败。(也可以不写 spec.selector ,这样默认与 spec.template.metadata.labels 相同)
现在通过 kubectl 来创建 RC :

查看结果可以看到当前 RC 的状态:指定了需要 3 个 Pod 、当前实际有 3 个 Pod 、 3 个 Pod 都在运行中(图片较大只截取部分):
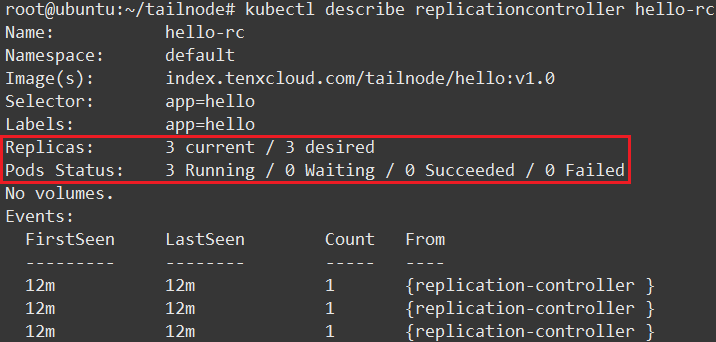
如果使用的镜像较大查看状态可能是 Waiting ,这是因为正在下载镜像,等待一段时间就好。

上面说过 RC 会自动管理 Pod 保证指定数量副本运行,我们来实验一下,看下图:
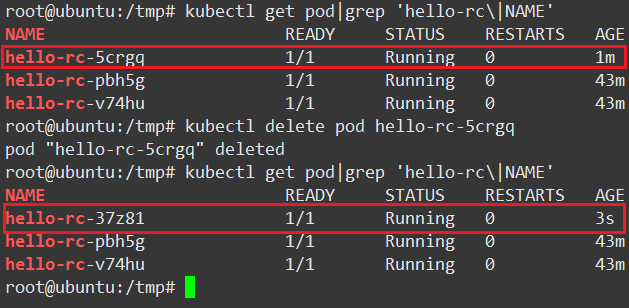
1.查看当前 Pod ,(注意 NAME 和 AGE 列)
2.删除 hello-rc-5crgq
3.再次查看 Pod ,发现新的 Pod 启动了(注意 NAME 和 AGE 列)
到这里我们对 RC 有了基本的认识,并进行了简单的使用。
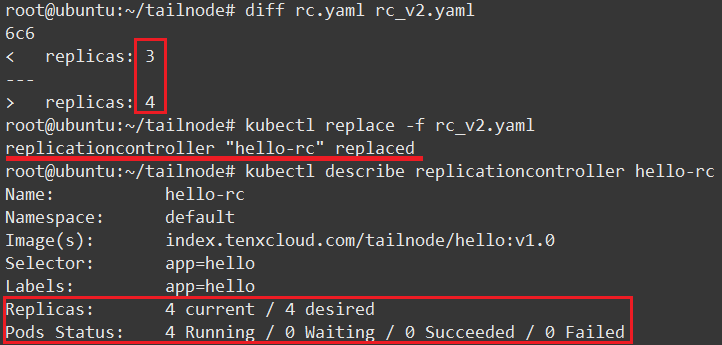
现在回到最开始的问题,如何通过 RC 修改 Pod 副本数量。其实非常简单,只需要修改 yaml 文件 spec.replicas 字段成想要的值,然后执行 kubectl replace 命令(或者使用 kubect edit replicationcontroller hello-rc 直接修改).
