
春节前后,我实践了一个项目, 就是模拟一个类微信的系统。
希望能做到以下几点,
- 可以水平扩展,只要使用得当可以为千万级或者上亿的用户提供服务。
- 系统内部的任何模块都是可以崩溃的,但是不会影响系统业务
- 有代码 而不是只是画画图。
当然 你真的用这套代码 去支持上千万用户 那时间还太早了点。
发这篇文章的目的
- 帮忙看看设计有什么问题,有重大的设计问题,可以帮项目改进
- 有没有帮手可以一起做下去
- 觉得好可以加个星, 我觉得比我第一个项目的星应该更多才对
有问题也可以提在后面,我也可以回答
网页版 wiki 在这里
https://github.com/xiaojiaqi/fakewechat/wiki/Design
pdf 在这里
https://github.com/xiaojiaqi/fakewechat/blob/master/doc/cn/doc.pdf
项目在这里
https://github.com/xiaojiaqi/fakewechat/
下面是文章的前几部分
#构建一个你自己的类微信系统 ##可扩展通信系统实践
##前言
正如你们所知的那样,微信是一个非常成功的在线服务系统,由几万台服务器组成的系统为几亿人提供着稳定的业务服务。可惜作为一个普通的工程师基本上不可能有整体设计这样一个系统的机会,即使加入 xx 也基本是个螺丝钉,只见树木不见树林。看着 inforQ 上面高大上的架构设计,高来高去,个人资质驽钝,看过以后,所得有限,仍然大脑空空,没有太多收获。
2016 年春节前后,我个人做了一个可扩展的系统实践,试图构建一个可扩展的类微信系统,本文记录了构建一个设计,实践可扩展通信系统的过程。
本文只是从外部反推后的一个设计,实践,模拟,实现的过程,和真实环境也不存在任何可比性,本人也和 tx 公司没有任何交集。文中必然充满了臆想,猜测以及错误,不能对本文的任何正确性做任何保证,也不对可能造成的损失负责。如果你愿意给出任何建议意见欢迎 email ppmsn2005#gmail.com. 本次设计开发,实验所使用的所有代码和文档都可以在 http://www.github.com/xiaojiaqi/fakewechat 里找到。
##1. 目标及局限性 ###1.1 核心目标:
这个系统可扩展,可抗压,稳定并且正确服务。
- 可扩展, scale out 。就是加一些服务器 就可以服务更多的用户
- 可抗压,系统在负载压力大的情况下,应该能自我保护,并且保证服务质量,不能因此崩溃掉。
- 稳定并且正确服务,这是一个通信系统,在任何时候都应该保证 2 个用户之间的通信是稳定并且正确的。举例来说 我和一个好友通信,无论对象处于什么样的环境,网络,在任何情况下,我们之间的通信消息都将按照原始顺序发送和接受,而不会出现重复,乱序,掉消息。
注意 因为服务器负载和网络的原因,消息延迟到达是允许的。
###1.2 本文及实验的局限性
局限性... 太多了,初始数据是随机的,数据集合大小是随机的,系统的架构是理想状况的,所以里面所有的结论都可以认为是不可信。
##2. 技术要求
- Linux 基本操作
- 熟悉高性能程序开发更佳
- TCP/IP 以及编程 至少得熟悉
- 系统设计 对计算机体系有一定了解
- Linux 常用工具熟练使用
- C/CPP 或者 java
- 一门脚本语言 python
- 常用的 Linux server
- 大型分布式系统管理 监控 调优能力
- 数据库使用和简单调优
- 海量服务器管理维护经验
##3. 环境准备 ###3.1 开发语言选择
我选择的语言是 Go, 版本 1.4/1.5 而不是 CPP 。主要的原因 在前文 c1000k practice guide 一文中,我认为 go 是很好的后台开发语言。 在此次测试中,我也期待使用 go 进行一次实践。 go 开发速度快,编译更是便捷,事实也证明的确很好用。
但是 GO 可能存在以下的问题
- 内存占用高, GO 使用的内存可控性不如 CPP 。不可控
- CPU 占用高。 我的 GO 语言代码水平偏低,学习时间大概也就 1-2 个月
- GC 的不确定性. 这是我最担心的, Go 作为使用 GC 的一种语言,是否能在高负载的情况下,依然很好的工作,是否会出现 FullGC 这样的灾难,还不得而知。虽然已经有小米利用 go 做了很多高性能的负载工作,但我认为最好的办法是做更多定量的测试,设定系统的阀值来避免。
###3.2 系统优化设置 我觉得以下几篇文章很好 可以参照进行设置,过程略
- 淘宝千石 高性能服务器架构设计和调优
- 锋寒 Linux TCP 队列相关参数的总结
- 前文 c1000k practice guide
###3.3 脚本语言 python
