
这是一个创建于 321 天前的主题,其中的信息可能已经有所发展或是发生改变。
写周刊两个月多了,也来到了第 7 期,除了跨年那周给自己放了一次假,已经能做到每周日准时发布了。再次发在 v2 ,请各位大佬指教。
生成式 AI 在软件开发中的变革性力量
Uber 在内部搞了一个 Hackathon ,让各个团队尝试了一些将生成式 AI 集成进工作流程的方式。
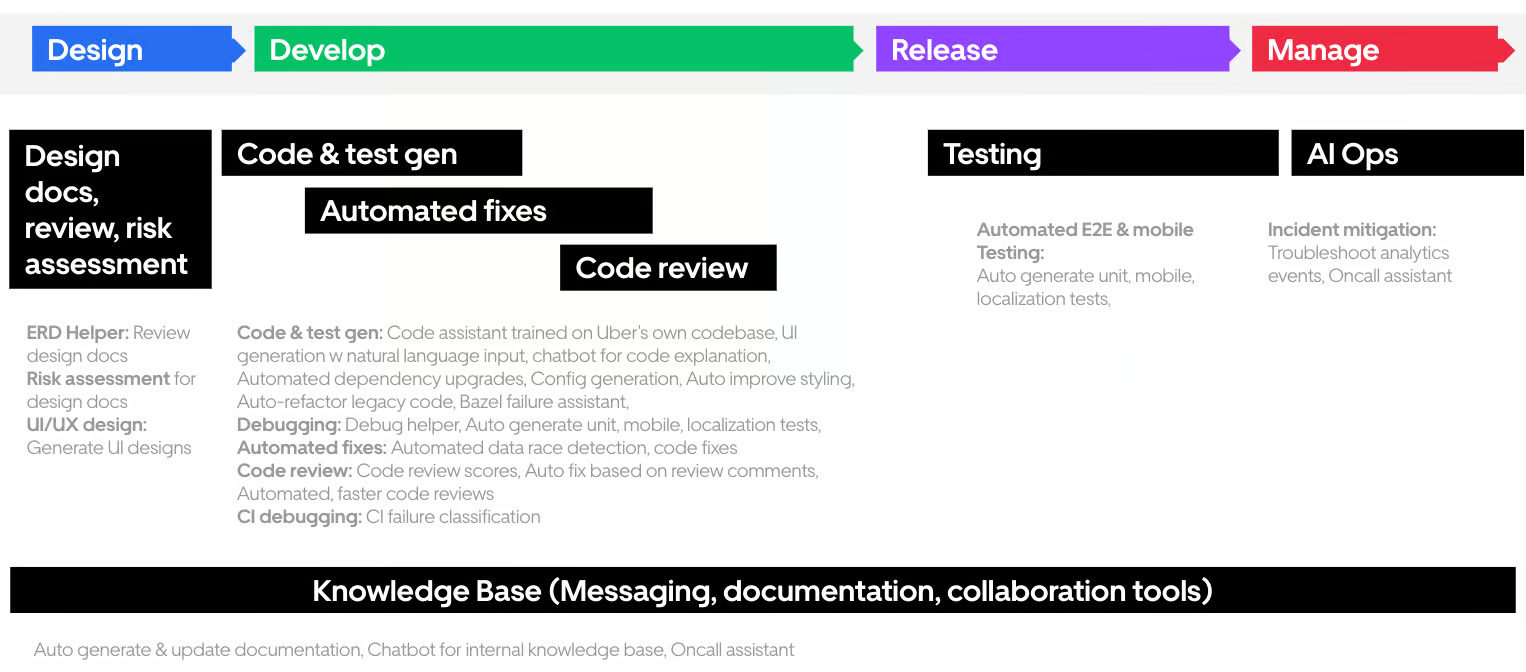
他们主要尝试了以下用途:
- 设计文档,审校和风险评估
-
代码和测试生成
- 解释现有代码
- 生成 UI 代码
- 自动化重构和集中迁移
-
自动化修复
- 评审及优化现有代码
- 测试生成
- 代码调试
- 代码评审( Code Review )
- 错误分类
- 本地化(翻译)
- 知识库
同时,他们也提出生成式 AI 有两个风险,一是输出内容的质量,二是决策的可解释性。
中文大模型基准测评 2023 年度报告
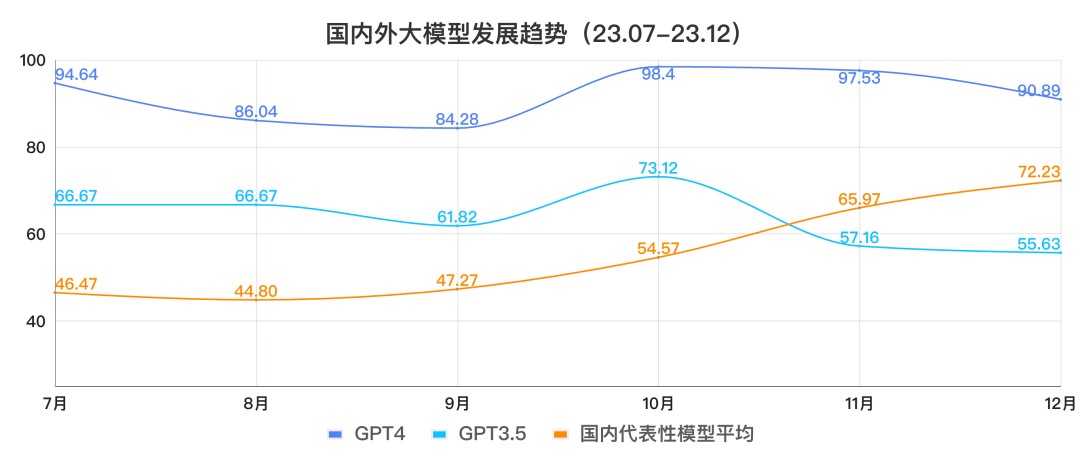
SuperCLUE 团队出品的国内大模型基准测评,采用了多维度、多视角的综合性测评方案,包含简答题、客观题等,对国内外有代表性的 26 个大模型进行了测评。

值得注意的是,这个测评标准,使得大模型的具体表现可以量化。之前一直有很多讨论,说 GPT 某个版本或者从某时间开始变笨了等等,终于有量化的结果来支持这种言论了。
「缺省」这个词是如何从英语 "Default" 翻译过来的?
我一直觉得 “Default” 翻译成“默认值”是比较合适的,这个回答提供了一个新的角度:预设值( preset value )和缺省/除错/补缺值( default value )。预设和缺省是有区别的,预设指的是预先设置一个值,后面没人设置了,就默认这个值,是事先设置的;而缺省指的是,没有预先设置一个值,让用户填空,用户操作失误没有填或填错了,补上一个值,是事后弥补的。因此预设值和缺省值都是“默认值”。
后面也有很多回答,各有千秋,但是总的来说我比较认同这个高赞答案。
篇幅有限,全文见: https://ameow.xyz/archives/weekly-007
以下是阅读渠道,欢迎各位关注。
博客:阿猫的博客-猫鱼周刊
RSS:猫鱼周刊
邮件订阅:猫鱼周刊
目前尚无回复