执行结果看下图:
当我们有新功能发布或修复 BUG 时使用滚动升级是不错的选择,可以使用工具 kubectl rolling-update 完成这个任务。对照下图我们来看下是如何进行的
使用命令 kubectl rolling-update hello-rc – image=index.tenxcloud.com/tailnode/hello:v2.0
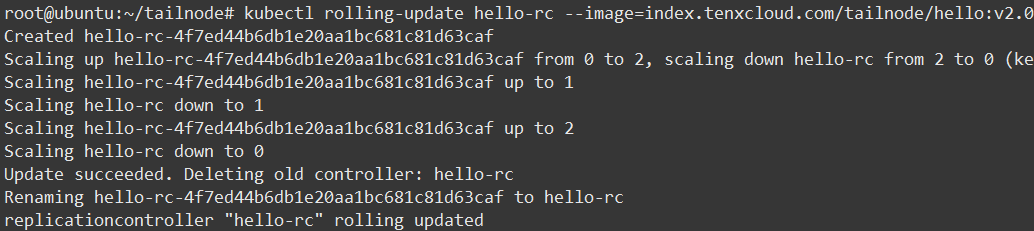
在另一个窗口查看 RC
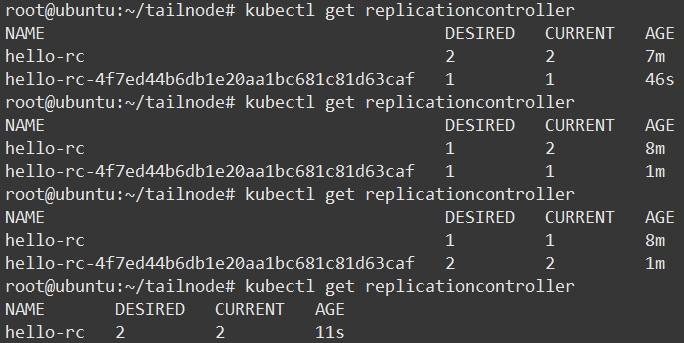
对照两张截图,我们能够看出升级步骤如下:
1.创建一个使用新版本 Pod 的 RC , hello-rc-4f7ed44b6db1e20aa1bc681c81d63caf
2.依次增加新 RC 的副本数量、减少旧 RC 的副本数量
3.当升级成功后,删除旧 RC
4.重命名新 RC 为 hello-rc
当 Pod 中只有一个容器时通过– image 参数指定新的 Tag ,如果有多个容器或其他字段的修改时,需要使用 kubectl rolling-update NAME -f FILE 指定文件
如果在升级过程中出现问题(比如长时间无响应),可以 CTRL+C 结束再使用 kubectl rolling-update hello-rc – rollback 进行回滚,但如果升级完成后出现问题(比如新版本程序出 core ),此命令无能为力,需要使用同样方法“升级”为旧版本
在时速云平台我们能够非常方便的使用弹性伸缩功能来调整 Pod 副本数量,还是举例说明:
启动一个能够输出 Pod 主机名和版本号的服务,看下图当前只有一个 Pod 副本运行
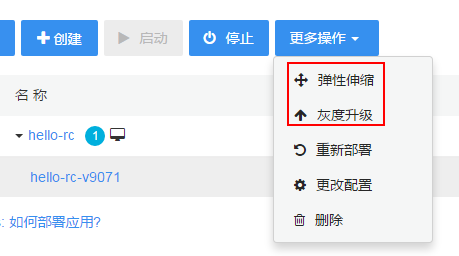
点击弹性伸缩,修改数量为 3 ,同时使用下面的命令测试,从输出结果可以看出提供服务的 Pod 数量变成了 3 个:
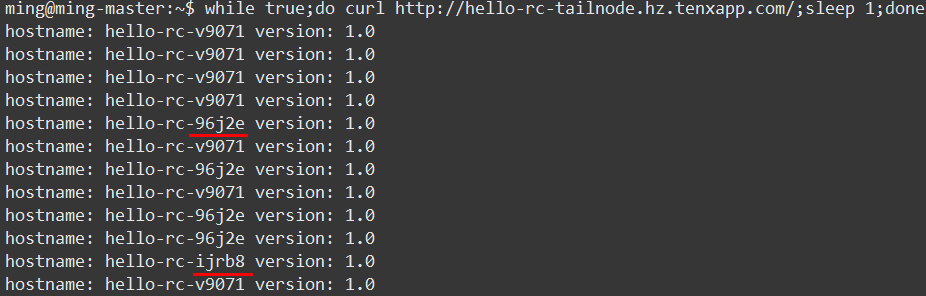
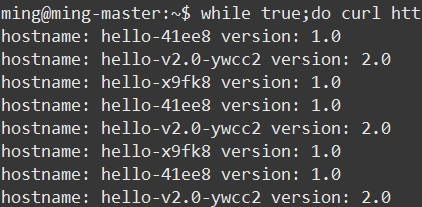
下面再来测试下灰度升级功能,修改目标版本为 v2.0 (之前是 v1.0 ,为了便于查看效果新建有 2 个 Pod 的服务),然后查看 Pod 变化
第一个新 Pod hello-v2.0-ywcc2 已经启动
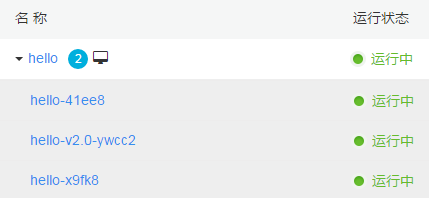
第二个新 Pod hello-v2.0-whtvh 正在启动
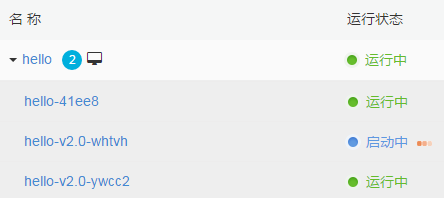
最后一个旧 Pod hello-41ee8 正在停止
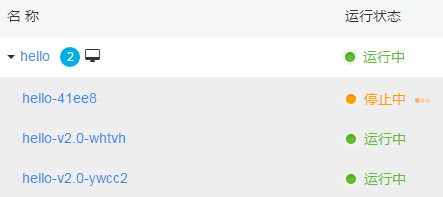
升级完成,只有两个新 Pod 提供服务
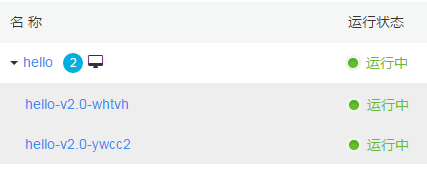
同时使用命令查看服务的响应如下:
k8s 是一个高速发展的项目,在新的版本中官方推荐使用 Replica Set 和 Deployment 来代替 RC 。
那么它们优势在哪里,我们来看一看:
-