###3.4 数据库比较及选型 数据库可以分为关系型的 mysql/PG 和非关系型的 Redis /memcached
关系型的数据库 Mysql 和 pg 都能满足业务要求, mysql 我更熟悉,所以选 Mysql 非关系型数据库 Redis/ memcached
-
设计需要支持原子操作,也就是 CAS 操作
Redis 天生单线程,不存在这个问题,而 memcached 也满足这个要求。
-
内存情况
Redis 存在 fork 问题,对内存使用有要求 memcached 的缺点数据不能持久化,数据存在被淘汰的问题。 所以选 Redis
-
Mysql 和 Redis 之间进行对比
-
CAS mysql 支持 Redis 支持
-
吞吐量
mysql 强 Redis 很强
-
数据管理
mysql 可以有完整的数据类型,可以严格保证数据安全,分表机制比较复杂,对硬件要求高 Redis 没有完整的数据类型约束,完全靠客户程序自己保证,风险很大,对硬件要求低
-
数据估算
以最后 1000 万用户在线考虑 以每人有 50 条相互好友关系,每个用户 id 为 4 字节 1000*10*1000*50*4/1024/1024/1024 = 1.8G ,数据量并不大。同样情况下, Redis 操作更简单,可控性很强 -
所以 最终选 Redis
###3.5 缓存系统 暂无,
##4. 系统分析以及设计 ###4.1. 账号
首先考虑 一个用户的信息 简单的看 微信的界面,头像 昵称 微信号。没有类似 QQ 这样的数字 ID ,而且微信号可以不设置。我个人觉得从系统设计的角度看,微信自己也需要一个唯一的可以标识用户的标识。这个唯一的标记应该是什么?没有资料描述,我将它设计为一个整数了,我在系统里会用一个唯一的整数表述一个用户。
###4.2 账户间的好友关系
微信不存在单向好友,所以好友链就是 2 个数字 在用户 100 的关系链表里存在 100,200 这样一个记录,表明 用户 100 和用户 200 互为好友。则在用户 200 的关系链里也应该存在 200,100 这样一个记录。
###4.3. 多 IDC 以及账号区域问题 ####4.3.1 单 IDC
这个可以从腾讯大讲堂中看到一些端倪, QQ 也有这样的发展历程。最早所有的客户端是连到深圳一个 IDC 区域的,由单个点来完成。这样的好处是业务简单
但是单 IDC 也带来了很多问题
1.单点问题,如果过于集中接入,一旦出现节点故障,可能导致大量的不可服务。这就是所谓的鸡蛋在一个篮子里。 2.服务距离太远影响服务质量,设想一下,服务器在深圳,有一个用户,身在在东北,那么他每个消息都是要穿过整个中国大陆。要为他提供很好的服务的质量,代价会比为一位广州的用户大很多。距离的增加必然带来延迟上的增加。 3.单节点是中心节点 压力太大 继续做扩展很难,有技术和物理的上限。你见过 10 吨的卡车, 100 吨的卡车,但是你见过 1000 吨的卡车吗?扩展有难度
###4.3.2 多 IDC
虽然多年以前,我认为互联网是传统电信是不一样的东西,但是多年以后,我发现世界上很多东西都是类似的。电信的网络和 Internet 本身就是解决这个问题最好的例子。
你的电话是有区域的,也就是本地电话和国内长途和国际长途。你拨打的电话,绝大多数的电话是在本地的,有一些是国内的,更少一些是国际的。对绝大多数人来说本地的朋友要比远方的朋友多一些额。如果你和你的朋友都在一个 IDC ,那么肯定能更好的服务。( 8/2 原则,至少我如此认为)
所以在用户的属性里应该有一项很重要的属性 Region, Region 代表了你这个用户属于哪个 IDC ,类似于你电话区号,唯一的不同是,你的区号是可以变化的,只是这种变化不是很经常。平均每人每年的变化都不大的。并且这种改变不是由客户端发起,而是由服务器决定
多 IDC 的优势:
- 数据规模减小,每个 IDC 里的大小都更容易控制
- 系统更稳定,鸡蛋都放到了各个篮子。杭州被挖断光缆,不会让全中国都无法购物了
- 即使某个 IDC 故障,其他 IDC 不受影响
- IDC 相互支撑,当某些 IDC 出现故障,可以暂时把用户导流到其他 IDC ,比如滨海 IDC 被大爆炸影响后,迁徙所有用户,就是这样的例子。
多 IDC 好,但是 IDC 带来一系列问题,需要仔细考虑。本次实践没有做这些部分,这是个大工程。实践过程中,将所有的用户按照不同的号段,分配到不同的 Region, 模拟出多 IDC 的情况。而更普遍的情况,则是每个 Region 内用户的号段是不连续,并且离散的。这需要一个专门的服务来解决,我会慢慢实现。
###4.3.3 IDC 内部的用户如何分布到均匀地服务器上
假设有 IDC 内部有 1000 台服务器可以服务 1000 万用户,如何将用户均衡的分布到所有的用户上?
