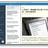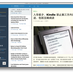
GAE/Java, 启用了并发请求几天, 一些结果分享:
之前instance经常跑到5以上, 启用并发请求后, 极少跑到3, 基本都在1, 偶尔跑到2.
跑到3是大量的突发请求, 跑到2倒不一定是负载大
没做其它优化, 只是在 Application Settings 中, 把Min Pending Latency 修改为3秒. 第一天Min Pending Latency为自动的时候, 跑到2会更频繁一些.
***启用多线程后, 内存并没有明显增加
***Python运行内存比Java小很多 (Java经常跑到90M以上), 并且加载速度快, 所以Python 2.7以后, 一个instance的响应能力提高可能会比Java高更多
=============
虽然GAE计价时CPU按照1G来计算, 但是有人测试过, 实际CPU相当于1.8G. 内存据称是200M, 但是跑到300M才会被结束.
对比Windows Azure, Amazon AWS, 同价位下GAE内存明显小很多, 并且没有不同档次可选择. 但GAE是运行内存.
GAE的instance数量是动态的, 这个是云计算的最大优点. 试想一下, 一个应用, 如果白天高峰时段需要很多instance, 而晚上1个instance就可以满足需要, 用Azure或AWS目前只能创建最大计算能力的instance, 算下来可能还是GAE划算.
之前instance经常跑到5以上, 启用并发请求后, 极少跑到3, 基本都在1, 偶尔跑到2.
跑到3是大量的突发请求, 跑到2倒不一定是负载大
没做其它优化, 只是在 Application Settings 中, 把Min Pending Latency 修改为3秒. 第一天Min Pending Latency为自动的时候, 跑到2会更频繁一些.
***启用多线程后, 内存并没有明显增加
***Python运行内存比Java小很多 (Java经常跑到90M以上), 并且加载速度快, 所以Python 2.7以后, 一个instance的响应能力提高可能会比Java高更多
=============
虽然GAE计价时CPU按照1G来计算, 但是有人测试过, 实际CPU相当于1.8G. 内存据称是200M, 但是跑到300M才会被结束.
对比Windows Azure, Amazon AWS, 同价位下GAE内存明显小很多, 并且没有不同档次可选择. 但GAE是运行内存.
GAE的instance数量是动态的, 这个是云计算的最大优点. 试想一下, 一个应用, 如果白天高峰时段需要很多instance, 而晚上1个instance就可以满足需要, 用Azure或AWS目前只能创建最大计算能力的instance, 算下来可能还是GAE划算.