RC 只支持基于等式的 selector ( env=dev 或 environment!=qa )但 Replica Set 还支持新的基于集合的 selector ( version in (v1.0, v2.0)或 env notin (dev, qa)),这对复杂的运维管理带来很大方便
-
使用 Deployment 升级 Pod 只需要定义 Pod 的最终状态, k8s 会为你执行必要的操作,虽然能够使用命令 kubectl rolling-update 完成升级,但它是在客户端与服务端多次交互控制 RC 完成的,所以 REST API 中并没有 rolling-update 的接口,这为定制自己的管理系统带来了一些麻烦。
-
Deployment 拥有更加灵活强大的升级、回滚功能
Replica Set 目前与 RC 的区别只是支持的 selector 不同,后续肯定会加入更多功能。 Deployment 使用了 Replica Set ,是更高一层的概念。除非需要自定义升级功能或根本不需要升级 Pod ,所以推荐使用 Deployment 而不直接使用 Replica Set 。
下面我们继续来看 Deployment 的定义文件,与 RC 的定义文件基本相同(注意 apiVersion 还是 beta 版),所以不再详细解释各字段意思
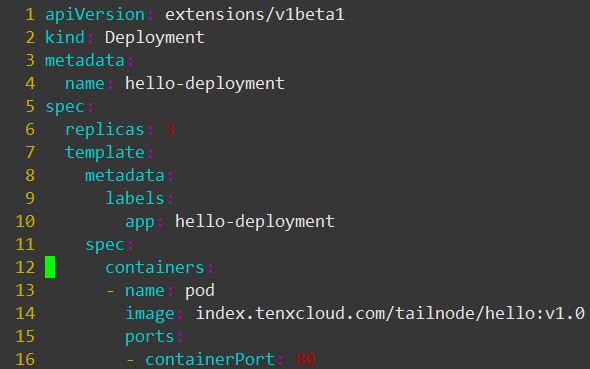
与创建 RC 相同,使用命令 kubectl create -f deployment.yaml – record 创建 Deployment ,注意– record 参数,使用此参数将记录后续对创建的对象的操作,方便管理与问题追溯
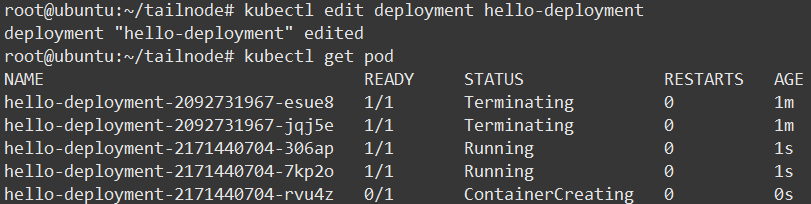
使用 kubectl edit deployment hello-deployment 修改 spec.replicas/spec.template.spec.container.image 字段来完成扩容缩容与滚动升级(比 kubectl rolling-update 速度快很多)
修改 image 字段为新版本镜像后查看 Pod ,在 STATUS 列看到正在执行升级的 Pod :
使用 kubectl rollout history 命令查看 Deployment 的历史信息

上面提到过 kubectl rolling-update 升级成功后不能直接回滚,不是很方便,那使用 Deployment 可以吗,答案是肯定的。
首先在上面的命令加上– revision 参数,查看改动详细信息如下:

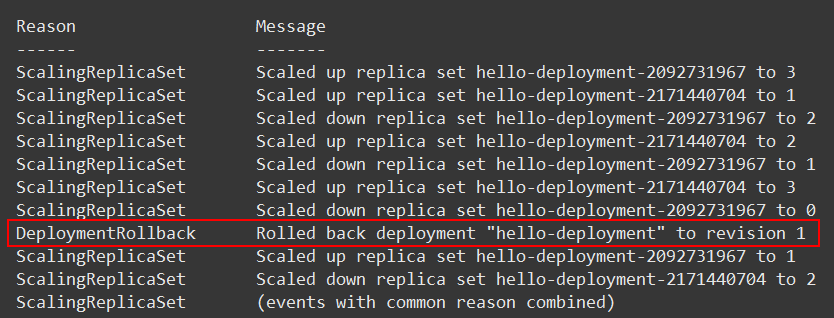
然后使用 kubctl rollout undo deployment hello-deployment 回滚至前一版本(使用– to-revision 参数指定版本)即可。
命令 kubectl describe deployment hello-deployment 查看详细信息,在 Message 一列看到回滚如下,详细的信息记录对于问题发生后的原因查找有很大帮助:
通过对比 RC 、 Replica Set 与 Deployment ,可以看出新的 Replica Set 与 Deployment 比 RC 要强大易用很多,但因为现在还是 beta 版本所以不建议在生产环境使用,不过相信不久的将来我们就能使用上。
Q&A
-