原始的办法有按照号段来区分,或者用户 id 取余来做,但是这样都存在数目不均衡的问题,一旦存在服务器宕机无法快速迁徙的问题。
可以利用一个一致性 hash 算法,将用户 id 映射成另一个 id 值,解决分布不集中的问题。然后做 sharding.如果用户数目足够多的话,应该非常均衡。(需要慢慢实践这一想法)
##4.4. 多设备消息的支持
这个主要依靠后面的设计
##5 核心服务器设计 以及通信保证
这部分是系统的核心,我是这样理解和设计它们的。
###5.1 背景和需求
首先看前提, 这是一个大型的系统,里面任何一个服务器都是不稳定的,可以崩溃的。原因可以是软件故障, bug ,操作系统,断电,操作失误。任何一个服务器的崩溃都是在预期之中的。(这又是云计算的一个典型特征)
然后看消息的传输, 这里的消息可以暂时看作用户之间的聊天消息
首先看丢失,一个消息在这样的系统里传输,是随时可能被丢弃的。虽然我们使用了 TCP 协议,但是需要途径多个服务器,而每个服务器的崩溃都是可以无法预测的,所以任何一个消息都可能丢弃。也就是传输不可靠
再看重传,因为整个系统的服务器是不稳定的,一条消息发出去以后,是否到达了目的服务器,这不可知,所以一定是存在重传机制的,那么对方在收到 2 个重复的消息,一定要能区别出来。一条消息重复收到 100 次 和处理 1 次没有区别。这也就是所谓的幂等性
最后是乱序,同样因为服务器是不稳定的,那么先传的消息,可能因为途经一个缓慢的服务器,会后到目的地,而后传的消息,也许会因为网络优化而先到目的地,这一点接受消息的服务器也需要能区分出来。
后面的贴不了了 请去 最大同性交友网站 看吧。
https://github.com/xiaojiaqi/fakewechat/
有问题 可以提,能回答我就回答一下
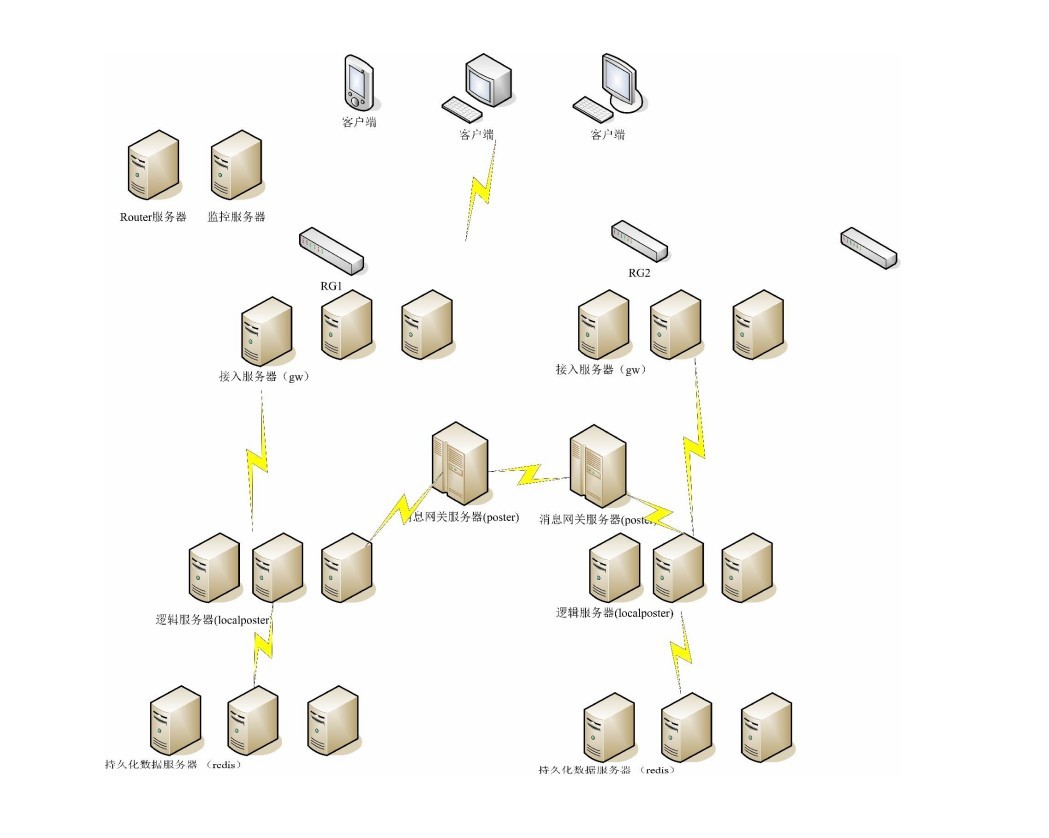
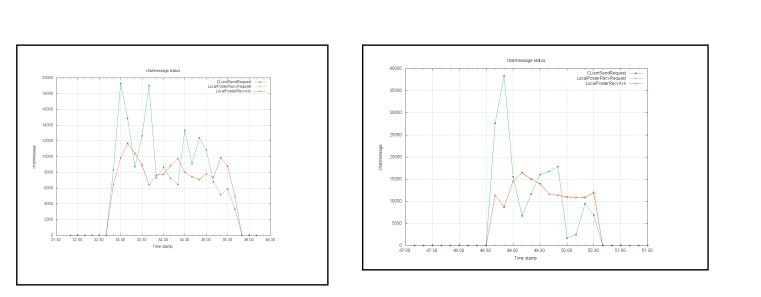
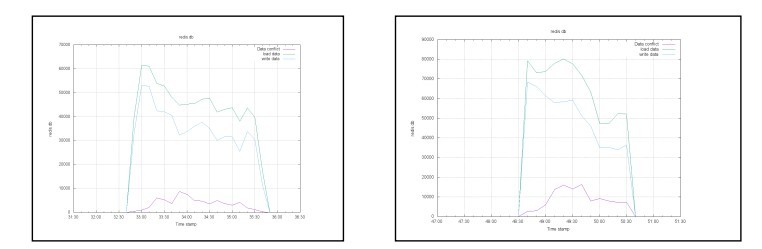
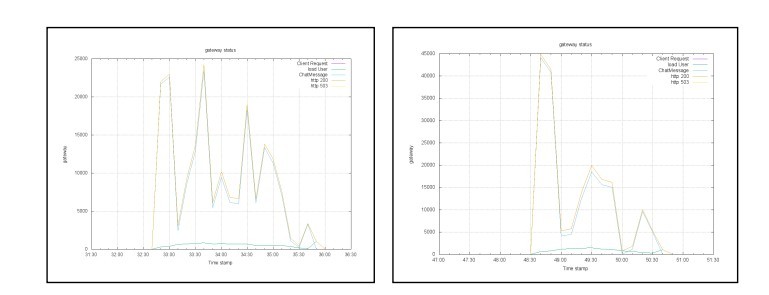
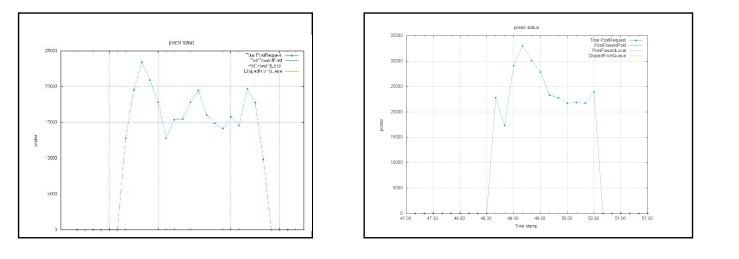 有一些提高,转发能力从2万到了3.5万
有一些提高,转发能力从2万到了3.5万