问:灰度发布, 可以指定新旧版共存么, 怎么整? 答:可以像上面说的那样,使用命令行工具创建新旧两个 RC ,然后分别指定需要的 Pod 数量。但目前时速云平台还不支持这种。
-
问:时速云是怎么保持 k8s master 的高可用的? 答:高可用目前是官方推荐的多 master standby 方式,以及我们自己的 agent 监管方式。
-
问: Pod 之间通信是不是也是用的 flannel ? 答: pod 和 pod 之间,可以采用官方推荐的各种网络解决方案,目前我们主要关注 flannel(vxlan )和 Calico
-
问: flannel 以及 calico ,你们选其一还是两个方案都在用?有测试报告吗? 答:两个方案都在用,测试报告以前分享过几种方案的网络性能比较,这里有一个 Calico 的,可以参考: https://www.projectcalico.org/ ... ance/
-
问: Replica Set 这个有 demo 的例子么? 答:因为一般 Replica Set 不会直接使用,而是通过 Deployment 来控制它,所以本次没有写出 Replica Set 的 demo
-
问: Deployment 现在是没有 rest api 修改 Pod 数量么? 答:有的, PUT /apis/extensions/v1beta1/namespaces/{namespace}/deployments/{name}
-
问:由于 k8s 严重依赖 etcd 中的数据,一旦 etcd 的数据紊乱,可能造成业务故障。这个问题在大量业务接入的时候可能有几率出现,时速云有解决方案吗? 答:这个问题,目前还没有碰到,不过我们会将服务信息同时存放到另外的存储中,也会对 etcd 进行备份,这样在出现故障时也可以很容易恢复或者迁移整个集群。
-
问:时速云用的是原生 k8s 吗,都做了哪些优化? 答:优化是有一些的,包括部署方式、网络、存储、以及一些用户体验上的优化为主,以便充分发挥 k8s 的一些优势。
-
问: Docker 1.12 版本开始集成了 Swarm 到 Docker Engine 中, Swarm 功能也变得越来越强大,那么时速云怎么看这个问题?以后考不考虑用高版本 Docker ,用 k8s 管理集成 Swarm 的 Docker ,会不会性能浪费? 答:我们目前主要关注 swarm , swarmkit 这些 docker 原生的工具,会去了解他们的主要特性,可以看到 swarmkit 正在向 k8s 方向迈进。
-
问:再问个问题,有状态服务的 pod ,挂载个数据卷(比如 rbd )。用 rc 或者 deployment 管理的 pod 重启或者升级以后,数据卷重新挂载到新的 pod 上会有什么问题么? 答:没有遇到过问题,理论上也不应该会有问题的。
-
问:能不能介绍一下怎么做用户隔离的,公有云的话,安全对大家很重要 答:可以参考 Calico 的网络隔离和 k8s 的服务、 api 访问控制,以及一些用户角色上的设计, k8s 在安全上还是考虑了不少东西的。
-
问:容器飘移和虚拟机飘移一样吗? 答:还是不太一样的,虚拟机可以支持热迁移,目前容器还不行。
报名方式:
有兴趣参与周四晚 8:30-9:30 时速云产品、容器技术相关分享的朋友可以添加微信号:时速云小助手(tenxcloud6),我们即可拉您进群~下次分享将于 7 月 28 日进行,敬请关注。